Introduction
We migrate code out of MF to Azure.
Tool we use produces plain good functionally equivalent C# code.
But it turns it's not enough!
So, what's the problem?
Converted code is very slow, especially for batch processing,
where MF completes job, say in 30 minutes, while converted code
finishes in 8 hours.
At this point usually someone appears and whispers in the ear:
Look, those old technologies are proven by the time. It worth to stick to old good Cobol, or better to Assembler if you want to do the real thing.
We're curious though: why is there a difference?
Turns out the issue lies in differences of network topology between MF and Azure solutions.
On MF all programs, database and file storage virtually sit in a single box, thus network latency is negligible.
It's rather usual to see chatty SQL programs on MF that are doing a lot of small SQL queries.
In Azure - programs, database, file storage are different services most certainly sitting in different phisical boxes.
You should be thankfull if they are co-located in a single datacenter.
So, network latency immediately becomes a factor.
Even if it just adds 1 millisecond per SQL roundtrip, it adds up in loops, and turns in the showstopper.
There is no easy workaround on the hardware level.
People advice to write programs differently: "Tune applications and databases for performance in Azure SQL Database".
That's a good advice for a new development but discouraging for migration done by a tool.
So, what is the way forward?
Well, there is one. While accepting weak sides of Azure we can exploit its strong sides.
Parallel refactoring
Before continuing let's consider a code demoing the problem:
public void CreateReport(StringWriter writer)
{
var index = 0;
foreach(var transaction in dataService.
GetTransactions().
OrderBy(item => (item.At, item.SourceAccountId)))
{
var sourceAccount = dataService.GetAccount(transaction.SourceAccountId);
var targetAccount = transaction.TargetAccountId != null ?
dataService.GetAccount(transaction.TargetAccountId) : null;
++index;
if (index % 100 == 0)
{
Console.WriteLine(index);
}
writer.WriteLine($"{index},{transaction.Id},{
transaction.At},{transaction.Type},{transaction.Amount},{
transaction.SourceAccountId},{sourceAccount?.Name},{
transaction.TargetAccountId},{targetAccount?.Name}");
}
}
This cycle queries transactions, along with two more small queries to get source and target accounts for each transaction. Results are printed into a report.
If we assume query latency just 1 millisecond, and try to run such code for 100K transactions we easily come to 200+ seconds of execution.
Reality turns to be much worse. Program spends most of its lifecycle waiting for database results, and iterations don't advance until all work of previous iterations is complete.
We could do better even without trying to rewrite all code!
Let's articulate our goals:
- To make code fast.
- To leave code recognizable.
The idea is to form two processing pipelines:
- (a) one that processes data in parallel out of order;
- (b) other that processes data serially, in original order;
Each pipeline may post sub-tasks to the other, so (a) runs its tasks in parallel unordered, while (b) runs its tasks as if everything was running serially.
So, parallel plan would be like this:
- Queue parallel sub-tasks (a) for each transaction.
- Parallel sub-task in (a) reads source and target accounts, and queues serial sub-task (b) passing transaction and accounts.
- Serial sub-task (b) increments index, and writes report record.
- Wait for all tasks to complete.
To reduce burden of task piplelines we use Dataflow (Task Parallel Library), and encapsulate everything in a small wrapper.
Consider refactored code:
public void CreateReport(StringWriter writer)
{
using var parallel = new Parallel(options.Value.Parallelism);
var index = 0;
parallel.ForEachAsync(
dataService.
GetTransactions().
OrderBy(item => (item.At, item.SourceAccountId)),
transaction =>
{
var sourceAccount = dataService.GetAccount(transaction.SourceAccountId);
var targetAccount = transaction.TargetAccountId != null ?
dataService.GetAccount(transaction.TargetAccountId) : null;
parallel.PostSync(
(transaction, sourceAccount, targetAccount),
data =>
{
var (transaction, sourceAccount, targetAccount) = data;
++index;
if (index % 100 == 0)
{
Console.WriteLine(index);
}
writer.WriteLine($"{index},{transaction.Id},{
transaction.At},{transaction.Type},{transaction.Amount},{
transaction.SourceAccountId},{sourceAccount?.Name},{
transaction.TargetAccountId},{targetAccount?.Name}");
});
});
}
Consider ⬅️ points:
- We create
Parallel utility class passing degree of parallelism requested.
- We iterate transactions using
parallel.ForEachAsync() that queues parallel sub-tasks for each transaction, and then waits until all tasks are complete.
- Each parallel sub-task recieves a transaction. It may be called from a different thread.
- Having recieved required accounts we queue a sub-task for synchronous execution using
parallel.PostSync(), and
- Pass there data collected in parallel sub-task: transaction and accounts.
- We deconstruct data passed into variables, and then proceed with serial logic.
What we achieve with this refactoring:
- Top level query that brings transactions is done and iterated serially.
- But each iteration body is run in parallel. By default we set it up to allow up to 100 parallel executions.
All those parallel sub-task do not wait on each other so their waitings do not add up.
- Sync sub-tasks are queued and executed in order of their serial appearance, so increments and report records are not a subject of race conditions, nor a subject of reordering of output records.
We think that such refactored code is still recognizible.
As for performance this is what log shows:
Serial test
100
...
Execution time: 00:01:33.8152540
Parallel test
100
...
Execution time: 00:00:05.8705468
Reference
Please take a look at project to understand implementation details, and in particular
Parallel class implementing API to post parallel and serial tasks, run cycles and some more.
Please continue reading on GitHub.
As we wrote some time ago, we started to use AI and ML APIs in our applications, but this time we've tried to use Bing chat as a tool.
The initial task was to collect sequences of integer numbers and return a list of pairs integers where the first number is a range's start and the second one is a count of values in the range. For example, for sequence 1, 2, 3, 5, 8, 9 we'd like to get the following results:
1, 3
5, 1
8, 2
We both started to solve this issue. My brother started to play with SSMS using his deep knowledges in SQL and analytic functions, whereas me started to play with Bing chat. Looking ahead, I can state that we both solved the issue using almost the same SQL statement almost in the same time.
Here are my prompts and Bing's answers:
- Prompt:
-
Act as database analyst and software engineer. Given the table (T) with a numeric field (N), which values are orderd ranges of integers. In a range each next value is greater than previous one on 1. When value differs from the previous one more than on 1 then in belongs to another range. Generate select statement that returns rows with two fields. The first field (R) is a number from which a range starts and the second field (C) is count elements of that range:
- Answer:
-
Sure, I can help with that. Here's a SQL query that should do the trick. This query uses a self-join to
identify the start of each range, and then groups by the start of the range to count the number of elements.
```sql
SELECT
start_of_range AS R,
COUNT(*) AS C
FROM (
SELECT
N,
N - ROW_NUMBER() OVER (ORDER BY N) AS start_of_range
FROM T
) subquery
GROUP BY start_of_range
ORDER BY start_of_range;
```
In this query, `start_of_range` is calculated as the difference between the current value of `N` and its row
number (when ordered by `N`). This difference will be the same for all `N` in the same range. Then we group
by `start_of_range` to get the count of elements in each range. The outer query selects the start of each
range (`R`) and the count of elements in that range (`C`).
-
Me, scratching the head, hmmm...
-
Question:
-
This is a bit incorrect SQL select. For example for values 1, 2, 3, 5, 8, 9 I'd like to get the following results:
1, 3
5, 1
8, 2
What a SQL select shall I use to get such results?
- Answer:
-
I apologize for the confusion earlier. You're right, the previous query doesn't handle the scenario you've described correctly.
Here's a corrected SQL query that should give you the desired output. This query uses a window function to compare each row with the previous one and identify the start of a new range. Then it groups by the start of the range to count the elements.
```sql
WITH ranges AS (
SELECT
N,
CASE
WHEN N - LAG(N, 1, N) OVER (ORDER BY N) > 1 THEN 1
ELSE 0
END AS is_start_of_range
FROM T
),
range_groups AS (
SELECT
N,
SUM(is_start_of_range) OVER (ORDER BY N) AS range_group
FROM ranges
)
SELECT
MIN(N) AS R,
COUNT(*) AS C
FROM range_groups
GROUP BY range_group
ORDER BY R;
```
In this query, `is_start_of_range` is a flag that indicates the start of a new range (when the difference between the current and previous `N` is more than 1). `range_group` is a running total of `is_start_of_range` that serves as a unique identifier for each range. The outer query then groups by `range_group` to get the start (`R`) and count (`C`) of each range. I hope this helps! Let me know if you have any other questions.
That answer more satisfied me, and I've checked the following example:
with T as
(
select 10 N
union all
select 11 N
union all
select 30 N
union all
select 31 N
union all
select 32 N
union all
select 50 N
union all
select 80 N
union all
select 81 N
union all
select 82 N
union all
select 83 N
union all
select 90 N
),
ranges AS (
SELECT
N,
CASE
WHEN N - LAG(N, 1, N) OVER (ORDER BY N) > 1 THEN 1
ELSE 0
END AS is_start_of_range
FROM T
),
range_groups AS (
SELECT
N,
SUM(is_start_of_range) OVER (ORDER BY N) AS range_group
FROM ranges
)
SELECT
MIN(N) AS R,
COUNT(*) AS C
FROM range_groups
GROUP BY range_group
ORDER BY R;
The result was:
R C
------------
10 2
30 3
50 1
80 4
90 1
Conclusion:
Nowdays, using AI as a tool, you may improve your performance to the expert level and, may be, study something new...
P.S. Don't fool youself that AI can replace a developer (see the first answer of the chat), but together they can be much stornger than separatelly.
P.P.S. Another interesting solution gave us our colleague. She used an additional field to avoid using analytics function, and she reached the same result:
with T as
(
select 10 ID, 1 N
union all
select 11 ID, 1 N
union all
select 30 ID, 1 N
union all
select 31 ID, 1 N
union all
select 32 ID, 1 N
union all
select 50 ID, 1 N
union all
select 80 ID, 1 N
union all
select 81 ID, 1 N
union all
select 82 ID, 1 N
union all
select 83 ID, 1 N
union all
select 90 ID, 1 N
),
Groups AS (
SELECT
ID,
N,
ROW_NUMBER() OVER (ORDER BY ID) - ID AS GroupNumber
FROM
T
)
SELECT
MIN(ID) AS R,
SUM(N) AS C
FROM
Groups
GROUP BY
GroupNumber
ORDER BY
StartID;
Earlier we wrote that recently we've gotten few tasks related to Machine Learning.
The prerequisites to such task is to collect and prepare the input data.
Usually the required data is scattered across public sites, some of them are in plain text format (or close to it),
but others are accessible as output of public applications. To obtain the required data for such sites
you have to navigate thourgh pages, which often requires keeping state between navigations.
In order to implement this task you need some kind of crawler/scraper of the websites.
Fortunately, there are a lot of frameworks, libraries and tools in C# (and in other languages too) that allow to do this (visit this or this site to see most popular of them), for example:
- ScrapySharp
- ABot
- HtmlAgilityPack
- DotnetSpider
There are pros and cons of using these libraries. Most crucial cons is a lack of support of rich UI based on heavy client-side scripts and client-side state support.
Since not all such libraries implement fully browser emulation and even more, some of them do not support Javascript execution.
So, they suit for gathering information from simple web pages, but no library allows to easy navigate to some page of a web application
that keeps rich client-side state. Even best of them, like ScrapySharp, require heavy programming to achieve the result.
Then, suddenly, we've recalled that already for several years we're using Selenium and web drivers to automate web tests for AngularJS/Angular projects.
After short discussion we came to conclusion that there is no big difference between testing web application and collecting data, since one of testing stages is collecting of actual results (data)
from the tested page, and usually our tests consist of chains of actions performed on consequently visited pages.
This way we came to idea to use WebDriver API implemented by Selenium project.
There are implementations of this API in different languages, and in C# too.
Using WebDriver we easily implement cumbersome navigation of a complex web application and can collect required data. Moreover, it allows to run WebDriver in screenless mode.
Some of its features allow to create a snapshots of virtual screen and store HTML sources that would resulted of Javascript execution. These features are very
useful during run-time troubleshooting. To create a complex web application navigation we need only a bit more knowledge than usual web application's user - we need
to identify somehow pages' elements for example by CSS selectors or by id of HTML elements (as we do this for tests). All the rest, like coockies, view state (if any),
value of hidden fields, some Javascript events will be transparent in this case.
Although one may say that approach with Selenium is rather fat, it's ought to mention that it is rather scalable.
You may either to run several threads with different WebDriver instances in each thread or run several processes simultaneously.
However, beside pros there are cons in the solution with Selenium. They will appear when you'll decide to publish it, e.g. to Azure environment.
Take a note that approach with Selenium requires a browser on the server, there is also a problem with Azure itself, as it's Microsoft's platform
and Selenium is a product of their main competitor Google... So, some issues aren't techincals. The only possible solution is to use PaaS approach
instead of SaaS, but in this case you have to support everything by yourself...
The other problem is that if your application will implement rather aggressive crawling, so either servers where you gather data or your own host might ban it.
So, be gentle, play nice, and implement delays between requests.
Also, take into account that when you're implementing any crawler some problems may appear on law level, since not all web sites allow pull anything you want.
Many sites use terms & conditions that defines rules for the site users (that you cralwer should follow to), otherwise legal actions may
be used against them (or their owners in case of crawler). There is
very interesting article that describes many
pitfalls when you implement your own crawler.
To summarize everything we told early, the Selenium project could be used in many scenarios, and one of them is to create a powerful crawler.
 Eventually we've started to deal with tasks that required machine learning. Thus, the good tutorial for ML.NET was required and we had found this one that goes along with good simple codesamples. Thanks to Jeff Prosise. Hope this may be helpfull to you too. Eventually we've started to deal with tasks that required machine learning. Thus, the good tutorial for ML.NET was required and we had found this one that goes along with good simple codesamples. Thanks to Jeff Prosise. Hope this may be helpfull to you too.
Recently our colleague turned to us and asked to help to deal with some complex query.
It has turned out that the complex part was to understand what he wants to achieve.
After listening to him we have forumulated the task in our words and have confirmed that that is what he wants.
So, that's the task in our formulation:
- Assume you have events.
- Each event acts upon one or more accounts.
- Find all events that act on the same set of accounts.
- Note we deal with mutiple millions of events and accounts.
Data is defined like this:
create table dbo.Event
(
EventID bigint not null,
AccountID varchar(18) not null,
primary key(EventID, AccountID)
);
Requested query turned out to be very simple, yet, not as simple as one would think to account big amout of data:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
count(*) Items,
checksum_agg(checksum(AccountID)) Hash
from
D
group by
EventID
)
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items = S2.Items and
S1.Hash = S2.Hash and
not exists
(
select AccountID from D where EventID = S1.EventID
except
select AccountID from D where EventID = S2.EventID
);
The idea is to:
- calculate a hash derived from list of accounts for each group;
- join groups with the same hash;
- verify that matched groups fit perfectly.
Even simpler solution that does not use hashes is not scaleable, as it's performance is slower than O(N^2), where N - is a number of events. It has unacceptable time with N ~1e4, nothing to say about N ~1e7.
At this point our colleague was already satisfied, as he got result in couple of minutes for a task that he could not even formalize as SQL.
But we felt it could be even better.
We looked at statistics:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
count(*) Items
from
D
group by
EventID
)
select
Items, count(*) EventCount
from
S
group by
Items
order by
EventCount desc;
and have seen that most of the events, about 90%, deal with single account,
and all other with two and more (some of them act upon big number of accounts).
The nature of the dataset gave us a hint of more verbose but more fast query:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
min(AccountID) AccountID,
count(*) Items,
checksum_agg(checksum(AccountID)) Hash
from
D
group by
EventID
)
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items = 1 and
S2.Items = 1 and
S1.AccountID = S2.AccountID
union all
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items > 1 and
S2.Items > 1 and
S1.Items = S2.Items and
S1.Hash = S2.Hash and
not exists
(
select AccountID from D where EventID = S1.EventID
except
select AccountID from D where EventID = S2.EventID
);
This query produced results in twenty seconds instead of couple of minutes for a dataset with ~1e7 rows.
Not sure what is use of our Xslt Graph exercises but what we are sure with is that it stresses different parts of Saxon Xslt engine and helps to find and resolve different bugs.
While implementing biconnected components algorithm we incidently run into internal error with Saxon 10.1 with rather simple xslt:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:array="http://www.w3.org/2005/xpath-functions/array"
exclude-result-prefixes="xs array">
<xsl:template match="/">
<xsl:sequence select="
array:fold-left
(
[8, 9],
(),
function($first as item(), $second as item())
{
min(($first, $second))
}
)"/>
</xsl:template>
</xsl:stylesheet>
More detail can be found at Saxon's issue tracker: Bug #4578: NullPointerException when array:fold-left|right $zero argument is an empty sequence.
Bug is promptly resolved.
People compare these two technologies, and it seems an established fact is that Angular is evolutionally more advanced framework. We're not going to contradict, contrary, we agree with it, but it's better for an opinion to be grounded on facts that one can evaluate and verify.
Fortunately we got a chance to make such a comparison.
We support conversions of Cool:GEN (a legacy CASE tool with roots in 80th) to java or C#. In its time Cool:GEN allowed to greatly automate enterprise development using Mainframes as a server side and Mainframe terminals or Win32 GUIs as clients.
The legacy of this tool are probably hundreds of business and database models, milions of programs generated on COBOL on Mainframes and on C or Java on Windows and Linux. All this runs to this time in many econimic sectors.
Usually the client is some enterprise that invested a lot into design, development and support of their business model using Cool:GEN but now most such clients a trying not to lose this legacy but to convert it into something that goes in parallel with todays technologies.
As original technology is sound, so it is possible to map it to todays Java or C# on server, REST or SOAP as a transport, and Angular, AngularJS or some other on client. Such automatic conversion is an essense of our conversions efforts.
To understand a scope consider a typical enterprise client that has 2-3 thousand windows that are backed by 20-30 thousand programs.
Now, consider that the conversion is done. On output among other things we produce a clean java or C# web application with REST and SOAP interface, and Angular or AngularJS web client that encapsulates those 2-3 thousand windows.
Each window definition is rather small 5-10 KB in html form, but whole mass of windows takes 10-30 MB, which is not small any more.
For AngularJS we generate just those html templates, but for Angular we need to generate separate components for each window that includes typescript class, template and style.
While amout of generated resource for AngularJS stays in those 10-30 MB, generated Angular takes at least 5-10 MB more.
The next step is build.
AngularJS builds distribution that includes all used libraries and a set of templates, and it takes something like a minute from the CPU. Produced output is about 300 KB minified script and those 10-30 MB of templates (multiple files with 5-10 KB each one).
Angular (here we talk about version 9) builds distribution that includes all used libraries and a set of compiled components that are to be loaded lazily on demand. Without of the both angular builder that performs tree shaking build takes days. With tree shaking off it takes 40 minutes. This is the first notable difference. Produced output for ES2015 (latest javascript) is about 1 MB, and 15-100 KB per each compiled component. This is the second notable difference that already impacts end user rather than developer.
The third difference is in the end user experience. Though we have built equalvalent Angular and AngularJS frontend we observe load time of angular is higher. This cannot only be ascribed to bigger file sizes. It seems internal initialization also takes more time for Angular.
So, our experience in this particular test shows that Angular has more room to improve. In particular: compile time, bundle size, runtime speed and simplicity of dynamic loading (we have strong cases when template compilation is not the best approach).
We were asked to help with search service in one enterprise. We were told that their SharePoint portal does not serve their need. Main complaints were about the quality of search results.
They have decided to implement external index of SharePoint content, using Elastic, and expose custom search API within the enterprise.
We questioned their conclusions, asked why did they think Elastic will give much better results, asked did they try to figure out why SharePoint give no desired results.
Answers did not convince us though we have joined the project.
What do you think?
Elastic did not help at all though they hoped very much that its query language will help to rank results in a way that matched documents will be found.
After all they thought it was a problem of ranking of results.
Here we have started our analysis. We took a specific document that must be found but is never returned from search.
It turned to be well known problem, at least we dealt with closely related one in the past. There are two ingredients here:
- documents that have low chances to be found are PDFs;
- we live in Israel, so most texts are Hebrew, which means words are written from right to left, while some other texts from left to right. See Bi-directional text.
Traditionally PDF documents are provided in a way that only distantly resembles logical structure of original content. E.g., paragraphs of texts are often represented as unrelated runs of text lines, or as set of text runs representing single words, or independant characters. No need to say that additional complication comes from that Hebrew text are often represented visually (from left to right, as if "hello" would be stored as "olleh" and would be just printed from right to left). Another common feature of PDF are custom fonts with uncanonical mappings, or images with glyphs of letters.
You can implement these tricks in other document formats but for some reason PDF is only format we have seen that regularly and intensively uses these techniques.
At this point we have realized that it's not a fault of a search engine to find the document but the feature of the PDF to expose its text to a crawler in a form that cannot be used for search.
In fact, PDF cannot search by itself in such documents, as when you try to find some text in the document opened in a pdf viewer, that you clearly see in the document, you often find nothing.
A question. What should you do in this case when no any PDF text extractor can give you correct text but text is there when you looking at document in a pdf viewer?
We decided it's time to go in the direction of image recognition. Thankfully, nowdays it's a matter of available processing resources.
Our goal was:
- Have images of each PDF page. This task is immediately solved with Apache PDFBox (A Java PDF Library) - it's time to say this is java project.
- Run Optical Character Recognition (OCR) over images, and get extracted texts. This is perfectly done by tesseract-ocr/tesseract, and thankfully to its java wrapper bytedeco/javacpp-presets we can immediately call this C++ API from java.
The only small nuisance of tesseract is that it does not expose table recognition info, but we can easily overcome it (we solved this task in the past), as along with each text run tesseract exposes its position.
What are results of the run of such program?
- Full success! It works with high quality of recognition. Indeed, there is no any physical noise that impacts quality.
- Slow speed - up to several seconds per recognition per page.
- Scalable solution. Slow speed can be compensated by almost unlimited theoretical scalability.
So, what is the lesson we have taked from this experience?
Well, you should question yourself, test and verify ideas on the ground before building any theories that will lead you in completely wrong direction. After all people started to realize there was no need to claim on SharePoint, to throw it, and to spend great deal of time and money just to prove that the problem is in the different place.
A sample source code can be found at App.java
In some code we needed to perform a circular shift of a part of array, like on the following picture:

It's clear what to do, especially in case of one element shift but think about "optimal" algorithm that does minimal number of data movemenents.
Here is what we have came up with in C#: algorithm doing single pass over data.
/// <summary>
/// <para>
/// Moves content of list within open range <code>[start, end)</code>.
/// <code>to</code> should belong to that range.
/// </para>
/// <para>
/// <code>list[start + (to - start + i) mod (end - start)] =
/// list[start + i]</code>,
/// where i in range<code>[0, end - start)</ code >.
/// </para>
/// </summary>
/// <typeparam name="T">An element type.</typeparam>
/// <param name="list">A list to move data withing.</param>
/// <param name="start">Start position, including.</param>
/// <param name="end">End position, not incuding.</param>
/// <param name="to">Target position.</param>
public static void CircularMove<T>(IList<T> list, int start, int end, int to)
{
var size = end - start;
var step = to - start;
var anchor = start;
var pos = start;
var item = list[pos];
for(int i = 0; i < size; ++i)
{
pos += step;
if (pos >= end)
{
pos -= size;
}
var next = list[pos];
list[pos] = item;
item = next;
if (pos == anchor)
{
pos = ++anchor;
if (pos >= end)
{
break;
}
item = list[pos];
}
}
}
J2SE has become sole large that its different parts don't play well.
That is pitty but nothing to do. There is probably a lack of resources in Oracle to fill gaps.
So, to the point.
There is relatively new API to work with time defined in: package java.time. There is older API JAXB to serialize and deserialize beans to and from XML (and often to JSON). To JAXB viable, it should be able to deal with basic primitive types. The problem is that JAXB does not handle LocalDate, LocalTime, LocalDateTime, and ZonedDateTime out of the box.
We do understand that:
- JAXB is older and java.time is newer API; and that
- JAXB has no built-in plugin to handle new types.
But this does not help, and we should define/redefine serialization adapters using some drop in code or third party libraries. Here are these convenience adapters:
LocalDateAdapter.java
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.ZonedDateTime;
import javax.xml.bind.annotation.adapters.XmlAdapter;
/**
* An adapter for the bean properties of {@link LocalDate} type.
*/
public class LocalDateAdapter extends XmlAdapter<String, LocalDate>
{
/**
* Converts {@link LocalDate} into a string value.
* @param value a value to convert. Can be null.
* @return a string value.
*/
@Override
public String marshal(LocalDate value)
throws Exception
{
return value == null ? null : value.toString();
}
/**
* Converts a string value into a {@link LocalDate}
* instance.
* @param value a value to convert. Can be null.
* @return a {@link LocalDate} instance.
*/
@Override
public LocalDate unmarshal(String value)
throws Exception
{
if (value == null)
{
return null;
}
int p = value.indexOf('T');
if (p < 0)
{
return LocalDate.parse(value);
}
while(++p < value.length())
{
switch(value.charAt(p))
{
case '+':
case '-':
case 'Z':
{
return ZonedDateTime.parse(value).toLocalDate();
}
}
}
return LocalDateTime.parse(value).toLocalDate();
}
}
LocalDateTimeAdapter.java
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.time.ZonedDateTime;
import javax.xml.bind.annotation.adapters.XmlAdapter;
/**
* An adapter for the bean properties of {@link LocalDateTime} type.
*/
public class LocalDateTimeAdapter extends XmlAdapter<String, LocalDateTime>
{
/**
* Converts {@link LocalDateTime} into a string value.
* @param value a value to convert. Can be null.
* @return a string value.
*/
@Override
public String marshal(LocalDateTime value)
throws Exception
{
return value == null ? null : value.toString();
}
/**
* Converts a string value into a {@link LocalDateTime} instance.
* @param value a value to convert. Can be null.
* @return a {@link LocalDateTime} instance.
*/
@Override
public LocalDateTime unmarshal(String value)
throws Exception
{
if (value == null)
{
return null;
}
int p = value.indexOf('T');
if (p < 0)
{
return LocalDateTime.of(LocalDate.parse(value), LocalTime.MIN);
}
while(++p < value.length())
{
switch(value.charAt(p))
{
case '+':
case '-':
case 'Z':
{
return ZonedDateTime.parse(value).toLocalDateTime();
}
}
}
return LocalDateTime.parse(value);
}
}
LocalTimeAdapter.java
import java.time.LocalDate;import java.time.LocalTime;
import javax.xml.bind.annotation.adapters.XmlAdapter;
/**
* An adapter for the bean properties of {@link LocalTime} type.
*/
public class LocalTimeAdapter extends XmlAdapter<String, LocalTime>
{
/**
* Converts {@link LocalTime} into string value.
* @param value a value to convert. Can be null.
* @return a string value
*/
@Override
public String marshal(LocalTime value)
throws Exception
{
return value == null ? null : value.toString();
}
/**
* Converts a string value into a {@link LocalTime} instance.
* @param value a value to convert. Can be null.
* @return a {@link LocalTime} instance.
*/
@Override
public LocalTime unmarshal(String value)
throws Exception
{
return value == null ? null : LocalTime.parse(value);
}
}
To make them work either field/properties or package should be annotated with JAXB xml adapters.
The simplest way is to annotate it on package level like this:
package-info.java
@XmlJavaTypeAdapters(
{
@XmlJavaTypeAdapter(value = LocalDateAdapter.class, type = LocalDate.class),
@XmlJavaTypeAdapter(value = LocalTimeAdapter.class, type = LocalTime.class),
@XmlJavaTypeAdapter(value = LocalDateTimeAdapter.class, type = LocalDateTime.class)
})
package com.nesterovskyBros.demo.entities;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import javax.xml.bind.annotation.adapters.XmlJavaTypeAdapter;
import javax.xml.bind.annotation.adapters.XmlJavaTypeAdapters;
We've run into following java function that models some variation of NULL arithmetic:
public static Long add(Long value1, Long value2)
{
return value1 == null ? value2 : value2 == null ? value1 : value1 + value2;
}
When this function runs the outcome is different from what we have expected.
Here is a quiz:
What is outcome of add(1, 2):
3;null;- other.
What is outcome of add(3, null):
3;null;- other.
What is outcome of add(null, 4):
null;4;- other.
What is outcome of add(null, null):
null;0;- other.
Our assumptions were:
add(1, 2) == 3;add(3, null) == 3;add(null, 4) == 4;add(null, null) == null;
Java works differently:
add(1, 2) == 3;add(3, null) throws NullPointerException;add(null, 4) throws NullPointerException;add(null, null) throws NullPointerException;
The problem is with compile time type of ternary ?: operator. Compiler decides it's long, while we intuitively expected Long. Java casts null to long (which results into NPE), and then to Long.
Correct code would be:
public static Long add(Long value1, Long value2)
{
if (value1 == null)
{
return value2;
}
else if (value2 == null)
{
return value;
}
else
{
return value1 + value2;
}
}
This version does not cast anything to long, and works as we originally expected.
Honestly, we're a bit anexious about this subtle difference of if-then-else and ?: operator.
Our recent task required us to find all sets of not intersecting rectangles for a rectangle list.
At first glance it did not look like a trivial task. Just consider that for a list of N rectangles you can form
2^N different subsets. So, even result list, theoretically, can be enormous.
Fortunately, we knew that our result will be manageable in size. But nevertheless, suppose you have a list of
couple of hundred rectangles, how would you enumerate all different sets of rectangles?
By the way, this task sounds the same as one of a Google interview's question. So, you may try to solve it by yourself before to check our solution.
We didn't even dare to think of brute-force solution: to enumerate all sets and then check each one whether it fits our needs.
Instead we used induction:
- Suppose S(N) - is an solution for our task for N rectangles R(n), where S(N) is a set of sets of rectangles;
- Then solution for S(N+1) will contain whole S(N), R(N+1) - a set consisting of single rectangle, and
some sets of rectangles from S(N) combinded with R(N+1) provided they fit the condition;
- S(0) - is an empty set.
The algorithm was implemented in java, and at first it was using
Streaming and recursion.
Then we have figured out that we can use
Stream.reduce or Stream.collect to implement
the same algorithm. That second implementation was a little bit longer but probably faster, and besides it used standard idioms.
But then at last step we reformulated the algorithms in terms of
Collections.
Though the final implementation is the least similar to original induction algorithm,
it's straightforward and definitely fastest among all implementations we tried.
So, here is the code:
/**
* For a sequence of items builds a list of matching groups.
* @param identity an identity instance used for the group.
* @param items original sequence of items.
* @param matcher a group matcher of item against a group.
* @param combiner creates a new group from a group (optional) and an item.
* @return a list of matching groups.
*/
public static <T, G> List<G> matchingGroups(
G identity,
Iterable<T> items,
BiPredicate<G, T> matcher,
BiFunction<G, T, G> combiner)
{
ArrayList<G> result = new ArrayList<>();
for(T item: items)
{
int size = result.size();
result.add(combiner.apply(identity, item));
for(int i = 0; i < size; ++i)
{
G group = result.get(i);
if (matcher.test(group, item))
{
result.add(combiner.apply(group, item));
}
}
}
return result;
}
The sample project on GitHub contains implementation and a tests of this algorithm.
It's very old theme...
Many years ago we have defined a .NET wrapper around Windows Uniscribe API.
Uniscribe API is used to render bidirectional languages like Hebrew, so it's important mainly here in Israel.
Once in a while we get request from people to give that API, so we published it on GitHub at https://github.com/nesterovsky-bros/BidiVisualConverter.
You're welcome to use it!
We have solved this problem years ago, but have run into it once again.
So, we shall log the solution here.
The problem: to minify payload of the JAXB serialized beans.
Java beans have many properties most of them contains default values: zero ints, empty strings, and so on.
JAXB never tries to omit default value from marshalled xml, the only thing it can remove from output is null values. So, our approach is to define xml adapter to map default values to nulls.
Here we refer to the StackOverflow question: Prevent writing default attribute values JAXB, and to our answer.
Though it's not as terse as one would wish, one can create XmlAdapters to avoid marshalling the default values.
The use case is like this:
@XmlRootElement(name = "FIELD")
public class TestLayoutNode
{
@XmlAttribute(name = "num")
@XmlJavaTypeAdapter(value = IntegerZero.class, type = int.class)
public int number;
@XmlAttribute(name = "str")
@XmlJavaTypeAdapter(StringDefault.class)
public String str = "default";
}
And here are adapters.
IntegerZero:
public class IntegerZero extends DefaultValue<Integer>
{
public Integer defaultValue() { return 0; }
}
StringDefault:
public class StringDefault extends DefaultValue<String>
{
public String defaultValue() { return "default"; }
}
DefaultValueAdapter:
public class DefaultValue<T> extends XmlAdapter<T, T>
{
public T defaultValue() { return null; }
public T marshal(T value) throws Exception
{
return (value == null) || value.equals(defaultValue()) ? null : value;
}
public T unmarshal(T value) throws Exception
{
return value;
}
}
With small number of different default values this approach works well.
Though ADO.NET and other ORM framworks like EntityFramework and Dapper support async pattern, you should remember that database drivers (at least all we know about) do not support concurrent db commands running against a single connection.
To see what we mean consider a bug we have recently identified. Consider a code:
await Task.WhenAll(
newImages.
Select(
async image =>
{
// Load data from url.
image.Content = await HttpUtils.ReadData(image.Url);
// Insert image into the database.
image.ImageID = await context.InsertImage(image);
}));
The code runs multiple tasks to read images, and to write them into a database.
Framework decides to run all these tasks in parallel. HttpUtils.ReadData() has no problem with parallel execution, while context.InsertImage() does not run well in parallel, and is a subject of race conditions.
To workaround the problem we had to use async variant of a critical section. So the fixed code looks like this:
using(var semaphore = new SemaphoreSlim(1))
{
await Task.WhenAll(
newImages.
Select(
async image =>
{
// Load data from url.
image.Content = await HttpUtils.ReadData(image.Url);
await semaphore.WaitAsync();
try
{
// Insert image into the database.
image.ImageID = await context.InsertImage(image);
}
finally
{
semaphore.Release();
}
}));
}
So, in the async world we still should care about race conditions.
In our angularjs projects we are often dealing with existing models that do not always fit to angularjs expectations.
Here is an example.
There is a model consisting of two arrays: for data, and for associated data. How to create an ng-repeat that displays data from both sources?
Consider a test controller (see a github sources, and a rawgit working sample):
model.controller(
"Test",
function()
{
this.records =
[
{ name: "record 1", state: "Draft" },
{ name: "record 2", state: "Public" },
{ name: "record 3", state: "Disabled" },
{ name: "record 4", state: "Public" },
{ name: "record 5", state: "Public" }
];
this.more =
[
{ value: 1, selected: true, visible: true },
{ value: 2, selected: false, visible: true },
{ value: 3, selected: true, visible: true },
{ value: 4, selected: false, visible: false },
{ value: 5, selected: false, visible: true }
];
this.delete = function(index)
{
this.records.splice(index, 1);
this.more.splice(index, 1);
};
});
Basically there are three approaches here:
- Change model.
- Adapt model to a single collection.
ng-repeat over first array and access the second array using $index scope variable.
We argued like this:
- It is often not an option to change a model, as it's how business data are described.
-
A model adaptation when we build a single collection from original two collections, and synchronize it back (if required) may unnecessary complicate things.
-
Thus let's get associated items by
$index variable.
This is an example of ng-repeat use:
<table border="1">
<tr>
<th>[x]</th>
<th>Name</th>
<th>Value</th>
<th>State</th>
<th>Actions</th>
</tr>
<tr ng-repeat="item in test.records track by $index"
ng-if="test.more[$index].visible">
<td>
<input type="checkbox" ng-model="test.more[$index].selected"/>
</td>
<td>{{item.name}}</td>
<td>{{test.more[$index].value}}</td>
<td>{{item.state}}</td>
<td>
<a href="#" ng-click="test.delete($index)">Delete</a>
</td>
</tr>
</table>
Look at how associated data is accessed: test.more[$index]... Our goal was to optimize that repeating parts, so we looked at ng-init directive.
Though docs warn about its use: "the only appropriate use of ngInit is for aliasing special properties of ngRepeat", we thought that our use of ng-init is rather close to what docs state, so we tried the following:
...
<tr ng-repeat="item in test.records track by $index"
ng-init="more = test.more[$index]"
ng-if="more.visible">
<td>
<input type="checkbox" ng-model="more.selected"/>
</td>
<td>{{item.name}}</td>
<td>{{more.value}}</td>
<td>{{item.state}}</td>
<td>
<a href="#" ng-click="test.delete($index)">Delete</a>
</td>
</tr>
...
This code just does not work, as it shows empty table, as if ng-if is always evaluated to false. From docs we found the reason:
- the priority of the directive
ng-if is higher than the prirority of the ng-init, and besides ng-if is a terminal directive;
-
as result
ng-if directive is bound, and ng-init is not;
- when
ng-if is evaluated no $scope.more is defined, so more.visible is evaluated to false.
To workaround ng-init/ng-if problem we refactored ng-if as ng-if-start/ng-if-end:
...
<tr ng-repeat="item in test.records track by $index"
ng-init="more = test.more[$index]">
<td ng-if-start="more.visible">
<input type="checkbox" ng-model="more.selected"/>
</td>
<td>{{item.name}}</td>
<td>{{more.value}}</td>
<td>{{item.state}}</td>
<td ng-if-end>
<a href="#" ng-click="test.delete($index)">Delete</a>
</td>
</tr>
...
This code works much better and shows a correct content. But then click "Delete" for a row with Name "record 2" and you will find that updated table is out of sync for all data that come from test.more array.
So, why the data goes out of sync? The reason is in the way how the ng-init is implemented: its expression is evaluated just once at directive's pre-link phase. So, the value of $scope.more will persist for the whole ng-init's life cycle, and it does not matter that test.mode[$index] may have changed at some point.
At this point we have decided to introduce a small directive named ui-eval that will act in a way similar to ng-init but that:
- will run before
ng-if;
- will be re-evaluated when it's value is changed.
This is it:
module.directive(
"uiEval",
function()
{
var directive =
{
restrict: 'A',
priority: 700,
link:
{
pre: function(scope, element, attr)
{
scope.$watch(attr["uiEval"]);
}
}
};
return directive;
});
The ui-eval version of the markup is:
...
<tr ng-repeat="item in test.records track by $index"
ui-eval="more = test.more[$index]"
ng-if="more.visible">
<td>
<input type="checkbox" ng-model="more.selected"/>
</td>
<td>{{item.name}}</td>
<td>{{more.value}}</td>
<td>{{item.state}}</td>
<td>
<a href="#" ng-click="test.delete($index)">Delete</a>
</td>
</tr>
...
It works as expected both during initial rendering and when model is updated.
We consider ui-eval is a "better" ng-init as it solves ng-init's silent limitations. On the other hand it should not try to evaluate any complex logic, as it can be often re-evaluated, so its use case is to alias a sub-expression. It can be used in any context and is not limited to items of ng-repeat.
Source code can be found at github, and a working sample at rawgit.
Stackoverfow shows that people are searching How to intercept $resource requests.
Recently we have written about the way to cancel angularjs $resource requests (see Cancel angularjs resource request).
Here we apply the same technique to intercept resource request.
Consider a sample (nesterovsky-bros/angularjs-api/master/angularjs/transform-request.html):
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Intercept resource request</title>
<style type="text/css">.ng-cloak { display: none; }</style>
<script src="angular.js"></script>
<script src="angular-resource.js"></script>
<script>
angular.module("app", ["ngResource"]).
factory(
"services",
["$resource", function ($resource)
{
return $resource(
"http://md5.jsontest.com/",
{},
{
MD5:
{
method: "GET",
params: { text: null },
then: function (resolve)
{
this.params.text = "***" + this.params.text + "***";
this.then = null;
resolve(this);
}
},
});
}]).
controller(
"Test",
["services", function (services)
{
this.value = "Sample text";
this.call = function()
{
this.result = services.MD5({ text: this.value });
}
}]);
</script>
</head>
<body ng-app="app" ng-controller="Test as test">
<label>Text: <input type="text" ng-model="test.value" /></label>
<input type="button" value="call" ng-click="test.call()"/>
<div ng-bind="test.result.md5"></div>
</body>
</html>
How it works.
$resource merges action definition, request params and data to build a config parameter for an $http request.- a
config parameter passed into an $http request is treated as a promise like object, so it may contain then function to initialize config.
- action's
then function may transform request as it wishes.
The demo can be found at transform-request.html
Often we need to keep a client session state in our angularjs application.
This state should survive page refresh and navigations within the application.
Earlier we used ngStorage module but lately have changed our opinion, as we think it's over-engineered and is too heavy at runtime.
We have replaced it with a simple service that synchronizes sessionStorage once during initialization, and once before page unload.
Look at an example (session.html):
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Session</title>
<style type="text/css">
.ng-cloak { display: none; }
</style>
<script src="angular.js"></script>
<script>
angular.module("app", []).
factory(
"session",
["$window", function($window)
{
var session =
angular.fromJson($window.sessionStorage.getItem("app")) || {};
$window.addEventListener(
"beforeunload",
function()
{
$window.sessionStorage.setItem("app", angular.toJson(session));
})
return session;
}]).
controller(
"Test",
["session",
function(session)
{
this.state = session;
}]);
</script>
</head>
<body ng-app="app" ng-controller="Test as test">
<input type="text" ng-model="test.state.value"/>
<a href="session.html?p=1">Page 1</a>
<a href="session.html?p=2">Page 2</a>
</body>
</html>
Source can be found at nesterovsky-bros/angularjs-api/services/session.html.
Earlier this year Mike Wasson has published a post: "Dependency Injection in ASP.NET Web API 2" that describes Web API's approach to the Dependency Injection design pattern.
In short it goes like this:
- Web API provides a primary integration point through
HttpConfiguration.DependencyResolver property, and tries to obtain many services through this resolver;
- Web API suggests to use your favorite Dependecy Injection library through the integration point. Author lists following libraries: Unity (by Microsoft), Castle Windsor, Spring.Net, Autofac, Ninject, and StructureMap.
The Unity Container (Unity) is a lightweight, extensible dependency injection container. There are Nugets both for Unity library and for Web API integration.
Now to the point of this post.
Unity defines a hierarchy of injection scopes. In Web API they are usually mapped to application and request scopes. This way a developer can inject application singletons, create request level, or transient objects.
Everything looks reasonable. The only problem we have found is that there is no way you to inject Web API objects like HttpConfiguration, HttpControllerContext or request's CancellationToken, as they are never registered for injection.
To workaround this we have created a small class called UnityControllerActivator that perfroms required registration:
using System;
using System.Net.Http;
using System.Threading;
using System.Threading.Tasks;
using System.Web.Http.Controllers;
using System.Web.Http.Dispatcher;
using Microsoft.Practices.Unity;
/// <summary>
/// Unity controller activator.
/// </summary>
public class UnityControllerActivator: IHttpControllerActivator
{
/// <summary>
/// Creates an UnityControllerActivator instance.
/// </summary>
/// <param name="activator">Base activator.</param>
public UnityControllerActivator(IHttpControllerActivator activator)
{
if (activator == null)
{
throw new ArgumentException("activator");
}
this.activator = activator;
}
/// <summary>
/// Creates a controller wrapper.
/// </summary>
/// <param name="request">A http request.</param>
/// <param name="controllerDescriptor">Controller descriptor.</param>
/// <param name="controllerType">Controller type.</param>
/// <returns>A controller wrapper.</returns>
public IHttpController Create(
HttpRequestMessage request,
HttpControllerDescriptor controllerDescriptor,
Type controllerType)
{
return new Controller
{
activator = activator,
controllerType = controllerType
};
}
/// <summary>
/// Base controller activator.
/// </summary>
private readonly IHttpControllerActivator activator;
/// <summary>
/// A controller wrapper.
/// </summary>
private class Controller: IHttpController, IDisposable
{
/// <summary>
/// Base controller activator.
/// </summary>
public IHttpControllerActivator activator;
/// <summary>
/// Controller type.
/// </summary>
public Type controllerType;
/// <summary>
/// A controller instance.
/// </summary>
public IHttpController controller;
/// <summary>
/// Disposes controller.
/// </summary>
public void Dispose()
{
var disposable = controller as IDisposable;
if (disposable != null)
{
disposable.Dispose();
}
}
/// <summary>
/// Executes an action.
/// </summary>
/// <param name="controllerContext">Controller context.</param>
/// <param name="cancellationToken">Cancellation token.</param>
/// <returns>Response message.</returns>
public Task<HttpResponseMessage> ExecuteAsync(
HttpControllerContext controllerContext,
CancellationToken cancellationToken)
{
if (controller == null)
{
var request = controllerContext.Request;
var container = request.GetDependencyScope().
GetService(typeof(IUnityContainer)) as IUnityContainer;
if (container != null)
{
container.RegisterInstance<HttpControllerContext>(controllerContext);
container.RegisterInstance<HttpRequestMessage>(request);
container.RegisterInstance<CancellationToken>(cancellationToken);
}
controller = activator.Create(
request,
controllerContext.ControllerDescriptor,
controllerType);
}
controllerContext.Controller = controller;
return controller.ExecuteAsync(controllerContext, cancellationToken);
}
}
}
Note on how it works.
IHttpControllerActivator is a controller factory, which Web API uses to create new controller instances using IHttpControllerActivator.Create(). Later controller's IHttpController.ExecuteAsync() is called to run the logic.-
UnityControllerActivator replaces original controller activator with a wrapper that delays creation (injection) of real controller untill request objects are registered in the scope
To register this class one need to update code in the UnityWebApiActivator.cs (file added with nuget Unity.AspNet.WebApi)
public static class UnityWebApiActivator
{
/// <summary>Integrates Unity when the application starts.<summary>
public static void Start()
{
var config = GlobalConfiguration.Configuration;
var container = UnityConfig.GetConfiguredContainer();
container.RegisterInstance<HttpConfiguration>(config);
container.RegisterInstance<IHttpControllerActivator>(
new UnityControllerActivator(config.Services.GetHttpControllerActivator()));
config.DependencyResolver = UnityHierarchicalDependencyResolver(container);
}
...
}
With this addition we have simplified the boring problem with passing of CancellationToken all around the code, as controller (and other classes) just declared a property to inject:
public class MyController: ApiController
{
[Dependency]
public CancellationToken CancellationToken { get; set; }
[Dependency]
public IModelContext Model { get; set; }
public async Task<IEnumerable<Products>> GetProducts(...)
{
...
}
public async Task<IEnumerable<Customer>> GetCustomer(...)
{
...
}
...
}
...
public class ModelContext: IModelContext
{
[Dependency]
public CancellationToken CancellationToken { get; set; }
...
}
And finally to perform unit tests for controllers with Depenency Injection you can use a code like this:
using System.Threading;
using System.Threading.Tasks;
using System.Web.Http;
using System.Web.Http.Controllers;
using System.Web.Http.Dependencies;
using System.Net.Http;
using Microsoft.Practices.Unity;
using Microsoft.Practices.Unity.WebApi;
using Microsoft.VisualStudio.TestTools.UnitTesting;
[TestClass]
public class MyControllerTest
{
[ClassInitialize]
public static void Initialize(TestContext context)
{
config = new HttpConfiguration();
Register(config);
}
[ClassCleanup]
public static void Cleanup()
{
config.Dispose();
}
[TestMethod]
public async Task GetProducts()
{
var controller = CreateController<MyController>();
//...
}
public static T CreateController<T>(HttpRequestMessage request = null)
where T: ApiController
{
if (request == null)
{
request = new HttpRequestMessage();
}
request.SetConfiguration(config);
var controllerContext = new HttpControllerContext()
{
Configuration = config,
Request = request
};
var scope = request.GetDependencyScope();
var container = scope.GetService(typeof(IUnityContainer))
as IUnityContainer;
if (container != null)
{
container.RegisterInstance<HttpControllerContext>(controllerContext);
container.RegisterInstance<HttpRequestMessage>(request);
container.RegisterInstance<CancellationToken>(CancellationToken.None);
}
T controller = scope.GetService(typeof(T)) as T;
controller.Configuration = config;
controller.Request = request;
controller.ControllerContext = controllerContext;
return controller;
}
public static void Register(HttpConfiguration config)
{
config.DependencyResolver = CreateDependencyResolver(config);
}
public static IDependencyResolver CreateDependencyResolver(HttpConfiguration config)
{
var container = new UnityContainer();
container.RegisterInstance<HttpConfiguration>(config);
// TODO: configure Unity contaiener.
return new UnityHierarchicalDependencyResolver(container);
}
public static HttpConfiguration config;
}
P.S. To those who think Dependency Injection is an universal tool, please read the article: Dependency Injection is Evil. 
Earlier this year Mike Wasson has published a post: "Dependency Injection in ASP.NET Web API 2" that describes Web API's approach to the Dependency Injection design pattern.
In short it goes like this:
- Web API provides a primary integration point through
HttpConfiguration.DependencyResolver property, and tries to obtain many services through this resolver;
- Web API suggests to use your favorite Dependecy Injection library through the integration point. Author lists following libraries: Unity (by Microsoft), Castle Windsor, Spring.Net, Autofac, Ninject, and StructureMap.
The Unity Container (Unity) is a lightweight, extensible dependency injection container. There are Nugets both for Unity library and for Web API integration.
Now to the point of this post.
Unity defines a hierarchy of injection scopes. In Web API they are usually mapped to application and request scopes. This way a developer can inject application singletons, create request level, or transient objects.
Everything looks reasonable. The only problem we have found is that there is no way you to inject Web API objects like HttpConfiguration, HttpControllerContext or request's CancellationToken, as they are never registered for injection.
To workaround this we have created a small class called UnityControllerActivator that perfroms required registration:
using System;
using System.Net.Http;
using System.Threading;
using System.Threading.Tasks;
using System.Web.Http.Controllers;
using System.Web.Http.Dispatcher;
using Microsoft.Practices.Unity;
/// <summary>
/// Unity controller activator.
/// </summary>
public class UnityControllerActivator: IHttpControllerActivator
{
/// <summary>
/// Creates an UnityControllerActivator instance.
/// </summary>
/// <param name="activator">Base activator.</param>
public UnityControllerActivator(IHttpControllerActivator activator)
{
if (activator == null)
{
throw new ArgumentException("activator");
}
this.activator = activator;
}
/// <summary>
/// Creates a controller wrapper.
/// </summary>
/// <param name="request">A http request.</param>
/// <param name="controllerDescriptor">Controller descriptor.</param>
/// <param name="controllerType">Controller type.</param>
/// <returns>A controller wrapper.</returns>
public IHttpController Create(
HttpRequestMessage request,
HttpControllerDescriptor controllerDescriptor,
Type controllerType)
{
return new Controller
{
activator = activator,
controllerType = controllerType
};
}
/// <summary>
/// Base controller activator.
/// </summary>
private readonly IHttpControllerActivator activator;
/// <summary>
/// A controller wrapper.
/// </summary>
private class Controller: IHttpController, IDisposable
{
/// <summary>
/// Base controller activator.
/// </summary>
public IHttpControllerActivator activator;
/// <summary>
/// Controller type.
/// </summary>
public Type controllerType;
/// <summary>
/// A controller instance.
/// </summary>
public IHttpController controller;
/// <summary>
/// Disposes controller.
/// </summary>
public void Dispose()
{
var disposable = controller as IDisposable;
if (disposable != null)
{
disposable.Dispose();
}
}
/// <summary>
/// Executes an action.
/// </summary>
/// <param name="controllerContext">Controller context.</param>
/// <param name="cancellationToken">Cancellation token.</param>
/// <returns>Response message.</returns>
public Task<HttpResponseMessage> ExecuteAsync(
HttpControllerContext controllerContext,
CancellationToken cancellationToken)
{
if (controller == null)
{
var request = controllerContext.Request;
var container = request.GetDependencyScope().
GetServices(typeof(IUnityContainer)) as IUnityContainer;
if (container != null)
{
container.RegisterInstance<HttpControllerContext>(controllerContext);
container.RegisterInstance<HttpRequestMessage>(request);
container.RegisterInstance<CancellationToken>(cancellationToken);
}
controller = activator.Create(
request,
controllerContext.ControllerDescriptor,
controllerType);
}
controllerContext.Controller = controller;
return controller.ExecuteAsync(controllerContext, cancellationToken);
}
}
}
Note on how it works.
IHttpControllerActivator is a controller factory, which Web API uses to create new controller instances using IHttpControllerActivator.Create(). Later controller's IHttpController.ExecuteAsync() is called to run the logic.-
UnityControllerActivator replaces original controller activator with a wrapper that delays creation (injection) of real controller untill request objects are registered in the scope
To register this class one need to update code in the UnityWebApiActivator.cs (file added with nuget Unity.AspNet.WebApi)
public static class UnityWebApiActivator
{
/// <summary>Integrates Unity when the application starts.<summary>
public static void Start()
{
var config = GlobalConfiguration.Configuration;
var container = UnityConfig.GetConfiguredContainer();
container.RegisterInstance<HttpConfiguration>(config);
container.RegisterInstance<IHttpControllerActivator>(
new UnityControllerActivator(config.Services.GetHttpControllerActivator()));
config.DependencyResolver = UnityHierarchicalDependencyResolver(container);
}
...
}
With this addition we have simplified the boring problem with passing of CancellationToken all around the code, as controller (and other classes) just declared a property to inject:
public class MyController: ApiController
{
[Dependency]
public CancellationToken CancellationToken { get; set; }
[Dependency]
public IModelContext Model { get; set; }
public async Task<IEnumerable<Products>> GetProducts(...)
{
...
}
public async Task<IEnumerable<Customer>> GetCustomer(...)
{
...
}
...
}
...
public class ModelContext: IModelContext
{
[Dependency]
public CancellationToken CancellationToken { get; set; }
...
}
And finally to perform unit tests for controllers with Depenency Injection you can use a code like this:
using System.Threading;
using System.Threading.Tasks;
using System.Web.Http;
using System.Web.Http.Controllers;
using System.Web.Http.Dependencies;
using System.Net.Http;
using Microsoft.Practices.Unity;
using Microsoft.Practices.Unity.WebApi;
using Microsoft.VisualStudio.TestTools.UnitTesting;
[TestClass]
public class MyControllerTest
{
[ClassInitialize]
public static void Initialize(TestContext context)
{
config = new HttpConfiguration();
Register(config);
}
[ClassCleanup]
public static void Cleanup()
{
config.Dispose();
}
[TestMethod]
public async Task GetProducts()
{
var controller = CreateController<MyController>();
//...
}
public static T CreateController<T>(HttpRequestMessage request = null)
where T: ApiController
{
if (request == null)
{
request = new HttpRequestMessage();
}
request.SetConfiguration(config);
var controllerContext = new HttpControllerContext()
{
Configuration = config,
Request = request
};
var scope = request.GetDependencyScope();
var container = scope.GetService(typeof(IUnityContainer))
as IUnityContainer;
if (container != null)
{
container.RegisterInstance<HttpControllerContext>(controllerContext);
container.RegisterInstance<HttpRequestMessage>(request);
container.RegisterInstance<CancellationToken>(CancellationToken.None);
}
T controller = scope.GetService(typeof(T)) as T;
controller.Configuration = config;
controller.Request = request;
controller.ControllerContext = controllerContext;
return controller;
}
public static void Register(HttpConfiguration config)
{
config.DependencyResolver = CreateDependencyResolver(config);
}
public static IDependencyResolver CreateDependencyResolver(HttpConfiguration config)
{
var container = new UnityContainer();
container.RegisterInstance<HttpConfiguration>(config);
// TODO: configure Unity contaiener.
return new UnityHierarchicalDependencyResolver(container);
}
public static HttpConfiguration config;
}
P.S. To those who think Dependency Injection is an universal tool, please read the article: Dependency Injection is Evil.
Looking at Guava Cache we think its API is more convenient than .NET's Cache API.
Just consider:
-
.NET has getters, and setters of objects by string keys.
You should provide caching policy with each setter.
-
Guava cache operates with typed storage of Key to Value.
Provides a value factory and a caching policy in advance at cache construction.
Guava's advantange is based on an idea that homogenous storage assumes a uniform way of creation of values, and uniform caching policy. Thus a great part of logic is factored out into a cache initialization.
We have decided to create a simple adapter of the MemoryCache to achieve the same goal. Here is a result of such an experiment:
public class Cache<K, V>
where V: class
{
/// <summary>
/// A cache builder.
/// </summary>
public struct Builder
{
/// <summary>
/// A memory cache. If not specified then MemoryCache.Default is used.
/// </summary>
public MemoryCache MemoryCache;
/// <summary>
/// An expiration value.
/// Alternatively CachePolicyFunc can be used.
/// </summary>
public TimeSpan Expiration;
/// <summary>
/// Indicates whether to use sliding (true), or absolute (false)
/// expiration.
/// Alternatively CachePolicyFunc can be used.
/// </summary>
public bool Sliding;
/// <summary>
/// Optional function to get caching policy.
/// Alternatively Expiration and Sliding property can be used.
/// </summary>
public Func<V, CacheItemPolicy> CachePolicyFunc;
/// <summary>
/// Optional value validator.
/// </summary>
public Func<V, bool> Validator;
/// <summary>
/// A value factory.
/// Alternatively FactoryAsync can be used.
/// </summary>
public Func<K, V> Factory;
/// <summary>
/// Async value factory.
/// Alternatively Factory can be used.
/// </summary>
public Func<K, Task<V>> FactoryAsync;
/// <summary>
/// A key to string converter.
/// </summary>
public Func<K, string> KeyFunc;
/// <summary>
/// Converts builder to a Cache<K, V> instance.
/// </summary>
/// <param name="builder">A builder to convert.</param>
/// <returns>A Cache<K, V> instance.</returns>
public static implicit operator Cache<K, V>(Builder builder)
{
return new Cache<K, V>(builder);
}
}
/// <summary>
/// Creates a cache from a cache builder.
/// </summary>
/// <param name="builder">A cache builder instance.</param>
public Cache(Builder builder)
{
if ((builder.Factory == null) && (builder.FactoryAsync == null))
{
throw new ArgumentException("builder.Factory");
}
if (builder.MemoryCache == null)
{
builder.MemoryCache = MemoryCache.Default;
}
this.builder = builder;
}
/// <summary>
/// Cached value by key.
/// </summary>
/// <param name="key">A key.</param>
/// <returns>A cached value.</returns>
public V this[K key]
{
get { return Get(key); }
set { Set(key, value); }
}
/// <summary>
/// Sets a value for a key.
/// </summary>
/// <param name="key">A key to set.</param>
/// <param name="value">A value to set.</param>
public void Set(K key, V value)
{
SetImpl(GetKey(key), IsValid(value) ? value : null);
}
/// <summary>
/// Gets a value for a key.
/// </summary>
/// <param name="key">A key to get value for.</param>
/// <returns>A value instance.</returns>
public V Get(K key)
{
var keyValue = GetKey(key);
var value = builder.MemoryCache.Get(keyValue) as V;
if (!IsValid(value))
{
value = CreateValue(key);
SetImpl(keyValue, value);
}
return value;
}
/// <summary>
/// Gets a task to return an async value.
/// </summary>
/// <param name="key">A key.</param>
/// <returns>A cached value.</returns>
public async Task<V> GetAsync(K key)
{
var keyValue = GetKey(key);
var value = builder.MemoryCache.Get(keyValue) as V;
if (!IsValid(value))
{
value = await CreateValueAsync(key);
SetImpl(keyValue, value);
}
return value;
}
/// <summary>
/// Gets string key value for a key.
/// </summary>
/// <param name="key">A key.</param>
/// <returns>A string key value.</returns>
protected string GetKey(K key)
{
return builder.KeyFunc != null ? builder.KeyFunc(key) :
key == null ? null : key.ToString();
}
/// <summary>
/// Creates a value for a key.
/// </summary>
/// <param name="key">A key to create value for.</param>
/// <returns>A value instance.</returns>
protected V CreateValue(K key)
{
return builder.Factory != null ? builder.Factory(key) :
builder.FactoryAsync(key).Result;
}
/// <summary>
/// Creates a task for value for a key.
/// </summary>
/// <param name="key">A key to create value for.</param>
/// <returns>A task for a value instance.</returns>
protected Task<V> CreateValueAsync(K key)
{
return builder.FactoryAsync != null ? builder.FactoryAsync(key) :
Task.FromResult(builder.Factory(key));
}
/// <summary>
/// Validates the value.
/// </summary>
/// <param name="value">A value to validate.</param>
/// <returns>
/// true if value is valid for a cache, and false otherise.
/// </returns>
protected bool IsValid(V value)
{
return (value != null) &&
((builder.Validator == null) || builder.Validator(value));
}
/// <summary>
/// Set implementation.
/// </summary>
/// <param name="key">A key to set value for.</param>
/// <param name="value">A value to set.</param>
/// <returns>A set value.</returns>
private V SetImpl(string key, V value)
{
if (value == null)
{
builder.MemoryCache.Remove(key);
}
else
{
builder.MemoryCache.Set(
key,
value,
builder.CachePolicyFunc != null ? builder.CachePolicyFunc(value) :
builder.Sliding ?
new CacheItemPolicy { SlidingExpiration = builder.Expiration } :
new CacheItemPolicy
{
AbsoluteExpiration = DateTime.Now + builder.Expiration
});
}
return value;
}
/// <summary>
/// Cache builder.
/// </summary>
private Builder builder;
}
The use consists of initialization:
Cache<MyKey, MyValue> MyValues =
new Cache<MyKey, MyValue>.Builder
{
KeyFunc = key => ...key to string value...,
Factory = key => ...create a value for a key...,
Expiration = new TimeSpan(0, 3, 0),
Sliding = true
};
and a trivial cache access:
var value = MyValues[key];
This contrasts with MemoryCache coding pattern:
MemoryCache cache = MemoryCache.Default;
...
var keyAsString = ...key to string value...
var value = cache.Get(keyAsString) as MyValue;
if (value == null)
{
value = ...create a value for a key...
cache.Set(keyAsString, value, ...caching policy...);
}
In the article "Error handling in WCF based web applications"
we've shown a custom error handler for RESTful service
based on WCF. This time we shall do the same for Web API 2.1 service.
Web API 2.1 provides an elegant way to implementat custom error handlers/loggers, see
the following article. Web API permits many error loggers followed by a
single error handler for all uncaught exceptions. A default error handler knows to output an error both in XML and JSON formats depending on requested
MIME type.
In our projects we use unique error reference IDs. This feature allows to an end-user to refer to any error that has happened during the application life time and pass such error ID to the technical support for further investigations. Thus, error details passed to the client-side contain an ErrorID field. An error logger generates ErrorID and passes it over to an error handler for serialization.
Let's look at our error handling implementation for a Web API application.
The first part is an implementation of IExceptionLogger
interface. It assigns ErrorID and logs all errors:
/// Defines a global logger for unhandled exceptions.
public class GlobalExceptionLogger : ExceptionLogger
{
/// Writes log record to the database synchronously.
public override void Log(ExceptionLoggerContext context)
{
try
{
var request = context.Request;
var exception = context.Exception;
var id = LogError(
request.RequestUri.ToString(),
context.RequestContext == null ?
null : context.RequestContext.Principal.Identity.Name,
request.ToString(),
exception.Message,
exception.StackTrace);
// associates retrieved error ID with the current exception
exception.Data["NesterovskyBros:id"] = id;
}
catch
{
// logger shouldn't throw an exception!!!
}
}
// in the real life this method may store all relevant info into a database.
private long LogError(
string address,
string userid,
string request,
string message,
string stackTrace)
{
...
}
}
The second part is the implementation of IExceptionHandler:
/// Defines a global handler for unhandled exceptions.
public class GlobalExceptionHandler : ExceptionHandler
{
/// This core method should implement custom error handling, if any.
/// It determines how an exception will be serialized for client-side processing.
public override void Handle(ExceptionHandlerContext context)
{
var requestContext = context.RequestContext;
var config = requestContext.Configuration;
context.Result = new ErrorResult(
context.Exception,
requestContext == null ? false : requestContext.IncludeErrorDetail,
config.Services.GetContentNegotiator(),
context.Request,
config.Formatters);
}
/// An implementation of IHttpActionResult interface.
private class ErrorResult : ExceptionResult
{
public ErrorResult(
Exception exception,
bool includeErrorDetail,
IContentNegotiator negotiator,
HttpRequestMessage request,
IEnumerable<MediaTypeFormatter> formatters) :
base(exception, includeErrorDetail, negotiator, request, formatters)
{
}
/// Creates an HttpResponseMessage instance asynchronously.
/// This method determines how a HttpResponseMessage content will look like.
public override Task<HttpResponseMessage> ExecuteAsync(CancellationToken cancellationToken)
{
var content = new HttpError(Exception, IncludeErrorDetail);
// define an additional content field with name "ErrorID"
content.Add("ErrorID", Exception.Data["NesterovskyBros:id"] as long?);
var result =
ContentNegotiator.Negotiate(typeof(HttpError), Request, Formatters);
var message = new HttpResponseMessage
{
RequestMessage = Request,
StatusCode = result == null ?
HttpStatusCode.NotAcceptable : HttpStatusCode.InternalServerError
};
if (result != null)
{
try
{
// serializes the HttpError instance either to JSON or to XML
// depend on requested by the client MIME type.
message.Content = new ObjectContent<HttpError>(
content,
result.Formatter,
result.MediaType);
}
catch
{
message.Dispose();
throw;
}
}
return Task.FromResult(message);
}
}
}
Last, but not least part of this solution is registration and configuration of the error logger/handler:
/// WebApi congiguation.
public static class WebApiConfig
{
public static void Register(HttpConfiguration config)
{
...
// register the exception logger and handler
config.Services.Add(typeof(IExceptionLogger), new GlobalExceptionLogger());
config.Services.Replace(typeof(IExceptionHandler), new GlobalExceptionHandler());
// set error detail policy according with value from Web.config
var customErrors =
(CustomErrorsSection)ConfigurationManager.GetSection("system.web/customErrors");
if (customErrors != null)
{
switch (customErrors.Mode)
{
case CustomErrorsMode.RemoteOnly:
{
config.IncludeErrorDetailPolicy = IncludeErrorDetailPolicy.LocalOnly;
break;
}
case CustomErrorsMode.On:
{
config.IncludeErrorDetailPolicy = IncludeErrorDetailPolicy.Never;
break;
}
case CustomErrorsMode.Off:
{
config.IncludeErrorDetailPolicy = IncludeErrorDetailPolicy.Always;
break;
}
default:
{
config.IncludeErrorDetailPolicy = IncludeErrorDetailPolicy.Default;
break;
}
}
}
}
}
The client-side error handler remain almost untouched. The implementation details you may find in
/Scripts/api/api.js and Scripts/controls/error.js files.
You may download the demo project here.
Feel free to use this solution in your .NET projects.
From time to time we run into tasks that we would like to solve in LINQ style but unfortunately it either cannot be done or a solution is not efficient.
Note that by LINQ style we do not mean C# query expressions (we have a strong distaste for that syntax) but extension methods defined in System.Linq.Enumerable and other classes.
Here we quote several extension methods that are good for a general use:
1. Select with predicate. This is shorthand of items.Where(...).Select(...):
/// <summary>
/// Projects each element of a sequence into a new form.
/// </summary>
/// <typeparam name="T">A type of elements of source sequence.</typeparam>
/// <typeparam name="R">A type of elements of target sequence.</typeparam>
/// <param name="source">A source sequence.</param>
/// <param name="where">A predicate to filter elements.</param>
/// <param name="selector">A result element selector.</param>
/// <returns>A target sequence.</returns>
public static IEnumerable<R> Select<T, R>(
this IEnumerable<T> source,
Func<T, bool> where,
Func<T, R> selector)
{
return source.Where(where).Select(selector);
}
2. Select with predicate with source element index passed both into the predicate and into the selector. This one you cannot trivially implement in LINQ:
/// <summary>
/// Projects each element of a sequence into a new form.
/// </summary>
/// <typeparam name="T">A type of elements of source sequence.</typeparam>
/// <typeparam name="R">A type of elements of target sequence.</typeparam>
/// <param name="source">A source sequence.</param>
/// <param name="where">A predicate to filter elements.</param>
/// <param name="selector">A result element selector.</param>
/// <returns>A target sequence.</returns>
public static IEnumerable<R> Select<T, R>(
this IEnumerable<T> source,
Func<T, int, bool> where,
Func<T, int, R> selector)
{
var index = 0;
foreach(var value in source)
{
if (where(value, index))
{
yield return selector(value, index);
}
++index;
}
}
3. A function with output element as projection of a window of input elements. Such function can be used to get finite difference (operation opposite to a cumulative sum).
/// <summary>
/// Projects a window of source elements in a source sequence into target sequence.
/// Thus
/// target[i] =
/// selector(source[i], source[i - 1], ... source[i - window + 1])
/// </summary>
/// <typeparam name="T">A type of elements of source sequence.</typeparam>
/// <typeparam name="R">A type of elements of target sequence.</typeparam>
/// <param name="source">A source sequence.</param>
/// <param name="window">A size of window.</param>
/// <param name="lookbehind">
/// Indicate whether to produce target if the number of source elements
/// preceeding the current is less than the window size.
/// </param>
/// <param name="lookahead">
/// Indicate whether to produce target if the number of source elements
/// following current is less than the window size.
/// </param>
/// <param name="selector">
/// A selector that derives target element.
/// On input it receives:
/// an array of source elements stored in round-robing fashon;
/// an index of the first element;
/// a number of elements in the array to count.
/// </param>
/// <returns>Returns a sequence of target elements.</returns>
public static IEnumerable<R> Window<T, R>(
this IEnumerable<T> source,
int window,
bool lookbehind,
bool lookahead,
Func<T[], int, int, R> selector)
{
var buffer = new T[window];
var index = 0;
var count = 0;
foreach(var value in source)
{
if (count < window)
{
buffer[count++] = value;
if (lookbehind || (count == window))
{
yield return selector(buffer, 0, count);
}
}
else
{
buffer[index] = value;
index = index + 1 == window ? 0 : index + 1;
yield return selector(buffer, index, count);
}
}
if (lookahead)
{
while(--count > 0)
{
index = index + 1 == window ? 0 : index + 1;
yield return selector(buffer, index, count);
}
}
}
This way a finite difference looks like this:
var diff = input.Window(
2,
false,
false,
(buffer, index, count) => buffer[index ^ 1] - buffer[index]);
4. A specialization of Window method that returns a enumeration of windows:
/// <summary>
/// Projects a window of source elements in a source sequence into a
/// sequence of window arrays.
/// </summary>
/// <typeparam name="T">A type of elements of source sequence.</typeparam>
/// <typeparam name="R">A type of elements of target sequence.</typeparam>
/// <param name="source">A source sequence.</param>
/// <param name="window">A size of window.</param>
/// <param name="lookbehind">
/// Indicate whether to produce target if the number of source elements
/// preceeding the current is less than the window size.
/// </param>
/// <param name="lookahead">
/// Indicate whether to produce target if the number of source elements
/// following current is less than the window size.
/// </param>
/// <returns>Returns a sequence of windows.</returns>
public static IEnumerable<T[]> Window<T>(
this IEnumerable<T> source,
int window,
bool lookbehind,
bool lookahead)
{
return source.Window(
window,
lookbehind,
lookahead,
(buffer, index, count) =>
{
var result = new T[count];
for(var i = 0; i < count; ++i)
{
result[i] = buffer[index];
index = index + 1 == buffer.Length ? 0 : index + 1;
}
return result;
});
}
These are initial positions for this writing:
- SQL Server allows to execute dynamic SQL.
- Dynamic SQL is useful and often unavoidable, e.g. when you have to filter or order data in a way that you cannot code efficiently in advance.
- Dynamic SQL has proven to be a dangerous area, as with improper use it can open hole in a security.
In general nothing stops you from building and then excuting of SQL string. Our goal, however, is to define rules that make work with dynamic SQL is more managable and verifiable.
Here we outline these rules, and then give some examples and tips.
Rule #1. Isolate dynamic SQL
Put all logic related to building of dynamic SQL into a separate function.
We usually define a separate scheme Dynamic, and define functions like Dynamic.GetSQL_XXX(params).
This makes it simple to perform code review.
Rule #2. Xml as parameters
Use xml type to pass parameters to a function that builds dynamic SQL.
In many cases dynamic SQL depends on variable number of parameters (like a list of values to check against).
Xml fits here to represent structured information.
On a client (e.g. in C# or java) you can define a class with all parameters, populate an instance and serialize it to an xml.
Rule #3. XQuery as template language
Use XQuery to define SQL template and to generate SQL tree from the input parameters.
Here is an example of such XQuery:
@data.query('
<sql>
select
T.*
from
Data.Ticket T
where
{
for $ticketID in data/ticketID return
<sql>(T.TicketID = <int>{$ticketID}</int>) and </sql>
}
(1 = 1)
</sql>')
You can see that output is an xml
with sql element to represent literal SQL, and int element to represent integer literal.
In fact whole output schema can be defined like this:
<xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="sql"/>
<xs:element name="name"/>
<xs:element name="string" nillable="true"/>
<xs:element name="int" nillable="true"/>
<xs:element name="decimal" nillable="true"/>
<xs:element name="date" nillable="true"/>
<xs:element name="time" nillable="true"/>
<xs:element name="datetime" nillable="true"/>
</xs:schema>
where sql is to represent literal content, name to represent a name, and other elements to represent different literal values.
Rule #4. Escape literals
Use function Dynamic.ToSQL(@template) to build final SQL text.
Here we quote the definition:
-- Builds a text of SQL function for an sql template.
create function Dynamic.ToSQL
(
-- SQL template.
@template xml
)
returns nvarchar(max)
with returns null on null input
as
begin
return
(
select
case
when N.Node.exist('*[xs:boolean(@xsi:nil)]') = 1 then
'null'
when N.Node.exist('self::int') = 1 then
isnull(N.Node.value('xs:int(.)', 'nvarchar(max)'), '# int #')
when N.Node.exist('self::string') = 1 then
'N''' +
replace
(
N.Node.value('.', 'nvarchar(max)'),
'''',
''''''
) +
''''
when N.Node.exist('self::name') = 1 then
isnull
(
quotename(N.Node.value('.', 'nvarchar(128)'), '['),
'# name #'
)
when N.Node.exist('self::datetime') = 1 then
isnull
(
'convert(datetime2, ''' +
N.Node.value('xs:dateTime(.)', 'nvarchar(128)') +
''', 126)',
'# datetime #'
)
when N.Node.exist('self::date') = 1 then
isnull
(
'convert(date, ''' +
N.Node.value('xs:date(.)', 'nvarchar(128)') +
''', 126)',
'# date #'
)
when N.Node.exist('self::time') = 1 then
isnull
(
'convert(time, ''' +
N.Node.value('xs:time(.)', 'nvarchar(128)') +
''', 114)',
'# time #'
)
when N.Node.exist('self::decimal') = 1 then
isnull
(
N.Node.value('xs:decimal(.)', 'nvarchar(128)'),
'# decimal #'
)
when N.Node.exist('self::*') = 1 then
'# invalid template #'
else
N.Node.value('.', 'nvarchar(max)')
end
from
@template.nodes('//sql/node()[not(self::sql)]') N(Node)
for xml path(''), type
).value('.', 'nvarchar(max)');
end;
Now, we want to stress that this function plays an important role in prevention of the SQL injection, as it escapes literals from the SQL tree.
Rule #5 (optional). Collect data
Use SQL to collect additional data required to build dynamic SQL. Here is an example of how we get a Ticket by StatusID, while on input we receive a StatusName:
create function Dynamic.GetSQL_GetTicketByStatus(@data xml)
returns nvarchar(max)
as
begin
set @data =
(
select
@data,
(
select
T.StatusID
from
@data.nodes('/data/status') N(Node)
inner join
Metadata.Status T
on
T.StatusName = Node.value('.', 'nvarchar(128)')
for xml auto, type, elements
)
for xml path('')
);
return Dynamic.ToSQL
(
@data.query
('
<sql>
select
T.*
from
Data.Ticket T
where
T.Status in ({ for $status in /T/StatusID return <sql><int>{$status}</int>,</sql> } null)
</sql>
')
);
end;
Notice code in red that collects some more data before calling XQuery.
Rule #6. Execute
The final step is to call dynamic SQL.
This is done like this:
-- build
declare @sql nvarchar(max) = Dynamic.GetSQL_GetTicket(@data);
-- execute
execute sp_executesql
@sql
-- {, N'@parameter_name data_type [ OUT | OUTPUT ][ ,...n ]' }
-- { , [ @param1 = ] 'value1' [ ,...n ] }
with result sets
(
(
TicketID int not null,
CreatedAt datetime2 not null,
Summary nvarchar(256) null,
Status int,
Severity int,
DeadLineAt datetime2 null
)
);
Notice that the use of dynamic SQL does not prevent static parameters.
Notice also that with result sets clause is used to specify output.
Example. Tickets system
Let's assume you're dealing with a tickets system (like Bugzilla), and you have a table Data.Ticket to describe tickets. Assume that DDL for this table is like this:
create table Data.Ticket
(
TicketID bigint not null primary key,
CreatedAt datetime2 not null,
Summary nvarchar(128) null,
Status int not null,
UpdatedAt datetime2(7) not null
)
Suppose you have to build C# code to search different tickets, where Entity Framework is used to access the database.
Search should be done by a range of CreatedAt, a range of UpdatedAt, Summary, or by different Status values. It should be possible to order results in different ways.
We start out solution from the C# and define classes for a request:
public enum Direction
{
Asc,
Desc
}
public struct Order
{
public string Field { get; set; }
public Direction Direction {get; set; }
}
public class DateRange
{
public DateTime? From { get; set; }
// This property is to omit From element if value is null.
// See rules for xml serialization.
public bool FromSpecified
{
get { return From != null; }
}
public DateTime? To { get; set; }
public bool ToSpecified
{
get { return To != null; }
}
}
public class TicketsRequest
{
public DateRange CreatedAt { get; set; }
public string Summary { get; set; }
public DateRange UpdatedAt { get; set; }
[XmlElement]
public Order[] Order { get; set; }
[XmlElement]
public int[] Status { get; set; }
}
Notice that we're going to use XmlSerializer to convert request to xml and then to pass parameter into EF's model. Here is utility method to perform such conversion:
public static string ToXmlString<T>(T value)
{
if (value == null)
{
return null;
}
var serializer = new XmlSerializer(typeof(T));
var builder = new StringBuilder();
var writer = XmlWriter.Create(
builder,
new XmlWriterSettings
{
OmitXmlDeclaration = true,
Indent = false
});
serializer.Serialize(writer, value);
writer.Flush();
return builder.ToString();
}
Now we proceed to the database and define a procedure that runs the search:
-- Gets tickets.
create procedure Data.GetTickets
(
-- A query parameters.
@params xml
)
as
begin
set nocount on;
-- This is for EF to guess type of result.
if (1 = 0)
begin
select
TicketID,
CreatedAt,
Summary,
Status,
UpdatedAt
from
Data.Ticket;
end;
declare @sql nvarchar(max) = Dynamic.GetSQL_GetTickets(@params);
execute sp_executesql @sql
with result sets
(
(
TicketID int not null,
CreatedAt datetime2 not null,
Summary nvarchar(256) null,
Status int,
UpdatedAt datetime2 null
)
);
end;
Switch back to C#, import the Data.GetTickets into the EF model, and create a search method:
public IEnumerable<Ticket> GetTickets(TicketsRequest request)
{
var model = new Model();
return model.GetTickets(ToXmlString(request));
}
The last ingredient is Dynamic.GetSQL_GetTickets() function.
create function Dynamic.GetSQL_GetTickets(@data xml)
returns nvarchar(max)
as
begin
return Dynamic.ToSQL
(
@data.query('
<sql>
select
T.TicketID,
T.CreatedAt,
T.Summary,
T.Status,
T.UpdatedAt
from
Data.Ticket T
where
{
for $range in */CreatedAt return
(
for $date in $range/From return
<sql>
(T.CreatedAt >= <datetime>{$date}</datetime>) and
</sql>,
for $date in $range/To return
<sql>
(<datetime>{$date}</datetime> > T.CreatedAt) and
</sql>
),
for $range in */UpdatedAt return
(
for $date in $range/From return
<sql>
(T.UpdatedAt >= <datetime>{$date}</datetime>) and
</sql>,
for $date in $range/To return
<sql>
(<datetime>{$date}</datetime> > T.UpdatedAt) and
</sql>
),
for $summary in */Summary return
<sql>
(T.Summary like <string>{$summary}</string>) and
</sql>,
if (*/Status) then
<sql>
T.Status in
({
for $status in */Status return
<sql><int>{$status}</int>, </sql>
} null) and
</sql>
else ()
}
(1 = 1)
order by
{
for $order in
*/Order
[
Field = ("TicketID", "CreatedAt", "Summary", "UpdatedAt", "Status")
]
return
<sql>
<name>{$order/Field}</name>
{" desc"[$order[Direction = "Desc"]]},
</sql>
}
(select null)
</sql>
')
);
end;
SQL text from Dynamic.GetSQL_GetTickets()
Consider now SQL text produced by this function. For an input:
<TicketsRequest>
<CreatedAt>
<From>2014-01-01T00:00:00</From>
</CreatedAt>
<Summary>hello%</Summary>
<Order>
<Field>Status</Field>
<Direction>Desc</Direction>
</Order>
<Status>1</Status>
<Status>3</Status>
</TicketsRequest>
the output is:
select
T.TicketID,
T.CreatedAt,
T.Summary,
T.Status,
T.UpdatedAt
from
Data.Ticket T
where
(T.CreatedAt >= convert(datetime2, '2014-01-01T00:00:00', 126)) and
(T.Summary like N'hello%') and
T.Status in
(1, 3, null) and
(1 = 1)
order by
[Status] desc,
(select null)
Though the text is not formatted as we would like, it's perfectly valid SQL.
Tips for building XQuery templates
What is called XQuery in SQL Server is in fact a very limited subset of XQuery 1.0. Microsoft clearly states this fact. What is trivial in XQuery is often impossible or ugly in XQuery of SQL Server.
Nevertheless XQuery in SQL Server works rather well as SQL template language. To make it most efficient, however, you should learn several tips.
Tip #1. Where clause
In template you might want to build a where clause:
<sql>
select
...
where
{
if (...) then
<sql>...</sql>
else ()
}
</sql>
and it might happen that for a certain input a condition under where might collapse, and you will be left with where keyword without a real condition, which is wrong. A simple work around is to always add some true condition under ther where like this:
<sql>
select
...
where
{
if (...) then
<sql>... and </sql>
else ()
} (1 = 1)
</sql>
Tip #2. "in" expression
If you want to generate "in" expression like this:
value in (item1, item2,...)
then you might find that it's much easier generate equivalent a code like this:
value in (item1, item2,..., null).
Here is a XQuery to generate such template:
value in
({
for $item in ... return
<sql><int>{$item}</int>, </sql>
} null) and
Tip #3. Order by
You can conclude an order by clause built from a data with a dummy expression like this:
order by
{
for $item in ... return
<sql>
<name>{$item/Field}</name>
{" desc"[$item/Direction = "Desc"]},
</sql>
} (select null)
Alternatively you can use first column from a clustered index.
Tip #4. Group by
In a group by clause we cannot introduce terminator expression as it was with order by, so a code is a less trivial:
{
let $items := ... return
if ($items) then
<sql>
group by <name>{$items[1]}</name>
{
for $item in $items[position() > 1] return
<sql>, <name>{$item}</name></sql>
}
</sql>
else ()
}
In fact similar logic may work with order by.
Tip #5. Escape literals
It's crusial not to introduce SQL injection while building SQL. Thus use:
<int>{...}</int> - for literal int;
<decimal>{...}</decimal> - for literal decimal;
<string>{...}</string> - for literal string;
<datetime>{...}</datetime> - for literal datetime2;
<date>{...}</date> - for literal date;
<time>{...}</time> - for literal time;
<name>{...}</name> - for a name to quote.
Note that you can use xsi:nil, so
<int xsi:nil="true"/> means null.
If you generate a field name from an input data then it worth to validate it against a list of available names.
Tip #6. Validate input.
It worth to define xml schema for an input xml, and to validate parameters against it.
This makes code more secure, and also adds a documentation.
Tip #7. Don't abuse dynamic SQL
There are not too many cases when you need a dynamic SQL. Usually SQL engine knows how to build a good execution plan. If your query contains optional conditions then you can write it a way that SQL Server can optimize, e.g.:
select
*
from
T
where
((@name is null) or (Name = @name)) and
((@date is null) or (Date = @date))
option(recompile)
Consider how would you implement Style object in the HTML DOM?
These are some characteristics of that object:
- It has a long list of properties, e.g. in IE 11 there are more than 300 properties over a style object.
- Any specific instance usually have only several properties assigned.
- Reads of properties are much more frequent than writes. In fact style often stays unchanged after initialization.
- DOM contains many style instances (often thousands).
- The number of distinct instances in terms of values of properties is moderate (usually dozens).
Here is how would we approached to such an object.
1.
Styles are sparse objects, thus there is no point to implement plain class with all those properties, as it's wasteful.
We would rather use two techniques to keep style's state:
- A dictionary of properties with their values;
- An aggregation of objects, where all properies are grouped into families, each group is defined by a separate type, and a style's state is an aggregation of that groups.
A current style of an element is an aggregation of styles of ancestor element. It can either by dynamic or be fused into a single style instance.
2. Make style's state immutable, and share all these states among all style instances.
In this implementation property write turns into a state transition operation: state = set(state, property, value). Thus no state is modified but replaced with other state that corresponds to a required change.
If state is seen as a dictionary then API may look like this :
public class State<K, V>
{
// Gets shared dictionary for an input dictionary.
public IDictionary<K, V> Get(IDictionary<K, V> dictionary);
// Gets a shared dictionary for an input dictionary with key set to a value.
public IDictionary<K, V> Set(IDictionary<K, V> dictionary, K key, V value);
// Gets a shared dictionary for an input dictionary.
public IDictionary<K, V> Remove(IDictionary<K, V> dictionary, K key);
// Gets typed value.
public T Get<T>(IDictionary<K, V> dictionary, K key)
where T: V
{
V value;
if ((dictionary == null) || !dictionary.TryGetValue(key, out value))
{
return default(T);
}
return (T)value;
}
// Sets or removes a typed value.
// dictionary can be null.
// null returned if output dictionary would be empty.
public IDictionary<K, V> Set<T>(IDictionary<K, V> dictionary,
K key,
T value)
where T : V
{
return value == null ? Remove(dictionary, key) :
Set(dictionary, key, (V)value);
}
}
States can be cached. Provided the cache keeps states in a weak way, no unsued state will be stored for a long time.
We may use weak table of dictionary to dictionary WeakTable<Dictionary<K, V>, Dictionary<K, V>> as a storage for such a cache. All required API is described in the WeakTable and Hash Code of Dictionary posts.
3. Style can be implemented as a structure with shared state as a storage. Here is a scetch:
[Serializable]
public struct Style
{
// All properties.
public enum Property
{
Background,
BorderColor,
BorderStyle,
Color,
FontFamily,
FontSize,
// ...
}
public int? Background
{
get { return states.Get<int?>(state, Property.Background); }
set { state = states.Set(state, Property.Background, value); }
}
public int? BorderColor
{
get { return states.Get<int?>(state, Property.BorderColor); }
set { state = states.Set(state, Property.BorderColor, value); }
}
public string BorderStyle
{
get { return states.Get<string>(state, Property.BorderStyle); }
set { state = states.Set(state, Property.BorderStyle, value); }
}
public int? Color
{
get { return states.Get<int?>(state, Property.Color); }
set { state = states.Set(state, Property.Color, value); }
}
public string FontFamily
{
get { return states.Get<string>(state, Property.FontFamily); }
set { state = states.Set(state, Property.FontFamily, value); }
}
public double? FontSize
{
get { return states.Get<double?>(state, Property.FontSize); }
set { state = states.Set(state, Property.FontSize, value); }
}
// ...
[OnDeserialized]
private void OnDeserialized(StreamingContext context)
{
state = states.Get(state);
}
// A state.
private IDictionary<Property, object> state;
// A states cache.
private static readonly State<Property, object> states =
new State<Property, object>();
}
Note that:
- default state is a
null dictionary;
- states are application wide shared.
The following link is our implementation of State<K, V> class: State.cs.
Here we have outlined the idea of shared state object, and how it can be applied to sparse mostly immutable objects. We used HTML style as an example of such an object. Shared state object may work in many other areas, but for it to shine its use case should fit to the task.
Dealing recently with some task (the same that inspired us to implement WeakTable), we were in a position to use a dictionary as a key in another dictionary.
What are the rules for the class to be used as key:
- key should be immutable;
- key should implement a
GetHashCode() method;
- key should implement a
Equals() method.
The first requirement is usually implemented as a documentation contract like this:
As long as an object is used as a key in the Dictionary<TKey, TValue>, it must not change in any way that affects its hash value.
The third requirement about equals is trivially implemented as a method:
public bool Equals(IDictionary<K, V> x, IDictionary<K, V> y)
{
if (x == y)
{
return true;
}
if ((x == null) || (y == null) || (x.Count != y.Count))
{
return false;
}
foreach(var entry in x)
{
V value;
if (!y.TryGetValue(entry.Key, out value) ||
!valueComparer.Equals(entry.Value, value))
{
return false;
}
}
return true;
}
But how would you implement hash code?
We argued like this.
1. Let's consider the dictionary as a sparse array of values with only populated items that correspond to key hash codes.
2. Hash code is constructed using some fair algorithm. E.g like that used in java to calculate string's hash code:
n-1
h(s) = SUM (s[i]*p^(n-1-i)) mod m, where m = 2^31
i=0
In our case:
n can be arbitrary large int value, so in fact it's 2^32;- items are enumerated in unknown order;
- there is only limited set of items, so most
s[i] are zeros.
As result we cannot use recurrent function to calculate a power p^k mod m. Fortunately one can build fast exponentiation arguing like this:
32/s - 1
p^k = p^ SUM 2^((s*i)*k[i]) mod m, where s some int: 1, 2, 4, 8, 16, or 32.
i=0
Thus
32/s - 1
p^k = PRODUCT (p^(2^(s*i)))^k[i] mod m
i=0
If s = 1 then k[i] is either 1 or 0 (a bit), and there is 32 different p^(2^i) mod m values, which can be precalculated.
On the other hand, if we select s = 8 we can write the formula as:
p^k = p^k[0] * (p^(2^8))^k[1] * (p^(2^16))^k[2] * (p^(2^24))^k[3] mod m
where k[i] is a 8 bit value (byte).
Precalculating all values
p^n, (p^(2^8))^n, (p^(2^16))^n, (p^(2^24))^n for n in 0 to 255 we reach the formula with 4 multiplications and with 1024 precalculated values.
Here is the whole utility to calculate hash factors:
/// <summary>
/// Hash utilities.
/// </summary>
public class Hash
{
/// <summary>
/// Returns a P^value mod 2^31, where P is hash base.
/// </summary>
/// <param name="value">A value to get hash factor for.</param>
/// <returns>A hash factor value.</returns>
public static int GetHashFactor(int value)
{
return factors[(uint)value & 0xff] *
factors[(((uint)value >> 8) & 0xff) | 0x100] *
factors[(((uint)value >> 16) & 0xff) | 0x200] *
factors[(((uint)value >> 24) & 0xff) | 0x300];
}
/// <summary>
/// Initializes hash factors.
/// </summary>
static Hash()
{
var values = new int[4 * 256];
var value = P;
var current = 1;
var i = 0;
do
{
values[i++] = current;
current *= value;
}
while(i < 256);
value = current;
current = 1;
do
{
values[i++] = current;
current *= value;
}
while(i < 512);
value = current;
current = 1;
do
{
values[i++] = current;
current *= value;
}
while(i < 768);
value = current;
current = 1;
do
{
values[i++] = current;
current *= value;
}
while(i < 1024);
factors = values;
}
/// <summary>
/// A base to calculate hash factors.
/// </summary>
public const int P = 1103515245;
/// <summary>
/// Hash factors.
/// </summary>
private static readonly int[] factors;
}
With this API hash code for a dictionary is a trivial operation:
public int GetHashCode(IDictionary<K, V> dictionary)
{
if (dictionary == null)
{
return 0;
}
var result = 0;
foreach(var entry in dictionary)
{
if ((entry.Key == null) || (entry.Value == null))
{
continue;
}
result += Hash.GetHashFactor(keyComparer.GetHashCode(entry.Key)) *
valueComparer.GetHashCode(entry.Value);
}
return result;
}
And finally, here is a reference to a class DictionaryEqualityComparer<K, V>: IEqualityComparer<IDictionary<K, V>> that allows a dictionary to be a key in another dictionary.
Update
We have commited some tests, and have found that with suffiently "good" implementation of GetHashCode() of key or value we achieve results almost of the same quality, as the results of the algorithm we have outlined above with much simpler and straightforward algorithm like this:
public int GetHashCode(IDictionary<K, V> dictionary)
{
if (dictionary == null)
{
return 0;
}
var result = 0;
foreach(var entry in dictionary)
{
if ((entry.Key == null) || (entry.Value == null))
{
continue;
}
var k = entry.Key.GetHashCode();
var v = entry.Value.GetHashCode();
k = (k << 5) + k;
v = (v << (k >> 3)) + v;
result += k ^ v;
//result += Hash.GetHashFactor(keyComparer.GetHashCode(entry.Key)) *
// valueComparer.GetHashCode(entry.Value);
}
return result;
}
It was worth to blog about this just to find out that we have outwitted ourselves, and finally to reach to a trivial hash code implementation for the dictionary.
Dealing recently with some task, we were in a position to use a weak dictionary in the .NET. Instinctively we assumed that it should exist somewhere in the standard library. We definitely knew that there is a WeakReference class to for a single instance. We also knew that there is WeakHashMap in java, and that it's based on java's WeakReference.
So, we were surprised to find that there is no such thing out of the box in .NET.
We have found that java's and .NET's weak references are different. In java weak references whose targets are GCed can be automatically put into a queue, which can be used to build clean up logic to remove dead keys from weak hash map. There is nothing similar in .NET, where weak reference just silently loses it's value.
Internet is full with custom implementations of weak dictionaries in .NET.
.NET 4.5 finally defines a class ConditionalWeakTable<TKey, TValue>, which solves the problem in case when you need to match keys by instance identity.
Unfortunately in our case we needed to match keys using key's GetHashCode() and Equals(). So, ConditionalWeakTable<TKey, TValue> did not directly work, but then we found a way to make it work for us.
Here is a quote from the definition:
A ConditionalWeakTable<TKey, TValue> object is a dictionary that binds a managed object, which is represented by a key, to its attached property, which is represented by a value. The object's keys are the individual instances of the TKey class to which the property is attached, and its values are the property values that are assigned to the corresponding objects.
...in the ConditionalWeakTable<TKey, TValue> class, adding a key/value pair to the table does not ensure that the key will persist, even if it can be reached directly from a value stored in the table... Instead, ConditionalWeakTable<TKey, TValue> automatically removes the key/value entry as soon as no other references to a key exist outside the table.
This property of ConditionalWeakTable<TKey, TValue> has helped us to build a way to get a notification when the key is being finalized, which is the missed ingredient in .NET's weak references.
Assume you have an instance key of type Key. To get a notification you should define a class Finalizer that will call some handler when it's finalized, and you should bind key and a finalizer instance using weak table.
The code looks like this:
public class Finalizer<K>
where K: class
{
public static void Bind(K key, Action<K> handler)
{
var finalizer = table.GetValue(key, k => new Finalizer<K> { key = k });
finalizer.Handler += handler;
}
public static void Unbind(K key, Action<K> handler)
{
Finalizer finalizer;
if (table.TryGetValue(key, out finalizer))
{
finalizer.Handler -= handler;
}
}
~Finalizer()
{
var handler = Handler;
if (handler != null)
{
handler(key);
}
}
private event Action<K> Handler;
private K key;
private static readonly
ConditionalWeakTable<K, Finalizer> table =
new
ConditionalWeakTable<K, Finalizer>();
}
Key key = ...
Finalizer.Bind(key, k => { /* clean up. */ });
Using this approach we have created a class WeakTable<K, V> modeled after ConditionalWeakTable<TKey, TValue>.
So, this is our take in the problem: WeakTable.cs.
Oftentimes we deal with Hebrew in .NET.
The task we face again and again is attempt to convert a Hebrew text from visual to logical representation.
The latest demand of such task was when we processed content extracted from PDF. It's turned out that PDF stores content as graphic primitives, and as result text is stored visually (often each letter is kept separately).
We solved the task more than a decade ago, by calling Uniscribe API.
The function by itself is a small wrapper around that API, so in .NET 1.0 we were using managed C++, several years later we have switched to C++/CLI.
But now after many .NET releases, and with 32/64 versions we can see that C++ is only a guest in .NET world.
To run C++ in .NET you have to install VC runtime libraries adjusted to a specific .NET version. This turns C++ support in .NET into not a trivial task.
So, we have finally decided to define C# interop for the Uniscribe API, and recreate that function in pure C#:
namespace NesterovskyBros.Bidi
{
/// <summary>
/// An utility to convert visual string to logical.
/// <summary>
public static class BidiConverter
{
/// <summary>
/// Converts visual string to logical.
/// </summary>
/// <param name="value">A value to convert.</param>
/// <param name="rtl">A base direction.</param>
/// <param name="direction">
/// true for visual to logical, and false for logical to visual.
/// </param>
/// <returns>Converted string.</returns>
public static string Convert(string value, bool rtl, bool direction);
You can download this project from BidiVisualConverter.zip.
Before to start we have to confess that
afer many years of experience we sincerely dislike JSF technology, as
we think it's outdated compared to html 5 + REST.
We have a JSF 2.2 application, which
is configured to track session through url. In this case Session ID is stored in
url and not in
cookies, as there may be many sessions opened per a client.
At the same time application uses libraries that expose scripts and css
resources. This resources are referred to like this:
<link rel="stylesheet" type="text/css" jsfc="h:outputStylesheet"
library="css"
name="library-name.css"/>
<script type="text/javascript" jsfc="h:outputScript" name="library-name.js"
library="scripts" target="head"></script>
At runtime this is rendered as:
<link type="text/css" rel="stylesheet"
href="/App/javax.faces.resource/library-name.css.jsf;jsessionid=FC4A893330CCE12E8E20DFAFC73CDF35?ln=css"
/>
<script type="text/javascript"
src="/App/javax.faces.resource/library-name.js.jsf;jsessionid=FC4A893330CCE12E8E20DFAFC73CDF35?ln=scripts"></script>
You can see that Session ID is a part of url path,
which prevents resource caching on a client.
It's not clear whether it's what JSF spec dictates or
it's Oracle's Reference Implementation detail. We're certain, however,
that it's
too wasteful in heavy loaded environment, so we have tried to
resolve the problem.
From JSF sources we have found that h:outputStylesheet, h:outputScript,
and h:outputLink all use ExternalContext.encodeResourceURL()
method to build markup url.
So, here is a solution: to provide custom wrapper for the ExternalContext.
This is done in two steps:
- create a factory class;
- register a factory in faces-config.xml;
1. Factory is a simple class but unfortunately it's implementation specific:
package com.nesterovskyBros.jsf;
import javax.faces.FacesException;
import javax.faces.context.ExternalContext;
import javax.faces.context.ExternalContextWrapper;
import com.sun.faces.context.ExternalContextFactoryImpl;
/**
* {@link ExternalContextFactory} to prevent session id in resource urls.
*/
public class ExternalContextFactory extends ExternalContextFactoryImpl
{
/**
* {@inheritDoc}
*/
@Override
public ExternalContext getExternalContext(
Object context,
Object request,
Object response)
throws FacesException
{
final ExternalContext externalContext =
super.getExternalContext(context, request, response);
return new ExternalContextWrapper()
{
@Override
public ExternalContext getWrapped()
{
return externalContext;
}
@Override
public String encodeResourceURL(String url)
{
return shouldEncode(url) ?
super.encodeResourceURL(url) : url;
}
private boolean shouldEncode(String url)
{
// Decide here whether you want to encode
url.
// E.g. in case of h:outputLink you may
want to have session id in url,
// so your decision is based on some
marker (like &session=1) in url.
return false;
}
};
}
}
2. Registration is just three lines in faces-config.xml:
<factory>
<external-context-factory>com.nesterovskyBros.jsf.ExternalContextFactory</external-context-factory>
</factory>
After that change at runtime we have:
<link type="text/css" rel="stylesheet"
href="/App/javax.faces.resource/library-name.css.jsf?ln=css" />
<script type="text/javascript"
src="/App/javax.faces.resource/library-name.js.jsf?ln=scripts"></script>
Till recently we were living in simple world of string comparisons in SQL style,
and now everything has changed.
From the university years we knew that strings in SQL are compared by first
trimming traling spaces, and then comparing in C style.
Well, the picture was a little more complex, as collations were involved
(national, case sensivity), and as different SQL vendors implemented it
differently.
Next,
we're dealing with programs converted from COBOL, which we originally
thought follow SQL rules when strings are compared.
Here is where the problem has started.
Once we have found that java program has branched differently than original
COBOL, and the reason was that the COBOL and java compared two strings
differently:
- COBOL:
"A\n" < "A";
- Java:
"A\n" > "A"
We have looked into
COBOL Language Reference and found the rules:
- Operands of equal size
- Characters in corresponding positions of the two operands are compared,
beginning with the leftmost character and continuing through the rightmost
character.
If all pairs of characters through the last pair test as equal, the operands are
considered as equal.
If a pair of unequal characters is encountered, the characters are tested to
determine their relative positions in the collating sequence. The operand that
contains the character higher in the sequence is considered the greater operand.
- Operands of unequal size
- If the operands are of unequal size, the comparison is made as though the
shorter operand were extended to the right with enough spaces to make the
operands equal in size.
You can see that strings must not be trimmed but padded with spaces
to the longer string, and only then they are compared. This subtle difference
has significant impact for characters below the space.
So, here we've found that COBOL and SQL comparisons are different.
But then we have questioned how really SQL beheaves?
We've tested comparisons in SQL Server and DB2, and have seen that our
understanding of SQL comparison holds. It works as if trimming spaces, and then
comparing.
But again we have looked into SQL-92 definition, and that's what we see there:
8.2 <comparison predicate>
3) The comparison of two character strings is determined as follows:
a) If the length
in characters of X is not equal to the length
in
characters of Y, then the shorter string is effectively
replaced, for the purposes of comparison, with a copy of
itself that has been extended to the length of the longer
string by concatenation on the right of one or more pad characters, where the pad character is chosen based on CS. If
CS
has the NO PAD attribute, then the pad character is an
implementation-dependent character different from any character
in the character set of X and Y that collates less
than
any string under CS. Otherwise, the pad character is a
<space>.
So, what we see is that SQL-92 rules are very close to COBOL rules, but then we
reach the question: how come that at least SQL Server and DB2 implement string
comparison differently than SQL-92 dictates?
Update: we have found that both SQL Server and DB2 have their string collation defined in a way that <space> is less than any other character.
So the following is always true: '[' + char(13) + ']' > '[ ]'.
Earlier we have written a post
KendoUI's slowest function and now,
we want to point to the next slow function, which is kendo.guid().
It's used to assign uid to each observable object, and also in couple
of other places.
Here is its source:
guid: function() {
var id = "", i, random;
for (i = 0; i < 32; i++) {
random = math.random() * 16 | 0;
if (i == 8 || i == 12 || i == 16 || i == 20) {
id += "-";
}
id += (i == 12 ? 4 : (i == 16 ? (random & 3 | 8) : random)).toString(16);
}
return id;
}
KendoUI people have decided to define uid as a string in format of
Globally unique identifier.
We think there is no reason to have such a complex value; it's enough to
have counter to generate uid values. As KendoUI relies
on the string type of uid, so we have defined a patch like this:
var guid = 0
kendo.guid = function()
{ return ++guid + ""
}
Consider now a test case. It's almost identical to that in previous post:
<!DOCTYPE html>
<html>
<head>
<title>Test</title>
<script src="scripts/jquery/jquery.min..js"></script>
<script src="scripts/kendo/kendo.web.min.js"></script>
<link href="styles/kendo.common.min.css" rel="stylesheet" />
<link href="styles/kendo.default.min.css" rel="stylesheet" />
<link href="styles/style.css" rel="stylesheet" />
<script>
var model;
function init()
{
var source = [];
for(var i = 0; i < 1000; ++i)
{
source.push({ text: "value " + i, value: "" + i });
}
model = kendo.observable(
{
value: "1",
source: new kendo.data.DataSource(
{
data: source
})
});
model.source.read();
}
function patch()
{
var base = kendo.data.binders.widget.source.fn._ns;
var result;
var guid = 0;
kendo.guid = function()
{ return ++guid + "";
};
kendo.data.binders.widget.source.fn._ns = function(ns)
{
return ns ? base.call(this, ns) :
(result || (result = base.call(this, ns)));
}
}
function test()
{
init();
kendo.bind("#view", model);
}
patch();
</script>
</head>
<body>
<p>
<button onclick="test()">Click to start test</button>
</p>
<p id="view">
Select:
<input data-role="dropdownlist"
data-bind="value: value, source: source"
data-text-field="text"
data-value-field="value"/>
</p>
</body>
</html>
Now, we can compare performance with and without that patch.
Here is a run statistics without patch:
| Level |
Function |
Count |
Inclusive time (ms) |
Inclusive time % |
Avg time (ms) |
| 1 |
onclick |
1 |
270.73 |
100 |
270.73 |
| 1.1 |
test |
1 |
269.73 |
99.63 |
269.73 |
| 1.1.1 |
init |
1 |
117.07 |
43.24 |
117.07 |
| 1.1.1.1 |
guid |
1,001 |
72.05 |
26.61 |
0.07 |
| 1.1.2 |
bind |
1 |
152.65 |
56.39 |
152.65 |
and with patch:
| Level |
Function |
Count |
Inclusive time (ms) |
Inclusive time % |
Avg time (ms) |
| 1 |
onclick |
1 |
172.64 |
100 |
172.64 |
| 1.1 |
test |
1 |
171.65 |
99.42 |
171.65 |
| 1.1.1 |
init |
1 |
62.04 |
35.94 |
62.04 |
| 1.1.1.1 |
guid |
1,001 |
1 |
0.58 |
0 |
| 1.1.2 |
bind |
1 |
109.6 |
63.49 |
109.6 |
Note that statistics were collected for IE 10.
An example can be found at
slow2.html.
Time after time we run into the same problem on different platforms, with different languages.
The problem's name is "Visual to Logical conversion for right-to-left or bidirectional text".
The problem is usually due to legacy code, which stores texts in visual order from left to right. In case of English it's ok, but with Hebrew this means that texts are partially reversed.
It worth to note that we've solved the same task with Windows API for native and .NET applications more than 10 years ago.
On the other hand, for Java, we yet didn't see any acceptable standalone solution. To remedy this omission,
we publish here our solution to this problem.
package com.nesterovskyBros.text;
import java.text.Bidi;
/**
* Utility that uses {@link Bidi} class.
*/
public class BidiUtils
{
/**
* Implements visual to logical order converter.
*
* @author <a href="http://www.nesterovsky-bros.com">Nesterovsky bros</a>
*
* @param text an input text in visual order to convert.
* @return a String value in logical order.
*/
public static String visualToLogical(String text)
{
if ((text == null) || (text.length() == 0))
{
return text;
}
Bidi bidi = new Bidi(text, Bidi.DIRECTION_DEFAULT_LEFT_TO_RIGHT);
if (bidi.isLeftToRight())
{
return text;
}
int count = bidi.getRunCount();
byte[] levels = new byte[count];
Integer[] runs = new Integer[count];
for (int i = 0; i < count; i++)
{
levels[i] = (byte)bidi.getRunLevel(i);
runs[i] = i;
}
Bidi.reorderVisually(levels, 0, runs, 0, count);
StringBuilder result = new StringBuilder();
for (int i = 0; i < count; i++)
{
int index = runs[i];
int start = bidi.getRunStart(index);
int end = bidi.getRunLimit(index);
int level = levels[index];
if ((level & 1) != 0)
{
for (; --end >= start;)
{
result.append(text.charAt(end));
}
}
else
{
result.append(text, start, end);
}
}
return result.toString();
}
}
This method utilizes embeded Bidi's algorithm, see class
java.text.Bidi.
Be aware that there is no perfect algorithm that covers all possible cases, since BIDI was written for an opposite task,
but our implementation based on Bidi.reorderVisually is usually acceptable.
Here is an JUnit test for this method:
package com.nesterovskyBors.text;
import static org.junit.Assert.*;
import org.junit.Test;
import com.nesterovskyBros.text.BidiUtils;
public class BidiUtilsTests
{
@Test
public void testsVisualToLogical()
{
String text = "123 יתימאה ןחבמ";
String actual = BidiUtils.visualToLogical(text);
String expected = "מבחן האמיתי 123";
assertEquals(expected, actual);
text = "תירבע English תירבע בוש";
actual = BidiUtils.visualToLogical(text);
expected = "שוב עברית English עברית";
assertEquals(expected, actual);
}
}
While developing with KendoUI we have found kendo.ui.progress(container,
toggle) function to be
very useful. It's used to show or hide a progress indicator
in the container element.
At the same time we have found that we usually used it in a context of async
operation. This way, we want to show progress, perform some asynchronous
operations, hide progress. So, we clearly want to benifit from
RAII pattern: we would like to open a progress scope, and to perform some
activity withing this scope.
Arguing like this, we have defined a utility function, which is the fusion of
kendo.ui.progress() and $.when(). Its signature is
like this:
nesterovskyBros.progress = function(instance /*, task ... */)
where instance is either Model, Widget, JQuery or DOM Element,
and task is one or more deferred objects. This function shows a progress
and returns a
Promise that will hide a progress when all tasks will be complete.
Implementation is trivial, so we quote it here:
// Fusion of kendo.ui.progress() and $.when().
scope.progress = function(instance /*, task ... */)
{
if (instance instanceof Model)
{
instance = instance.owner && instance.owner();
}
if (instance instanceof Widget)
{
instance = instance.element;
}
if (instance && instance.nodeType)
{
instance = $(instance);
}
var id = ns + "-progress"; // "nesterovskyBros-progress";
var progress = (instance && instance.data(id)) || 0;
if (arguments.length < 2)
{
return progress;
}
var result = $.when.apply(null, [].slice.call(arguments, 1));
if (instance)
{
instance.data(id, ++progress);
kendo.ui.progress(instance, progress > 0);
result.always(
function()
{
progress = instance.data(id) || 0;
instance.data(id, --progress);
kendo.ui.progress(instance, progress > 0);
});
}
return result;
};
The use is like this:
nesterovskyBros.progress(element, $.ajax("/service1"), $.ajax("/service2")).then(myFunc);
The code can be found at
controls.js.
While trying to generalize our practices from KendoUI related projects we've
participated so far, we updated
control.js - a small javascript additions to KendoUI.
At present we have defined:
1.
An extended model. See KendoUI extended
model.
2.
A lightweight user control - a widget to bind a template and a model, and to
facilitate declarative instantiation. See KendoUI User control.
3.
A reworked version of nesterovskyBros.defineControl() function.
var widgetType = scope.defineControl(
{
name:
widget-name-string,
model: widget-model-type,
template: optional-content-template,
windowOptions: optional-window-options
},
base);
When optional-content-template is not specified then template is
calculated as following:
var template = options.temlate || proto.template || model.temlate;
if (template === undefined)
{
template = scope.template(options.name.toLowerCase() + "-template");
}
When windowOptions is specified then
widgetType.dialog(options) function is defined. It's used to open dialog based on
the specified user control. windowOptions is passed to kendo.ui.Window
constructor. windowOptions.closeOnEscape indicates whether to close opened dialog on escape.
widgetType.dialog() returns a kendo.ui.Window instance with content based on the
user control. Window instance contains functions:
result() - a $.Deffered for
the dialog result, and model() - referring to the user control model.
The model
instance has functions:
-
dialog() referring to the dialog, and
result() referring
to the dialog result.
widget.dialog() allows all css units in windowOptions.width and windowOptions.height
parameters.
base - is optional user control base. It defaults to nesterovskyBros.ui.UserControl.
4. Adjusted splitter. See Adjust KendoUI
Splitter.
5. Auto resize support.
Layout is often depends on available area. One example is Splitter widget that
recalculates its panes when window or container Splitter is resized.
There are other cases when you would like to adjust layout when a container's
area is changed like: adjust grid, tab, editor or user's control contents.
KendoUI does not provide a solution for this problem, so we have defined our
own.
- A widget can be marked with
class="auto-resize" marker;
- A widget may define a
widgetType.autoResize(element) function that adapts widget to a new size.
- A code can call
nesterovskyBros.resize(element) function at trigger resizing of the subtree.
To support existing controls we have defined autoResize() function for Grid,
Splitter, TabStrip, and Editor widgets.
To see how auto resizing works, it's best to look into
index.html,
products.tmpl.html, and into the implementation
controls.js.
Please note that we consider
controls.js as an addition to KendoUI library. If in the future the library
will integrate or implement similar features we will be happy to start using
their API.
See also: Compile KendoUI templates.
We heavily use kendo.ui.Splitter widget. Unfortunately it has several drawbacks:
- you cannot easily configure panes declaratively;
- you cannot define a pane that takes space according to its content.
Although we don't like to patch widgets, in this case we found no better
way but to patch two functions: kendo.ui.Splitter.fn._initPanes,
and kendo.ui.Splitter.fn._resize.
After the fix, splitter markup may look like the following:
<div style="height: 100%"
data-role="splitter"
data-orientation="vertical">
<div data-pane='{ size: "auto", resizable: false, scrollable: false }'>
Header with size depending on content.
</div>
<div data-pane='{ resizable: false, scrollable: true }'>
Body with size equal to a remaining area.
</div>
<div data-pane='{ size: "auto", resizable: false, scrollable: false }'>
Footer with size depending on content.
</div>
</div>
Each pane may define a data-pane attribute with pane parameters. A pane may
specify size = "auto" to take space according to its content.
The code can be found at
splitter.js A test can be seen at
splitter.html.
Although WCF REST service + JSON is outdated comparing to Web API, there are yet a lot of such solutions (and probably will appear new ones) that use such "old" technology.
One of the crucial points of any web application is an error handler that allows gracefully resolve server-side exceptions and routes them as JSON objects to the client for further processing. There are dozen approachesin Internet that solve this issue (e.g. http://blog.manglar.com/how-to-provide-custom-json-exceptions-from-as-wcf-service/), but there is no one that demonstrates error handling ot the client-side. We realize that it's impossible to write something general that suits for every web application, but we'd like to show a client-side error handler that utilizes JSON and KendoUI.
On our opinion, the successfull error handler must display an understandable error message on one hand, and on the other hand it has to provide technical info for developers in order to investigate the exception reason (and to fix it, if need):
You may download demo project here. It contains three crucial parts:
- A server-side error handler that catches all exceptions and serializes them as JSON objects (see /Code/JsonErrorHandler.cs and /Code/JsonWebHttpBehaviour.cs).
- An error dialog that's based on user-control defined in previous articles (see /scripts/controls/error.js, /scripts/controls/error.resources.js and /scripts/templates/error.tmpl.html).
- A client-side error handler that displays errors in user-friendly's manner (see /scripts/api/api.js, method defaultErrorHandler()).
Of course this is only a draft solution, but it defines a direction for further customizations in your web applications.
Useful links to those who are still dealing with Cool:GEN.
The site is not cool by itself, but the value is in the tools that authors provide to simplify Cool:GEN development. Especially we would like to mention:
- GuardIEn - Version control, change and model management and automated builds for CA Gen, and
- VerifIEr - Automated code checking and standards verification.
These tools help to manage clean and error free models, which simplifies next migration to Java and C# that we perform.
To simplify KendoUI development we have defined nesterovskyBros.data.Model, which extends kend.data.Model class.
Extensions in nesterovskyBros.data.Model
- As with
kendo.data.Model there is fields Object - a set of key/value pairs to configure the model fields, but fields have some more options:
fields.fieldName.serializable Boolean - indicates whether the field appears in an object returned in model.toJSON(). Default is true.fields.fieldName.updateDirty Boolean - indicates whether the change of the property should trigger dirty field change. Default is true.
- When model defines a field and there is a prototype function with the same name then this function is used to get and set a field value.
- When property is changed through the
model.set() method then dirty change event is triggered (provided that fields.fieldName.updateDirty !== false). This helps to build a dependcy graph on that property.
- When model instance is consturcted, the data passed in are validated, nullable and default values are set.
Model example
Here is an example of a model:
nesterovskyBros.data.ProductModel = nesterovskyBros.data.Model.define(
{
fields:
{
name: { type: "string", defaultValue: "Product Name" },
price: { type: "number", defaultValue: 10 },
unitsInStockValue: { type: "number", defaultValue: 10, serializable: false },
unitsInStock: { type: "string" }
},
unitsInStock: function(value)
{
if (value === undefined)
{
var count = this.get("unitsInStockValue");
return ["one", "two", "three", "four"][count] || (count + "");
}
else
{
this.set("unitsInStockValue", ({one: 1, two: 2, three: 3, four: 4 })[value] || value);
}
}
});
Notice that:
unitsInStock property is implemented as a function - this helps to map model values to presentation values. - when you call
model.toJSON(), or JSON.stringify() you will see in result name, price, unitsInStock values only - this helps to get model's state and to store it somewhere (e.g. in sessionStorage).
- in a code:
var model = new nesterovskyBros.data.ProductModel({ price: "7", unitsInStock: "one" });
the following is true:
(typeof(model.price) == "number") && (mode.price == 7) && (model.name == "Product Name") && (model.unitsInStockValue == 1)
As with UserControl the implemntation is defined in the controls.js. The sample page is the same index.html
Developing with KendoUI we try to formalize tasks. With this in mind we would like to have user controls.
We define user control as following:
It is a javascript class that extends Widget.
It offers a way to reuse UI.
It allows to define a model and a template with UI and data binding.
Unfortunately, KendoUI does not have such API, though one can easily define it; so we have defined our version.
Here we review our solution. We have taken a grid KendoUI example and converted it into a user control.
User control on the page
See index.html
<!DOCTYPE html>
<html>
<head>
<title>Test</title>
<!-- (1) Include templates for controls. -->
<script src="scripts/templates.js"></script>
<script src="scripts/jquery/jquery.js"></script>
<script src="scripts/kendo/kendo.web.min.js"></script>
<!-- (2) UserControl definition. -->
<script src="scripts/controls.js"></script>
<!-- (3) Confirm dialog user control. -->
<script src="scripts/controls/confirm.js"></script>
<!-- (4) Products user control. -->
<script src="scripts/controls/products.js"></script>
<link href="styles/kendo.common.min.css" rel="stylesheet" />
<link href="styles/kendo.default.min.css" rel="stylesheet" />
<script>
$(function ()
{
// (5) Bind the page.
kendo.bind(
document.body,
// (6) Model as a datasource.
{ source: [new nesterovskyBros.data.ProductsModel] });
});
</script>
</head>
<body>
<!-- (7) User control and its binding. -->
<div data-role="products" data-bind="source: source"></div>
</body>
</html>
That's what
we see here:
- Templates that define layouts. See "How To: Load KendoUI Templates from External Files", and templates.tt.
- Definition of the UserControl widget.
- Confirm dialog user control (we shall mention it later).
- Products user control.
- Data binding that instantiates page controls.
- Model is passed to a user control through the dataSource.
- Use of Products user control. Notice that "data-role" defines control type, "source" refers to the model.
User Control declaration
Declaration consists of a view and a model.
View is html with data binding. See products.tmpl.html
We build our project using Visual Studio, so templates packaging is done with templates.tt. This transformation converts products template into a tag:
<script id="products-template" type="text/x-kendo-template">
thus template can be referred by a utility function: nesterovskyBros.template("products-template").
Model inherits kedo.data.Model. Here how it looks:
// (1) Define a ProducsModel class.
nesterovskyBros.data.ProductsModel = kendo.data.Model.define(
{
// (2) Model properties.
fields:
{
productName: { type: "string", defaultValue: "Product Name" },
productPrice: { type: "number", defaultValue: 10 },
productUnitsInStock: { type: "number", defaultValue: 10 },
products: { type: "default", defaultValue: [] }
},
// (3) Model methods.
addProduct: function ()
{
...
},
deleteProduct: function (e)
{
...
},
...
});
// (4) Register user control.
nesterovskyBros.ui.Products = nesterovskyBros.defineControl(
{
name: "Products",
model: nesterovskyBros.data.ProductsModel
});
That's what we have here:
- We define a model that inherits KendoUI Model.
- We define model fields.
- We define model methods.
- Register user control with
nesterovskyBros.defineControl(proto) call, where:
proto.name - defines user control name;proto.model - defines model type;proto.template - defines optional template. If not specified, a template is retrieved from $("#" + proto.name.toLowerCase() + "-template").html().
UserControl API
Now, what's remained is API for the UserControl. See controls.js.
- UserControl defines following events:
change - triggered when data source is changed;dataBound - triggered when widget is data bound;dataBinding - triggered befor widget data binding;save - used to notify user to save model state.
- UserControl defines following options:
autoBind (default false) - autoBind data source;template (default $.noop) - user control template.
- UserControl defines
dataSource field and setDataSource() method.
- UserControl defines
rebind() method to manually rebuild widget's view from the template and model.
- UserControl sets/deletes model.owner, which is a function returning a user control widget when model is bound/unbound to the widget.
- When UserControl binds/unbinds model a
model.refresh method is called, if any.
- You usually define you control with a call
nesterovskyBros.defineControl(proto). See above.
- There is also a convenience method to build a dialog based on a user control: nesterovskyBros.defineDialog(options), where
options.name - a user control name (used in the data-role);options.model - a model type;options.windowOptions - a window options.
This method returns a function that recieves a user control model, and returns a dialog (kendo.ui.Window) based on the user control.
Dialog has model() function that returns an instance of model.
Model has dialog() function that returns an instance of the dialog.
Dialog and model have result() function that returns an instance of deferred object used to track dialog completion.
The example of user control dialog is confirm.js and confirm.tmpl.html.
The use is in the products.js deleteProduct():
deleteProduct: function(e)
{
var that = this;
return nesterovskyBros.dialog.confirm(
{
title: "Please confirm",
message: "Do you want to delete the record?",
confirm: "Yes",
cancel: "No"
}).
open().
center().
result().
then(
function(confirmed)
{
if (!confirmed)
{
return;
}
...
});
}
Last
User controls along with technique to manage and cache templates allow us to build robust web applications. As the added value it's became a trivial task to build SPA.
See also: Compile KendoUI templates.
Kendo UI Docs contains an article "How To:
Load Templates from External Files", where authors review two way of dealing
with Kendo UI templates.
While using Kendo UI we have found our own answer to: where will the Kendo
UI templates be defined and maintained?
In our .NET project we have decided to keep templates separately, and to store
them under the "templates" folder. Those templates are in fact include html,
head, and stylesheet links. This is to help us to present those tempates in the
design view.
In our scripts folder, we have defined a small text transformation template:
"templates.tt", which produces "templates.js" file. This template takes body
contents of each "*.tmpl.html" file from "templates" folder and builds string of
the form:
document.write('<script id="footer-template" type="text/x-kendo-template">...</script><script id="row-template" type="text/x-kendo-template">...</script>');
In our page that uses templates, we include "templates.js":
<!DOCTYPE html>
<html>
<head>
<script
src="scripts/templates.js"></script>
...
Thus, we have:
- clean separation of templates and page content;
- automatically generated templates include file.
WebTemplates.zip contains a web project demonstrating our technique. "templates.tt" is
text template transformation used in the project.
See also: Compile KendoUI templates.
Two monthes ago we have started
a process of changing column type from smallint to int in a big database.
This was splitted in two phases:
- Change tables and internal stored procedures and functions.
- Change interface API and update all clients.
The first part took almost two monthes to complete. Please read earlier post about
the technique we have selected for the implementation. In total we have transferred
about 15 billion rows. During this time database was online.
The second part was short but the problem was that we did not control all clients,
so could not arbitrary change types of parameters and of result columns.
All our clients use Entity Framework 4 to access the database. All access is done
though stored procedures. So suppose there was a procedure:
create procedure Data.GetReports(@type smallint) as
begin
select Type, ... from Data.Report where Type = @type;
end;
where column "Type" was of type smallint. Now
we were going to change it to:
create procedure Data.GetReports(@type int) as
begin
select Type, ... from Data.Report where Type = @type;
end;
where "Type" column became of type int.
Our tests have shown that EF bears with change of types of input parameters, but throws
exceptions when column type has been changed, even when a value fits the
range. The reason is that EF uses method SqlDataReader.GetInt16
to access the column value. This method has a remark: "No
conversions are performed; therefore, the data retrieved must already be a 16-bit
signed integer."
Fortunately, we have found that EF allows additional columns in the result set. This helped us to formulate the solution.
We have updated the procedure definition like this:
create procedure Data.GetReports(@type int) as
begin
select
cast(Type as smallint) Type, -- deprecated
Type TypeEx, ...
from
Data.Report
where
Type = @type;
end;
This way:
- result column
"Type" is declared as deprecated;
- old clients still work;
- all clients should be updated to use
"TypeEx" column;
- after all clients will be updated we shall remove
"Type" column from the result
set.
So there is a clear migration process.
P.S. we don't understand why SqlDataReader doesn't support value
conversion.
Recently we had a discussion with DBA regarding optimization strategey we have
selected for some queries.
We have a table in our database. These are facts about that table:
- the table is partitioned by date;
- each partition contains a month worth of data;
- the table contains at present about 110 million rows;
- the table ever grows;
- the table is most accessed in the database;
- the most accessed part of the data is related to last 2-3 days,
which is about 150000 rows.
The way we have optimized access to that table was a core of the dispute.
We have created filtered index that includes data for the last 3 days.
To achieve desired effect we had to:
- create a job that recreates that index once a day, as filter condition is
moving;
- adjust queries that access the table, as we had to use several access pathes
to the table depending on date.
As result we can see that under the load, stored procedures that access that table
became almost 50% faster. On the other hand maintainance became more
complicated.
DBA who didn't like the database complications had to agree that there are speed
improvements. He said that there should be a better way to achieve the same
effect but could not find it.
Are there a better way to optimize access to this table?
We're implementing UDT changes in the big database. Earlier, that
User Defined Type was based on smallint, and now we have to use int as the base.
The impact
here is manyfold:
- Clients of the database should be prepared to use wider types.
- All stored procedures, functions, triggers, and views should be updated
accordingly.
- Impact on the database size should be analyzed.
- Types of columns in tables should be changed.
- Performance impact should be minimal.
Now, we're trying to address (3),
(5) and to implement (4), while trying to keep interface with clients using old
types.
As for database size impact, we have found that an index fragmentation is a
primary disk space waster (see Reorganize index in SQL Server).
We have performed some partial index reorganization and can see now that we can gain
back hundreds of GB of a disk space. On the other hand we use page compression, so we expect that change of types will not increase
sizes of tables considerably. Indeed, our measurments show that tables will only be
~1-3% bigger.
The change of types of columns is untrivial task. The problem is that if you try
to change column's type (which is part of clustered index) directly then you
should temporary remove foreign keys, and to rebuild all indices. This won't
work neither due to disk space required for the operation (a huge transaction
log is required), nor due to availability of tables (we're talking about days or
even weeks to rebuild indices).
To work-around the problem we have selected another way. For each target table T
we performed the following:
- Renamed table T to T_old;
- Created a table T_new with required type changes;
- Created a view named T, which is union of T_old for the dates before a split
date and T_new for the dates after the split date;
- Created instead of insert/update/delete triggers for the view T.
- Created a procedures that move data in bulks from T_old to the T_new, update
split date in view definitions, and delete data from T_old.
Note that:
- the new view uses wider column types, so we had to change stored
procedures that clients use to cast those columns back to shorter types to
prevent side effects (fortunately all access to this database is through stored
procedures and functions);
- the procedures that transfer data between new and old tables may work online;
- the quality of execution plans did not degrade due to switch from table to a
view;
- all data related to the date after the split date are inserted into T_new
table.
After transfer will be complete we shall drop T_old tables, and T views, and
will rename T_new tables into T.
This will complete part 4 of the whole task. Our estimations are that it will
take a month or even more to complete the transfer. However solution is rather
slow, the database will stay online whole this period, which is required
condition.
The next task is to deal with type changes in parameters of stored procedures
and column types of output result sets. We're not sure yet what's the best way
to deal with it, and probably shall complain about in in next posts.
Back in 2006 and 2007 we have defined dbo.Numbers function:
Numbers table in SQL Server 2005,
Parade of numbers. Such construct is very important in a set based
programming. E.g. XPath 2 contains a range expression like this: "1 to 10" to
return a sequence of numbers.
Unfortunately neither SQL Server 2008 R2, nor SQL Server 2012 support such
construct, so dbo.Numbers function is still actual.
After all these years the function evolved a little bit to achieve a better
performance. Here is its source:
-- Returns numbers table.
-- Table has a following structure: table(value int not null);
-- value is an integer number that contains numbers from 1 to a specified value.
create function dbo.Numbers
(
-- Number of rows to return.
@count int
)
returns table
as
return
with Number8 as
(
select
*
from
(
values
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)
) N(Value)
),
Number32(Value) as
(
select
0
from
Number8 N1
left join
Number8 N2
on
@count > 0x100
left join
Number8 N3
left join
Number8 N4
on
@count > 0x1000000
on
@count > 0x10000
)
select top(@count) row_number() over(order by @count) Value from Number32;
We're working with an online database, which is ever populated with a new
data. Database activity is mostly around recent data. Activity against older
data declines with increasing the distance from today. The ratio of an amount of a
new data, say for a last month, to the whole data, at present stays at
~1%. The size of database is measured in TBs.
While we're developers and not DBA's, you will see from
a later blog
posts why we're bothered with the database size. In short we're planning to
change some UDF type from smallint to int. This will impact
on many tables, and the task now is to estimate that impact.
Our first attempts to measure the difference between table sizes before and
after type change showed that a data fragmentation often masks the difference, so
we started to look at a way to reduce fragmentation.
Internet is full with recomentations. An advice can be found in BOL at
Reorganize
and Rebuild Indexes.
So, our best help in this task is the function sys.dm_db_index_physical_stats,
which reports statistics about fragmentation.
Analysing what that function has given to us we could see that we had a highly
fragmented data. There was no reason to bear with that taking into an account that
the most of the data stored in the database is historical, which is rarely
accessed and even more rarely updated.
The next simplest instument adviced is:
alter index { index_name | ALL } on <object> reorganize [ PARTITION = partition_number ];
The less trivial but often more efficient instrument is the use of online index
rebuild and index reorganize depending on index type and a level of
fragmentation.
All in all our estimation is that rebuilding or reorganizing indices frees
~100-200GBs of disk space. While, it's only a small percent of total database
size, it gives us several monthes worth of a disk space!
Earlier we overlooked SQL Server API to monitor fragmentation, rebuild, and
reorganize indices, and now we're going to create a job that will regulary
defragment the database.
We have a large table in the form:
create table dbo.Data
(
Date date not null,
Type int not null,
Value nvarchar(50) null,
primary key clustered(Date, Type)
);
create unique nonclustered index IX_Data on dbo.Data(Type, Date);
Among other queries we often need a snapshot of data per each Type for a latest
Date available:
select
max(Date) Date,
Type
from
dbo.Data
group by
Type
We have
found that the above select does not run well on our data set. In fact dbo.Data
grows with time, while snapshot we need stays more or less of the same size. The
best solution to such query is to precalculate it. One way would be to create an
indexed view, but SQL Server does not support max() aggregate in indexed views.
So, we have decided to add additional bit field dbo.Data.Last indicating that
a row belongs to a last date snapshot, and to create filtered index to access
that snapshot:
create table dbo.Data
(
Date date not null,
Type int not null,
Value nvarchar(50) null,
Last bit not null default 0,
primary key clustered(Date, Type)
);
create unique nonclustered index IX_Data on dbo.Data(Type, Date);
create unique nonclustered index IX_Data_Last on dbo.Data(Type)
include(Date)
where Last = 1;
One way to support Last indicator is to create a trigger that will adjust Last
value:
create trigger dbo.Data_Update on dbo.Data
after insert,delete,update
as
begin
if (trigger_nestlevel(@@procid) < 2)
begin
set nocount on;
with
D as
(
select Date, Type from deleted
union
select Date, Type from inserted
),
U as
(
select
V.Date, V.Type
from
D
inner join
dbo.Data V
on
(V.Last = 1) and
(V.Type = D.Type)
union
select
max(V.Date) Date,
V.Type
from
D
inner join
dbo.Data V
on
V.Type = D.Type
group by
V.Type
),
V as
(
select
rank()
over(partition by
V.Type
order by
V.Date desc) Row,
V.*
from
dbo.Data V
inner join
U
on
(V.Date = U.Date) and
(V.Type = U.Type)
)
update V
set
Last = 1 - cast(Row - 1 as bit);
end;
end;
With Last indicator in action, our original query has been transformed to:
select Date, Type
from dbo.Data where Last = 1
Execution plan shows that a new filtered index
IX_Data_Last is used. Execution speed has increased considerably.
As our actual table contains other bit fields, so Last
indicator did not
increase the table size, as SQL Server packs each 8 bit fields in one byte.
Earlier we have shown
how to build streaming xml reader from business data and have reminded about
ForwardXPathNavigator which helps to create
a streaming xslt transformation. Now we want to show how to stream content
produced with xslt out of WCF service.
To achieve streaming in WCF one needs:
1. To configure service to use streaming. Description on how to do this can be
found in the internet. See web.config of the sample
Streaming.zip for the details.
2. Create a service with a method returning Stream:
[ServiceContract(Namespace = "http://www.nesterovsky-bros.com")]
[AspNetCompatibilityRequirements(RequirementsMode = AspNetCompatibilityRequirementsMode.Allowed)]
public class Service
{
[OperationContract]
[WebGet(RequestFormat = WebMessageFormat.Json)]
public Stream GetPeopleHtml(int count,
int seed)
{
...
}
}
2. Return a Stream from xsl transformation.
Unfortunately (we mentioned it already), XslCompiledTransform generates its
output into XmlWriter (or into output Stream) rather than exposes result as
XmlReader, while WCF gets input stream and passes it to a client.
We could generate xslt output into a file or a memory Stream and then return
that content as input Stream, but this will defeat a goal of streaming, as
client would have started to get data no earlier that the xslt completed its
work. What we need instead is a pipe that form xslt output Stream to an input
Stream returned from WCF.
.NET implements pipe streams, so our task is trivial.
We have defined a utility method that creates an input Stream from a generator
populating an output Stream:
public static Stream GetPipedStream(Action<Stream> generator)
{
var output = new AnonymousPipeServerStream();
var input = new AnonymousPipeClientStream(
output.GetClientHandleAsString());
Task.Factory.StartNew(
() =>
{
using(output)
{
generator(output);
output.WaitForPipeDrain();
}
},
TaskCreationOptions.LongRunning);
return input;
}
We wrapped xsl transformation as such a generator:
[OperationContract]
[WebGet(RequestFormat = WebMessageFormat.Json)]
public Stream GetPeopleHtml(int count, int seed)
{
var context = WebOperationContext.Current;
context.OutgoingResponse.ContentType = "text/html";
context.OutgoingResponse.Headers["Content-Disposition"] =
"attachment;filename=reports.html";
var cache = HttpRuntime.Cache;
var path = HttpContext.Current.Server.MapPath("~/People.xslt");
var transform = cache[path] as XslCompiledTransform;
if (transform == null)
{
transform = new XslCompiledTransform();
transform.Load(path);
cache.Insert(path, transform, new CacheDependency(path));
}
return Extensions.GetPipedStream(
output =>
{
// We have a streamed business data.
var people = Data.CreateRandomData(count, seed, 0, count);
// We want to see it as streamed xml data.
using(var stream =
people.ToXmlStream("people", "http://www.nesterovsky-bros.com"))
using(var reader = XmlReader.Create(stream))
{
// XPath forward navigator is used as an input source.
transform.Transform(
new ForwardXPathNavigator(reader),
new XsltArgumentList(),
output);
}
});
}
This way we have build a code that streams data directly from business data to a
client in a form of report. A set of utility functions and classes helped us to
overcome .NET's limitations and to build simple code that one can easily
support.
The sources can be found at
Streaming.zip.
In the previous
post about streaming we have dropped at the point where we have XmlReader
in hands, which continously gets data from IEnumerable<Person>
source.
Now we shall remind about ForwardXPathNavigator - a class we have built
back in 2002, which adds streaming transformations to .NET's xslt processor.
While XslCompiledTransform is desperately obsolete, and no upgrade
will possibly follow; still it's among the fastest xslt 1.0 processors. With
ForwardXPathNavigator we add ability to transform input data of arbitrary size to this processor.
We find it interesting that
xslt 3.0 Working Draft defines streaming processing in a way that closely
matches rules for ForwardXPathNavigator:
Streaming achieves two important objectives: it allows large documents to be transformed
without requiring correspondingly large amounts of memory; and it allows the processor
to start producing output before it has finished receiving its input, thus reducing
latency.
The rules for streamability, which are defined in detail in 19.3 Streamability
Analysis, impose two main constraints:
-
The only nodes reachable from the node that is currently being processed are its
attributes and namespaces, its ancestors and their attributes and namespaces, and
its descendants and their attributes and namespaces. The siblings of the node, and
the siblings of its ancestors, are not reachable in the tree, and any attempt to
use their values is a static error. However, constructs (for example, simple forms
of xsl:number, and simple positional patterns) that require knowledge
of the number of preceding elements by name are permitted.
-
When processing a given node in the tree, each descendant node can only be visited
once. Essentially this allows two styles of processing: either visit each of the
children once, and then process that child with the same restrictions applied; or
process all the descendants in a single pass, in which case it is not possible while
processing a descendant to make any further downward selection.
The only significant difference between ForwardXPathNavigator and
xlst 3.0 streaming is in that we reported violations of rules for streamability
at runtime, while xslt 3.0 attempts to perform this analysis at compile time.
Here the C# code for the xslt streamed transformation:
var transform = new XslCompiledTransform();
transform.Load("People.xslt");
// We have a streamed business data.
var people = Data.CreateRandomData(10000, 0, 0, 10000);
// We want to see it as streamed xml data.
using(var stream =
people.ToXmlStream("people", "http://www.nesterovsky-bros.com"))
using(var reader = XmlReader.Create(stream))
using(var output = File.Create("people.html"))
{
// XPath forward navigator is used as an input source.
transform.Transform(
new ForwardXPathNavigator(reader),
new XsltArgumentList(),
output);
}
Notice how XmlReader is wrapped into ForwardXPathNavigator.
To complete the picture we need xslt that follows the streaming rules:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:d="http://www.nesterovsky-bros.com"
exclude-result-prefixes="msxsl d">
<xsl:output method="html" indent="yes"/>
<!-- Root template processed in the streaming mode. -->
<xsl:template match="/d:people">
<html>
<head>
<title>List of persons</title>
<style type="text/css">
.even
{
}
.odd
{
background: #d0d0d0;
}
</style>
</head>
<body>
<table border="1">
<tr>
<th>ID</th>
<th>First name</th>
<th>Last name</th>
<th>City</th>
<th>Title</th>
<th>Age</th>
</tr>
<xsl:for-each select="d:person">
<!--
Get element snapshot.
A
snapshot allows arbitrary access to the element's content.
-->
<xsl:variable name="person">
<xsl:copy-of select="."/>
</xsl:variable>
<xsl:variable name="position" select="position()"/>
<xsl:apply-templates mode="snapshot" select="msxsl:node-set($person)/d:person">
<xsl:with-param name="position" select="$position"/>
</xsl:apply-templates>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
<xsl:template mode="snapshot" match="d:person">
<xsl:param name="position"/>
<tr>
<xsl:attribute name="class">
<xsl:choose>
<xsl:when test="$position mod 2 = 1">
<xsl:text>odd</xsl:text>
</xsl:when>
<xsl:otherwise>
<xsl:text>even</xsl:text>
</xsl:otherwise>
</xsl:choose>
</xsl:attribute>
<td>
<xsl:value-of select="d:Id"/>
</td>
<td>
<xsl:value-of select="d:FirstName"/>
</td>
<td>
<xsl:value-of select="d:LastName"/>
</td>
<td>
<xsl:value-of select="d:City"/>
</td>
<td>
<xsl:value-of select="d:Title"/>
</td>
<td>
<xsl:value-of select="d:Age"/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
So, we have started with a streamed entity data, proceeded to the streamed
XmlReader and reached to the streamed xslt transformation.
But at the final post about streaming we shall remind a simple way of building
WCF service returning html stream from our xslt transformation.
The sources can be found at
Streaming.zip.
If you're using .NET's IDictionary<K, V> you have probably found
its access API too boring. Indeed at each access point you have to write a code
like this:
MyValueType value;
var hasValue = dictionary.TryGetValue(key, out value);
...
In many, if not in most, cases the value is of a reference type, and you do not
usually store null values, so it would be fine if dictionary
returned null when value does not exist for the key.
To deal with this small nuisance we have declared a couple of accessor
extension methods:
public static class Extensions
{
public static V Get<K, V>(this IDictionary<K, V> dictionary, K key)
where V: class
{
V value;
if (key == null)
{
value = null;
}
else
{
dictionary.TryGetValue(key, out value);
}
return value;
}
public static V Get<K, V>(this IDictionary<K, V> dictionary, K? key)
where V: class
where K: struct
{
V value;
if (key == null)
{
value = null;
}
else
{
dictionary.TryGetValue(key.GetValueOrDefault(), out value);
}
return value;
}
}
These methods simplify dictionary access to:
var value = dictionary.Get(key);
...
For some reason neither .NET's XmlSerializer nor DataContractSerializer allow
reading data through an XmlReader. These APIs work other way round writing data
into an XmlWriter. To get data through XmlReader one needs to write it to some
destination like a file or memory stream, and then to read it using XmlReader.
This complicates streaming design considerably.
In fact the very same happens with other .NET APIs.
We think the reason of why .NET designers preferred XmlWriter to XmlReader in
those APIs is that XmlReader's implementation is a state machine like, while
XmlWriter's implementation looks like a regular procedure. It's much harder to
manually write and to support a correct state machine logic
than a procedure.
If history would have gone slightly
different way, and if yield return, lambda, and Enumerator API appeared before
XmlReader, and XmlWriter then, we think, both these classes looked differently.
Xml source would have been described with a IEnumerable<XmlEvent> instead of
XmlReader, and XmlWriter must be looked like a function receiving
IEnumerable<XmlEvent>. Implementing XmlReader would have meant a creating a
enumerator. Yield return and Enumerable API would have helped to implement it in
a procedural way.
But in our present we have to deal with the fact that DataContractSerializer
should write the data into XmlWriter, so let's assume we have a project that
uses Entity Framework to access the database, and that you have a data class
Person, and data access method GetPeople():
[DataContract(Name = "person", Namespace = "http://www.nesterovsky-bros.com")]
public class Person
{
[DataMember] public int Id { get; set; }
[DataMember] public string FirstName { get; set; }
[DataMember] public string LastName { get; set; }
[DataMember] public string City { get; set; }
[DataMember] public string Title { get; set; }
[DataMember] public DateTime BirthDate { get; set; }
[DataMember] public int Age { get; set; }
}
public static IEnumerable<Person> GetPeople() { ... }
And your goal is to expose result of GetPeople() as XmlReader.
We achieve result with three simple steps:
- Define
JoinedStream - an input Stream implementation that
reads data from a enumeration of streams (IEnumerable<Stream>).
- Build xml parts in the form of
IEnumerable<Stream>.
- Combine parts into final xml stream.
The code is rather simple, so here we qoute its essential part:
public static class Extensions
{
public static Stream JoinStreams(this IEnumerable<Stream> streams, bool closeStreams = true)
{
return new JoinedStream(streams, closeStreams);
}
public static Stream ToXmlStream<T>(
this IEnumerable<T> items,
string rootName = null,
string rootNamespace = null)
{
return items.ToXmlStreamParts<T>(rootName, rootNamespace).
JoinStreams(false);
}
private static IEnumerable<Stream> ToXmlStreamParts<T>(
this IEnumerable<T> items,
string rootName = null,
string rootNamespace = null)
{
if (rootName == null)
{
rootName = "ArrayOfItems";
}
if (rootNamespace == null)
{
rootNamespace = "";
}
var serializer = new DataContractSerializer(typeof(T));
var stream = new MemoryStream();
var writer = XmlDictionaryWriter.CreateTextWriter(stream);
writer.WriteStartDocument();
writer.WriteStartElement(rootName, rootNamespace);
writer.WriteXmlnsAttribute("s", XmlSchema.Namespace);
writer.WriteXmlnsAttribute("i", XmlSchema.InstanceNamespace);
foreach(var item in items)
{
serializer.WriteObject(writer, item);
writer.WriteString(" ");
writer.Flush();
stream.Position = 0;
yield return stream;
stream.Position = 0;
stream.SetLength(0);
}
writer.WriteEndElement();
writer.WriteEndDocument();
writer.Flush();
stream.Position = 0;
yield return stream;
}
private class JoinedStream: Stream
{
public JoinedStream(IEnumerable<Stream> streams, bool closeStreams = true)
...
}
}
The use is even more simple:
// We have a streamed business data.
var people = GetPeople();
// We want to see it as streamed xml data.
using(var stream = people.ToXmlStream("persons", "http://www.nesterovsky-bros.com"))
using(var reader = XmlReader.Create(stream))
{
...
}
We have packed the sample into the project
Streaming.zip.
In the next post we're going to remind about streaming processing in xslt.
For some reason KendoUI DataSource does not allow to access current ajax
request. Indeed, it seems quite natural to have a way to cancel running request.
To achieve a desired effect we have made a small
set of changes in the
RemoteTransport class:
var RemoteTransport_setup = kendo.RemoteTransport.fn.setup;
kendo.RemoteTransport.fn.setup = function()
{
var that = this,
options = RemoteTransport_setup.apply(that,
arguments),
beforeSend = options.beforeSend;
options.beforeSend = functions(request, options)
{
that.abort();
that._request = request;
if (beforeSend && (beforeSend.apply(this, arguments) === false))
{
that._request = null;
return false;
}
request.always(function() { that._request = null; });
}
return options;
}
kendo.RemoteTransport.fn.request = function()
{
return this._request;
}
kendo.RemoteTransport.fn.abort = function()
{
var request = this._request;
if (request)
{
this._request = null;
request.abort();
}
}
These changes allow to get an ajax request instance:
grid.dataSource.request(), or to cancel a request grid.dataSource.abort().
Trying to make KendoUI to work with Hebrew or more generally in RTL environment
we had to find a way to guess the position of scroll bar when direction is rtl.
The problem exists due to the fact that some browsers (Chrome one of them) always
put scroll bars to the right. That's utterly wrong. Consider a label and a listbox:
|
Chrome
|
IE
|

|

|
You can see that the scroll bar appears between the label (on the right) and the
data in the list box (on the left) in Chrome, and on the left side of the list
box in the IE.
We came up with the following test that calculates a scroll bar position in rtl
mode:
<script type="text/javascript">
var _scrollbar;
function scrollbar()
{
if (!_scrollbar)
{
var div = document.createElement("div");
div.style.cssText = "overflow:scroll;zoom:1;clear:both;direction:rtl";
div.innerHTML = "<div> </div>";
document.body.appendChild(div);
_scrollbar =
{
size: div.offsetWidth - div.scrollWidth,
rtlPosition: div.offsetLeft < div.firstChild.offsetLeft
? "left" : "right"
};
document.body.removeChild(div);
}
return _scrollbar;
}
</script>
In conjuction with an approach described in
How to create a <style> tag with Javascript we were able to define
rtl css classes for kendo controls and in particular for the grid, combobox, dropdownlist, and datepicker.
Several days ago we've arrived to the blog "Recursive
lambda expressions". There, author asks how to write a lambda expression
that calculates a factorial (only expression statements are allowed).
The problem by itself is rather artificial, but at times you feel an intellectual
pleasure solving such tasks by yourself. So, putting original blog post aside we
devised our answers. The shortest one goes like this:
- As C# lambda expression cannot refer to itself, so it have to receive itself as
a parameter, so:
factorial(factorial, n) = n <= 1 ? 1 : n * factorial(factorial, n - 1);
- To define such lambda expression we have to declare a delegate type that receives
a delegate of the same type:
delegate int Impl(Impl impl, int n);
Fortunately, C# allows this, but a workaround could be used even if it were not
possible.
- To simplify the reasoning we've defined a two-expression version:
Impl impl = (f, n) => n <= 1 ? 1 : n * f(f, n - 1);
Func<int, int> factorial = i => impl(impl, i);
- Finally, we've written out a one-expression version:
Func<int, int> factorial = i => ((Func<Impl,
int>)(f => f(f, i)))((f, n) => n <= 1 ? 1 : n * f(f, n - 1));
- The use is:
var f = factorial(10);
After that excercise we've returned back to original blog and compared
solutions.
We can see that author appeals to a set theory but for some reason his answer is
more complex than nesessary, but comments contain variants that analogous to our
answer.
A customer have a table with data stored by dates, and asked us to present data
from this table by sequential date ranges.
This query sounded trivial but took us half a day to create such a select.
For simplicity consider a table of integer numbers, and try to build a select
that returns pairs of continuous ranges of values.
So, for an input like this:
declare @values table
(
value int not null primary key
);
insert into @values(value)
select 1
union all
select 2
union all
select 3
union all
select 5
union all
select 6
union all
select 8
union all
select 10
union all
select 12
union all
select 13
union all
select 14;
You will have a following output:
low high
---- ----
1 3
5 6
8 8
10 10
12 14
Logic of the algorithms is like this:
- get a low bound of each range (a value without value - 1 in the source);
- get a high bound of each range (a value without value + 1 in the source);
- combine low and high bounds.
Following this logic we have built at least three different queries, where the
shortest one
is:
with source as
(
select * from @values
)
select
l.value low,
min(h.value) high
from
source l
inner join
source h
on
(l.value - 1 not in (select value from source)) and
(h.value + 1 not in (select value from source)) and
(h.value >= l.value)
group by
l.value;
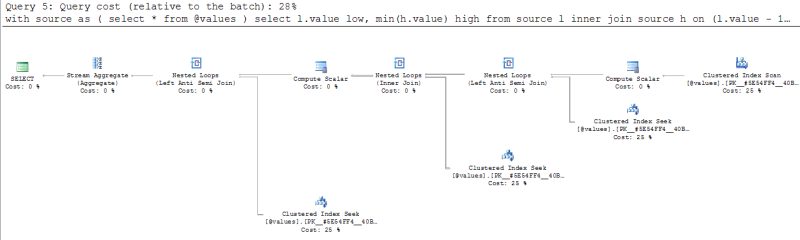
Looking at this query it's hard to understand why it took so
long to
write so simple code...
If you're writing an application that deals with files in file system on Windows, be sure that sooner or later you run into problems with antivirus software.
Our latest program that handles a lot of huge files and works as a Windows service, it reports time to time about some strange errors. These errors look like the file system disappeared on the fly, or, files were stolen by somebody else (after they have been opened in exclusive mode by our application).
We spent about two weeks in order to diagnose the cause of such behaviour, and then came to conclusion that is a secret work of our antivirus. All such errors disappeared as fog when the antivirus was configurated to skip folders with our files.
Thus, keep in mind our experience and don't allow an ativirus to became an evil.
While looking at some SQL we have realized that it can be considerably optimized.
Consider a table source like this:
with Data(ID, Type, SubType)
(
select 1, 'A', 'X'
union all
select 2, 'A', 'Y'
union all
select 3, 'A', 'Y'
union all
select 4, 'B', 'Z'
union all
select 5, 'B', 'Z'
union all
select 6, 'C', 'X'
union all
select 7, 'C', 'X'
union all
select 8, 'C', 'Z'
union all
select 9, 'C', 'X'
union all
select 10, 'C', 'X'
)
Suppose you want to group data by type, to calculate number of elements in each
group and to display sub type if all rows in a group are of the same sub type.
Earlier we have written the code like this:
select
Type,
case when count(distinct SubType) = 1 then min(SubType) end SubType,
count(*) C
from
Data
group by
Type;
Namely, we select min(SybType) provided that there is a single distinct
SubType, otherwise null is shown. That works perfectly,
but algorithmically count(distinct SubType) = 1 needs to build a set
of distinct values for each group just to ask the size of this set. That is
expensive!
What we wanted can be expressed differently: if min(SybType) and
max(SybType) are the same then we want to display it, otherwise to show
null.
That's the new version:
select
Type,
case when min(SubType) = max(SubType) then min(SubType) end SubType,
count(*) C
from
Data
group by
Type;
Such a simple rewrite has cardinally simplified the execution plan:
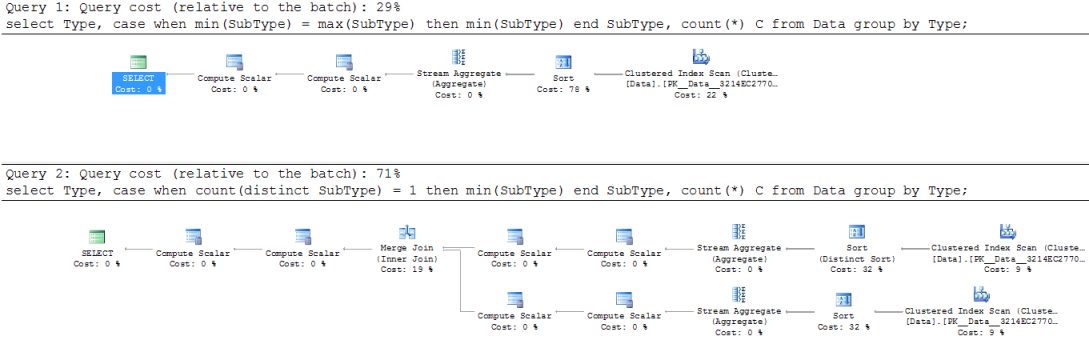
Another bizarre problem we have discovered is that SQL Server 2008 R2 just does
not support the following:
select
count(distinct SubType) over(partition by Type)
from
Data
That's really strange, but it's known bug (see
Microsoft Connect).
A database we support for a client contains multi-billion row tables. Many
users query the data from that database, and it's permanently populated
with a new data.
Every day we load several millions rows of a new data. Such loads can lock tables for a
considerable time, so our loading procedures collect new data into intermediate
tables and insert it into a final destination by chunks, and usually after work
hours.
SQL Server 2008 R2 introduced
READ_COMMITTED_SNAPSHOT database option. This feature trades locks for an
increased tempdb size (to store row versions) and possible performance
degradation during a transaction.
When we have switched the database to that option we did
not notice any considerable performance change. Encouraged, we've decided to
increase size of chunks of data we insert at once.
Earlier we have found that when we insert no more than 1000 rows
at once, users don't notice impact, but for a bigger chunk sizes users start to
complain on performance degradation. This has probably happened due to locks
escalations.
Now, with chunks of 10000 or even 100000 rows we have found that no queries
became slower. But load process became several times faster.
We were ready to pay for increased tempdb and transaction log size to increase
performance, but in our case we didn't approach limits assigned by the DBA.
Another gain is that we can easily load data at any time. This makes data we
store more up to date.
Recently we have introduced some stored procedure in the production and have
found that it performs incredibly slow.
Our reasoning and tests in the development environment did not manifest any
problem at all.
In essence that procedure executes some SELECT and returns a status as a signle
output variable. Procedure recieves several input parameters, and the SELECT
statement uses
with(recompile) execution hint to optimize the performance for a specific
parameters.
We have analyzed the execution plan of that procedure and have found that it
works as if with(recompile) hint was not specified. Without that hint SELECT
failed to use index seek but rather used index scan.
What we have lately found is that the same SELECT that produces result set
instead of reading result into a variable performs very well.
We think that this is a bug in SQL Server 2008 R2 (and in SQL Server 2008).
To demonstrate the problem you can run this test:
-- Setup
create table dbo.Items
(
Item int not null primary key
);
go
insert into dbo.Items
select 1
union all
select 2
union all
select 3
union all
select 4
union all
select 5
go
create procedure dbo.GetMaxItem
(
@odd bit = null,
@result int output
)
as
begin
set nocount on;
with Items as
(
select * from dbo.Items where @odd is null
union all
select * from dbo.Items where (@odd = 1) and ((Item & 1) = 1)
union all
select * from dbo.Items where (@odd = 0) and ((Item & 1) = 0)
)
select @result = max(Item) from Items
option(recompile);
end;
go
create procedure dbo.GetMaxItem2
(
@odd bit = null,
@result int output
)
as
begin
set nocount on;
declare @results table
(
Item int
);
with Items as
(
select * from dbo.Items where @odd is null
union all
select * from dbo.Items where (@odd = 1) and ((Item & 1) = 1)
union all
select * from dbo.Items where (@odd = 0) and ((Item & 1) = 0)
)
insert into @results
select max(Item) from Items
option(recompile);
select @result = Item from @results;
end;
go
Test with output into a variable:
declare @result1 int;
execute dbo.GetMaxItem @odd = null, @result = @result1 output
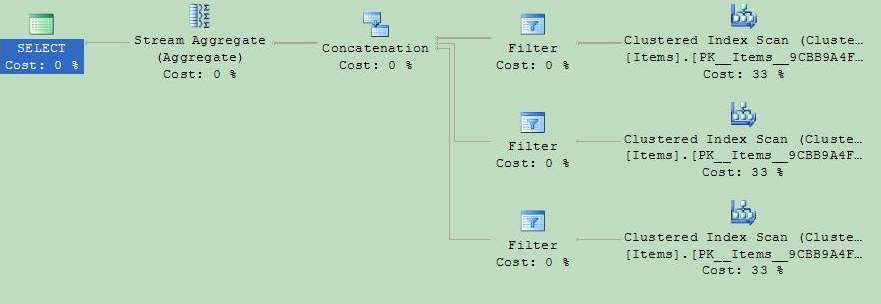
Test without output directly into a variable:
declare @result2 int;
execute dbo.GetMaxItem2 @odd = null, @result = @result2 output
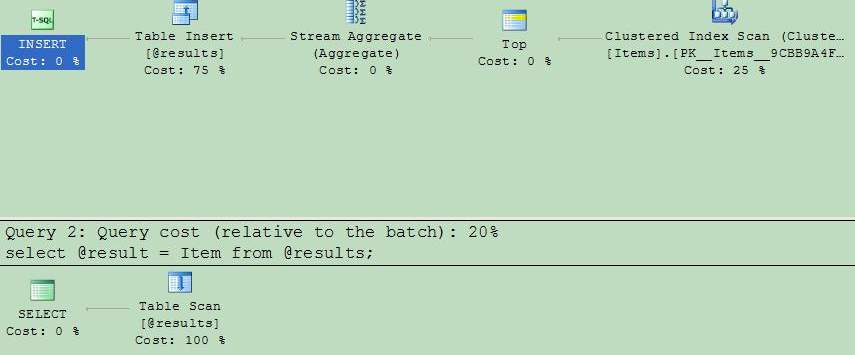
Now, you can see the difference: the first execution plan uses startup expressions, while the second optimizes execution branches, which are not really used.
In our case it was crucial, as the execition time difference was minutes (and
more in future) vs a split of second.
See also
Microsoft Connect Entry.
It has happened so, that we have never worked with jQuery, however were aware of
it.
In early 2000 we have developed a web application that contained rich javascript
APIs, including UI components. Later, we were actively practicing in ASP.NET, and
later in JSF.
At present, looking at jQuery more closely we regret that we have failed to
start using it earlier.
Separation of business logic and presentation is remarkable when one uses JSON
web services. In fact server part can be seen as a set of web services
representing a business logic and a set of resources: html, styles, scripts,
others. Nor ASP.NET or JSF approach such a consistent separation.
The only trouble, in our opinion, is that jQuery has no standard data binding: a way to bind JSON data
to (and from) html controls. The technique that will probably be standardized is called jQuery Templates or JsViews
.
Unfortunatelly after reading about this
binding API, and
being in love with Xslt and XQuery we just want to cry. We don't know what would
be the best solution for the task, but what we see looks uncomfortable to us.
We're not big fans of
Entity Framework, as we don't directly expose the database structure to
the client program but rather through stored procedures and functions. So, EF for
us is a tool to expose those stored procedures as .NET wrappers. This limited use
of EF still greatly automates the data access code.
But what we have lately found is that the EF has a problem with char parameters. Namely,
if you import a procedure say MyProc that accepts char(1),
and then will call it through the generated wrapper, the you will see in sql profiler
that char(1) parameter is passed with many trailing spaces as if it
were char(8000). There isn't necessity to prove that this is highly
ineffective.
We can see that the problem happens in VS 2010 designer rather than in the EF runtime,
as SP's parameters are not attributed with length, see model xml (*.edmx):
<Function Name="MyProc" Schema="Data">
...
<Parameter Name="recipientType" Type="char" Mode="In"
/>
...
</Function>
while if we set:
<Parameter Name="recipientType" Type="char" MaxLength="1"
Mode="In" />
the runtime starts working as expected. So the workaround is to fix model file manually.
See also:
Stored Proc and Char parm
AjaxControlToolkit has methods to access ViewState:
protected V GetPropertyValue<V>(string propertyName, V nullValue)
{
if (this.ViewState[propertyName] == null)
{
return nullValue;
}
return (V) this.ViewState[propertyName];
}
protected void SetPropertyValue<V>(string propertyName, V value)
{
this.ViewState[propertyName] = value;
}
...
public bool EnabledOnClient
{
get { return base.GetPropertyValue("EnabledOnClient", true); }
set { base.SetPropertyValue("EnabledOnClient", value); }
}
We find that code unnecessary complex and nonoptimal. Our code to access
ViewState looks like this:
public bool EnabledOnClient
{
get { return ViewState["EnabledOnClient"] as bool? ?? true); }
set { ViewState["EnabledOnClient"] = value; }
}
1. query.dll vs tquery.dll
We have installed
Windows Search 4 on a Windows 2003 server. The goal was to index huge compressed
xml files (see
Windows Search Notifications). But for some reason it did not want to index
content.
No "select System.ItemUrl from SystemIndex where contains('...')"
has ever returned a row.
We thought that the problem was in our protocol handler, and tried to localize it,
but finally have discovered that Windows Search is not able to find anything within
text files.
Registry comparision has shown that *.txt extension was indexed by the IFilter defined
in the query.dll, while on the other computers, where everything worked, the implementation
was in the tquery.dll.
Both libraries were present on the Windows 2003 server, so we have corrected the
registry and everything has started to work.
As far as we understand query.dll is part of legacy
Indexing Service, and tquery.dll is up to date implementation.
2. Search index size
We have to index a considerable amout of data. But before we can do it we have to
estimate the size of index.
In the past it seems we saw somewhere a statement that search index needs a storage
that's about 10% of original data for its purposes. Unfortunatelly we cannot
find this estimation at present, neither we cannot find any other estimation. This
complicates our planning.
To get empirical estimate we've indexed several thousands *.xml-gz files, which
are gz'ed big xmls. The total size of this files is about 4.5GB. Total uncompressed
size of xmls ~50GB. Xml contained about 10 millions pages of data.
According to 10% criteria we had to arrive to ~5GB search index.
But what we have discovered is that the index has grown to more than 50GB. That's
very disappointing. We cannot afford such expense, as we've commited test on
a tiny part of data, which increases over time.
So, the solution is to find out what's wrong, and how can it be cured, or to
fulltext index only most recent subset of data.
P.S. We have tried to mark folder with search index as compressed, but it did not
work.
P.P.S. We have found the reference to Windows Search 4 index size estimation. It is in
Windows Search Frequently Asked Questions, see answer on "What is average size of a user's index?" question.
An xslt code that worked in the production for several years failed
unexpectedly. That's unusual, unfortunate but it happens.
We started to analyze the problem, limited the code block and recreated it in
the simpe form. That's it:
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:t="http://www.nesterovsky-bros.com/xslt/public"
exclude-result-prefixes="t xs">
<xsl:template match="/" name="main">
<xsl:variable name="content">
<root>
<xsl:for-each select="1 to 3">
<item/>
</xsl:for-each>
</root>
</xsl:variable>
<xsl:variable name="result">
<root>
<xsl:for-each select="$content/root/item">
<section-ref name-ref="{t:generate-id()}.s"/>
<!--
<xsl:variable name="id" as="xs:string"
select="t:generate-id()"/>
<section-ref name-ref="{$id}.s"/>
-->
</xsl:for-each>
</root>
</xsl:variable>
<xsl:message select="$result"/>
</xsl:template>
<xsl:function name="t:generate-id" as="xs:string">
<xsl:variable name="element" as="element()">
<element/>
</xsl:variable>
<xsl:sequence select="generate-id($element)"/>
</xsl:function>
</xsl:stylesheet>
This code performs some transformation and assigns unique values to
name-ref attributes. Values generated with
t:generate-id() function are guaranteed to be unique, as spec
claims that every node has its unique generate-id() value.
Imagine, what was our surprise to find that generated elements all have the same
name-ref's. We studied code all over, and found no holes in our
reasoning and implementation, so our conlusion was: it's Saxon's bug!
It's interesting enough that if we rewrite code a little (see commented part),
it starts to work properly, thus we suspect Saxon's optimizer.
Well, in the course of development we have found and reported many Saxon bugs,
but how come that this little beetle was hiding so long.
We've verified that the bug exists in the versions 9.2 and 9.3. Here is the bug
report:
Saxon 9.2 generate-id() bug.
Unfortunatelly, it's there already for three days (2011-07-25 to 2011-07-27)
without any reaction. We hope this will change soon.
We needed to track a stream position during creation of xml file. This is to
allow random access to a huge xml file (the task is related to
WindowsSearch).
This is a simplified form of the xml:
<data>
<item>...</item>
...
<item>...</item>
</data>
The goal was to have stream position of each item element. With this in mind,
we've decided to:
- open a stream, and then xml writer over it;
- write data into xml writer;
- call
Flush() method of the xml writer before measuring stream offset;
That's a code sample:
var stream = new MemoryStream();
var writer = XmlWriter.Create(stream);
writer.WriteStartDocument();
writer.WriteStartElement("data");
for(var i = 0; i < 10; ++i)
{
writer.Flush();
Console.WriteLine("Flush offset: {0}, char: {1}",
stream.Position,
(char)stream.GetBuffer()[stream.Position - 1]);
writer.WriteStartElement("item");
writer.WriteValue("item " + i);
writer.WriteEndElement();
}
writer.WriteEndElement();
writer.WriteEndDocument();
That's the output:
Flush offset: 46, char: a
Flush offset: 66, char: >
Flush offset: 85, char: >
Flush offset: 104, char: >
Flush offset: 123, char: >
Flush offset: 142, char: >
Flush offset: 161, char: >
Flush offset: 180, char: >
Flush offset: 199, char: >
Flush offset: 218, char: >
Funny, isn't it?
After feeding the start tag <data>, and flushing xml writer we observe that only
"<data" has been written down to the stream. Well,
Flush() have never promissed anything particular about the content
of the stream, so we cannot claim any violation, however we expected to see
whole start tag.
Inspection of the implementation of xml writer reveals laziness during writting
data down the stream. In particular start tag is closed when one starts the
content. This is probably to implement empty tags: <data/>.
To do the trick we had to issue empty content, moreover, to call a particular
method with particular parameters of the xml writer. So the code after the fix
looks like this:
var stream = new MemoryStream();
var writer = XmlWriter.Create(stream);
writer.WriteStartDocument();
writer.WriteStartElement("data");
char[] empty = { ' ' };
for(var i = 0; i < 10; ++i)
{
writer.WriteChars(empty, 0, 0);
writer.Flush();
Console.WriteLine("Flush offset: {0}, char: {1}",
stream.Position,
(char)stream.GetBuffer()[stream.Position - 1]);
writer.WriteStartElement("item");
writer.WriteValue("item " + i);
writer.WriteEndElement();
}
writer.WriteEndElement();
writer.WriteEndDocument();
And output is:
Flush offset: 47, char: >
Flush offset: 66, char: >
Flush offset: 85, char: >
Flush offset: 104, char: >
Flush offset: 123, char: >
Flush offset: 142, char: >
Flush offset: 161, char: >
Flush offset: 180, char: >
Flush offset: 199, char: >
Flush offset: 218, char: >
While this code works, we feel uneasy with it.
What's the better way to solve the task?
Update: further analysis shows that it's
only possible behaviour, as after the call to write srart element, you either
can write attributes, content or end of element, so writer may write either
space, '>' or '/>'. The only
question is why it takes WriteChars(empty, 0, 0) into account and WriteValue("")
it doesn't.
As you probably know we have implemented our custom Protocol Handler for the Windows
Search.
It's called .xml-gz, and has a goal to index compressed xml files and to have
search results with a subtree precision. So, for xml:
<data>
<item>...</item>
<item>...</item>
...
</data>
search finds results within item and returns xml's url and stream
offset of the item. Using ZLIB API we can compress data with stream bookmarks, so fast random
access to the data is possible.
The only problem we have is about notification of changes (create, delete, update)
of such files.
Spec describes several techniques (nothing has worked for us):
1. Call catalogManager.ReindexMatchingURLs()
- it just returns without any impact.
2.Call changeSink.OnItemsChanged()
- returns error.
3. Implement
.xml-gz IFilter and call IGatherNotifyInline (see "
have your .zip urls indexed when they are created or modified") -
that's a mistery, as:
4. Implement root url in form .xml-gz:/// and perform Windows Search:
SELECT
System.ItemUrl, System.DateModified
FROM
SystemIndex WHERE System.FileExtension='.xml-gz'
to find all .xml-gz sources. This is not reliable, as your protocol handler can
be (and is) called before file is indexed.
So, the only reliable way to index your data is to (re-)add indexing rule for
the protocol handler, which in most cases reindexes everything.
The only bearable solution we found is to define indexing rule in the form:
.xml-gz://file:d:/data/... and to use
IShellFolder(2)
interfaces to discover sub items and their modification times. This technique allows
minimal data scan when you're (re-)add indexing rule.
Being unexperienced with Windows Search we tried to build queries to find data in the huge storage. We needed to find a document that matches some name pattern and contains some text.
Our naive query was like this:
select top 1000
System.ItemUrl
from
SystemIndex
where
scope = '...' and
System.ItemName like '...%' and
contains('...')
In most cases this query returns nothing and runs very long. It's interesting to note that it may start returning data if "top" clause is missing or uses a bigger number, but in this cases query is slower even more.
Next try was like this:
select top 1000
System.ItemUrl
from
SystemIndex
where
scope = '...' and
System.ItemName >= '...' and System.ItemName < '...' and
contains('...')
This query is also slow, but at least it returns some results.
At some point we have started to question the utility of Windows Search if it's so slow, but then we have found that there is a property System.ItemNameDisplay, which in our case coincides with the value of property System.ItemName, so we have tried the query:
select top 1000
System.ItemUrl
from
SystemIndex
where
scope = '...' and
System.ItemNameDisplay like '...%' and
contains('...')
This query worked fast, and produced good results. This hints that search engine has index on System.ItemNameDisplay in contrast to System.ItemName property.
We've looked at property definitions:
System.ItemNameDisplay
The display name in "most complete" form. It is the unique representation of the item name most appropriate for end users.
propertyDescription
name = System.ItemNameDisplay
shellPKey = PKEY_ItemNameDisplay
formatID = B725F130-47EF-101A-A5F1-02608C9EEBAC
propID = 10
searchInfo
inInvertedIndex = true
isColumn = true
isColumnSparse = false
columnIndexType = OnDisk
maxSize = 128
System.ItemName
The base name of the System.ItemNameDisplay property.
propertyDescription
name = System.ItemName
shellPKey = PKEY_ItemName
formatID = 6B8DA074-3B5C-43BC-886F-0A2CDCE00B6F
propID = 100
searchInfo
inInvertedIndex = false
isColumn = true
isColumnSparse = false
columnIndexType = OnDisk
maxSize = 128
Indeed, one property is indexed, while the other is not.
As with other databases, query is powerful when engine uses indices rather than performs data scan. This is also correct for Windows Search.
The differences in results that variations of query produce also manifests that Windows Search nevertheless is very different from relational database.
We have developed our custom Windows Search Protocol Handler. The role of this component is to expose items of complex content (or unusual storage) to Windows Search.
You can think of some virtual folder, so a Protocol Handler allows to enumerate it's files, file properties, and contents.
The goal of our Protocol Handler is to represent some data structure as a set of xml files. We expected that if we found a data within a folder with these files, then a search within Protocol Handler's scope would bring the same (or almost the same) results.
Reality is different.
For some reason .xml IFilter (a component to extract text data to index) works differently with file system and with our storage. We cannot state that it does not work, but for some reason many words that Windows Search finds within a file are never found within Protocol Handler scope.
We have observed that if, for purpose of indexing, we represent content xml items as .txt files, then search works as expected. So, our workaround was to present only xml's text data for the indexing, and to use .txt IFilter (this in fact roughly what .xml IFilter does by itself).
Is there a conclusion?
Well, Windows Search is a black box probably containing bugs. Its behaviour is not always obvious.
There is a problem with XML serialization of BigDecimal values, as we've written in one of our previous articles "BigDecimal + JAXB => potential interoperability problems". And now we ran into issue with serialization of double / Double values. All such values, except zero, serialize in scientific format, even a value contains only integer part. For example, 12 will be serialized as 1.2E+1. Actually this is not contradicts with XML schema definitions.
But what could be done, if you want to send/receive double and/or decimal values in plain format. For example you want serialize a double / BigDecimal value 314.15926 in XML as is. In this case you ought to use javax.xml.bind.annotation.adapters.XmlAdapter.
In order to solve this task we've created two descendants of XmlAdapter (the first for double / Double and the second for BigDecimal), click here to download the sources.
Applying these classes on properties or package level you may manage XML serialization of numeric fields in your classes.
See this article for tips how to use custom XML serialization.
As you may know, JAX-WS uses javax.xml.datatype.XMLGregorianCalendar abstract class in order
to present date/time data type fields. We have used this class rather long time in
happy ignorance without of any problem. Suddenly, few days ago, we ran into a weird bug
of its Sun’s implementation (com.sun.org.apache.xerces.internal.jaxp.datatype.XMLGregorianCalendarImpl).
The bug appears whenever we try to convert an XMLGregorianCalendar instance
to a java.util.GregorianCalendar using toGregorianCalendar() method.
I’ve written a simple JUnit test in order to demonstrate this bug:
@Test
public void testXMLGregorianCalendar()
throws Exception
{
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
XMLGregorianCalendar calendar =
javax.xml.datatype.DatatypeFactory.newInstance().newXMLGregorianCalendar();
calendar.setDay(1);
calendar.setMonth(1);
calendar.setYear(1);
System.out.println("1: " + calendar.toString());
System.out.println("2: " +
formatter.format(calendar.toGregorianCalendar().getTime()));
GregorianCalendar cal = new GregorianCalendar(
calendar.getYear(),
calendar.getMonth() - 1,
calendar.getDay());
cal.clear(Calendar.AM_PM);
cal.clear(Calendar.HOUR_OF_DAY);
cal.clear(Calendar.HOUR);
cal.clear(Calendar.MINUTE);
cal.clear(Calendar.SECOND);
cal.clear(Calendar.MILLISECOND);
System.out.println("3: " + formatter.format(cal.getTime()));
/*
* Output:
*
* 1: 0001-01-01
* 2: 0001-01-03 00:00:00
* 3: 0001-01-01 00:00:00
*/
}
As you see, the date 0001-01-01 is transformed to 0001-01-03 after call of
toGregorianCalendar() method (see output 2).
Moreover, if we’ll serialize this XMLGregorianCalendar instance to XML we’ll see
it as 0001-01-01+02:00 which is rather weird and could be potential problem for
interoperability between Java and other platforms.
Conclusion: in order to convert XMLGregorianCalendar value to
GregorianCalendar do the following. Create a new instance of
GregorianCalendar and just set the corresponding fields with
values from XMLGregorianCalendar instance.
Earlier, we have described an approach to call Windows Search from SQL Server 2008. But it has turned out that our problem is more complicated...
All has started from the initial task:
- to allow free text search in a store of huge xml files;
- files should be compressed, so these are *.xml.gz;
- search results should be addressable to a fragment within xml.
Later we shall describe how we have solved this task, and now it's enough to say that we have implemented a Protocol Handler for Windows Search named '.xml-gz:'. This way original file stored say at 'file:///c:/store/data.xml-gz' is seen as a container by the Windows Search:
- .xml-gz:///file:c:/store/data.xml-gz/id1.xml
- .xml-gz:///file:c:/store/data.xml-gz/id2.xml
- ...
This way search xml should be like this:
select System.ItemUrl from SystemIndex where scope='.xml-gz:' and contains(...)
Everything has worked during test: we have succeeded to issue Windows Search selects from SQL Server and join results with other sql queries.
But later on when we considered a runtime environment we have seen that our design won't work. The reason is simple. Windows Search will work on a computer different from those where SQL Servers run. So, the search query should look like this:
select System.ItemUrl from Computer.SystemIndex where scope='.xml-gz:' and contains(...)
Here we have realized the limitation of current (Windows Search 4) implementation: remote search works for shared folders only, thus query may only look like:
select System.ItemUrl from Computer.SystemIndex where scope='file://Computer/share/' and contains(...)
Notice that search restricts the scope to a file protocol, this way remoter search will never return our results. The only way to search in our scope is to perform a local search.
We have considered following approaches to resolve the issue.
The simplest one would be to access Search protocol on remote computer using a connection string: "Provider=Search.CollatorDSO;Data Source=Computer" and use local queries. This does not work, as provider simply disregards Data Source parameter.
The other try was to use MS Remote OLEDB provider. We tried hard to configure it but it always returns obscure error, and more than that it's deprecated (Microsoft claims to remove it in future).
So, we decided to forward request manually:
- SQL Server calls a web service (through a CLR function);
- Web service queries Windows Search locally.
Here we considered WCF Data Services and a custom web service.
The advantage of WCF Data Services is that it's a technology that has ambitions of a standard but it's rather complex task to create implementation that will talk with Windows Search SQL dialect, so we have decided to build a primitive http handler to get query parameter. That's trivial and also has a virtue of simple implementation and high streamability.
So, that's our http handler (WindowsSearch.ashx):
<%@ WebHandler Language="C#" Class="WindowsSearch" %>
using System;
using System.Web;
using System.Xml;
using System.Text;
using System.Data.OleDb;
/// <summary>
/// A Windows Search request handler.
/// </summary>
public class WindowsSearch: IHttpHandler
{
/// <summary>
/// Handles the request.
/// </summary>
/// <param name="context">A request context.</param>
public void ProcessRequest(HttpContext context)
{
var request = context.Request;
var query = request.Params["query"];
var response = context.Response;
response.ContentType = "text/xml";
response.ContentEncoding = Encoding.UTF8;
var writer = XmlWriter.Create(response.Output);
writer.WriteStartDocument();
writer.WriteStartElement("resultset");
if (!string.IsNullOrEmpty(query))
{
using(var connection = new OleDbConnection(provider))
using(var command = new OleDbCommand(query, connection))
{
connection.Open();
using(var reader = command.ExecuteReader())
{
string[] names = null;
while(reader.Read())
{
if (names == null)
{
names = new string[reader.FieldCount];
for (int i = 0; i < names.Length; ++i)
{
names[i] = XmlConvert.EncodeLocalName(reader.GetName(i));
}
}
writer.WriteStartElement("row");
for(int i = 0; i < names.Length; ++i)
{
writer.WriteElementString(
names[i],
Convert.ToString(reader[i]));
}
writer.WriteEndElement();
}
}
}
}
writer.WriteEndElement();
writer.WriteEndDocument();
writer.Flush();
}
/// <summary>
/// Indicates that a handler is reusable.
/// </summary>
public bool IsReusable { get { return true; } }
/// <summary>
/// A connection string.
/// </summary>
private const string provider =
"Provider=Search.CollatorDSO;" +
"Extended Properties='Application=Windows';" +
"OLE DB Services=-4";
}
And a SQL CLR function looks like this:
using System;
using System.Collections;
using System.Collections.Generic;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Net;
using System.IO;
using System.Xml;
/// <summary>
/// A user defined function.
/// </summary>
public class UserDefinedFunctions
{
/// <summary>
/// A Windows Search returning result as xml strings.
/// </summary>
/// <param name="url">A search url.</param>
/// <param name="userName">A user name for a web request.</param>
/// <param name="password">A password for a web request.</param>
/// <param name="query">A Windows Search SQL.</param>
/// <returns>A result rows.</returns>
[SqlFunction(
IsDeterministic = false,
Name = "WindowsSearch",
FillRowMethodName = "FillWindowsSearch",
TableDefinition = "value nvarchar(max)")]
public static IEnumerable Search(
string url,
string userName,
string password,
string query)
{
return SearchEnumerator(url, userName, password, query);
}
/// <summary>
/// A filler of WindowsSearch function.
/// </summary>
/// <param name="value">A value returned from the enumerator.</param>
/// <param name="row">An output value.</param>
public static void FillWindowsSearch(object value, out string row)
{
row = (string)value;
}
/// <summary>
/// Gets a search row enumerator.
/// </summary>
/// <param name="url">A search url.</param>
/// <param name="userName">A user name for a web request.</param>
/// <param name="password">A password for a web request.</param>
/// <param name="query">A Windows Search SQL.</param>
/// <returns>A result rows.</returns>
private static IEnumerable<string> SearchEnumerator(
string url,
string userName,
string password,
string query)
{
if (string.IsNullOrEmpty(url))
{
throw new ArgumentException("url");
}
if (string.IsNullOrEmpty(query))
{
throw new ArgumentException("query");
}
var requestUrl = url + "?query=" + Uri.EscapeDataString(query);
var request = WebRequest.Create(requestUrl);
request.Credentials = string.IsNullOrEmpty(userName) ?
CredentialCache.DefaultCredentials :
new NetworkCredential(userName, password);
using(var response = request.GetResponse())
using(var stream = response.GetResponseStream())
using(var reader = XmlReader.Create(stream))
{
bool read = true;
while(!read || reader.Read())
{
if ((reader.Depth == 1) && reader.IsStartElement())
{
// Note that ReadInnerXml() advances the reader similar to Read().
yield return reader.ReadInnerXml();
read = false;
}
else
{
read = true;
}
}
}
}
}
And, finally, when you call this service from SQL Server you write query like this:
with search as
(
select
cast(value as xml) value
from
dbo.WindowsSearch
(
N'http://machine/WindowsSearchService/WindowsSearch.ashx',
null,
null,
N'
select
"System.ItemUrl"
from
SystemIndex
where
scope=''.xml-gz:'' and contains(''...'')'
)
)
select
value.value('/System.ItemUrl[1]', 'nvarchar(max)')
from
search
Design is not trivial but it works somehow.
After dealing with all these problems some questions remain unanswered:
- Why SQL Server does not allow to query Windows Search directly?
- Why Windows Search OLEDB provider does not support "Data Source" parameter?
- Why Windows Search does not support custom protocols during remote search?
- Why SQL Server does not support web request/web services natively?
Hello everybody! You might think that we had died, since there were no articles
in our blog for a too long time, but no, we’re still alive…
A month or so we were busy with Windows Search and stuff around it. Custom
protocol handlers, support of different file formats and data storages are very
interesting tasks, but this article discusses another issue.
The issue is how to compile and install native code written in C++, which was
built under Visual Studio 2008 (SP1), on a clean computer.
The problem is that native dlls now resolve the problem known as a
DLL hell using assembly
manifests. This should help to discover and load the right DLL. The problem is
that there are many versions of CRT, MFC, ATL and other dlls, and it's not
trivial to create correct setup for a clean computer.
In order to avoid annoying dll binding problems at run-time, please define
BIND_TO_CURRENT_CRT_VERSION and/or (_BIND_TO_CURRENT_ATL_VERSION,
_BIND_TO_CURRENT_MFC_VERSION). Don’t forget to make the same definitions for
all configurations/target platforms you intend to use. Build the project and
check the resulting manifest file (just in case). It should contain something
like that:
<?xml version='1.0' encoding='UTF-8' standalone='yes'?>
<assembly xmlns='urn:schemas-microsoft-com:asm.v1' manifestVersion='1.0'>
<trustInfo xmlns="urn:schemas-microsoft-com:asm.v3">
<security>
<requestedPrivileges>
<requestedExecutionLevel level='asInvoker' uiAccess='false' />
</requestedPrivileges>
</security>
</trustInfo>
<dependency>
<dependentAssembly>
<assemblyIdentity type='win32' name='Microsoft.VC90.DebugCRT'
version='9.0.30729.4148'
processorArchitecture='x86'
publicKeyToken='1fc8b3b9a1e18e3b' />
</dependentAssembly>
</dependency>
</assembly>
The version of dependent assembly gives you a clue what a native run-time
version(s) requires your application. The same thing you have to do for all your
satellite projects.
The next step is to create a proper setup project using VS wizard.
Right click on setup project and select “Add->Merge Module…”. Select
“Microsoft_VC90_CRT_x86.msm” or/and (“Microsoft_VC90_DebugCRT_x86.msm”,
“Microsoft_VC90_ATL_x86.msm”, “Microsoft_VC90_MFC_x86.msm”…) for installing of
corresponding run-time libraries and “policy_9_0_Microsoft_VC90_CRT_x86.msm”
etc. for route calls of old version run-time libraries to the newest versions.
Now you're ready to build your setup project.
You may also include “Visual C++ Runtime Libraries” to a setup prerequisites.
As result, you'll get 2 files (setup.exe and Setup.msi) and an optional folder
(vcredist_x86) with C++ run-time redistributable libraries.
Note: only setup.exe installs those C++ run-time libraries.
More info concerning this theme:
Let's assume you're loading data into a table using BULK INSERT from tab
separated file. Among others you have some varchar field, which may contain any
character. Content of such field is escaped with usual scheme:
'\' as '\\';char(13) as '\n';char(10) as '\r';char(9) as '\t';
But now, after loading, you want to unescape content back. How would you do it?
Notice that:
'\t' should be converted to a char(9);'\\t' should be converted to a '\t';'\\\t' should be converted to a '\' + char(9);
It might be that you're smart and you will immediately think of correct
algorithm, but for us it took a while to come up with a neat solution:
declare @value varchar(max);
set @value = ...
-- This unescapes the value
set @value =
replace
(
replace
(
replace
(
replace
(
replace(@value, '\\', '\ '),
'\n',
char(10)
),
'\r',
char(13)
),
'\t',
char(9)
),
'\ ',
'\'
);
Do you know a better way?
We were trying to query Windows Search from an SQL Server 2008.
Documentation states that Windows Search is exposed as OLE DB datasource. This meant that we could just query result like this:
SELECT
*
FROM
OPENROWSET(
'Search.CollatorDSO.1',
'Application=Windows',
'SELECT "System.ItemName", "System.FileName" FROM SystemIndex');
But no, such select never works. Instead it returns obscure error messages:
OLE DB provider "Search.CollatorDSO.1" for linked server "(null)" returned message "Command was not prepared.".
Msg 7399, Level 16, State 1, Line 1
The OLE DB provider "Search.CollatorDSO.1" for linked server "(null)" reported an error. Command was not prepared.
Msg 7350, Level 16, State 2, Line 1
Cannot get the column information from OLE DB provider "Search.CollatorDSO.1" for linked server "(null)".
Microsoft is silent about reasons of such behaviour. People came to a conclusion that the problem is in the SQL Server, as one can query search results through OleDbConnection without problems.
This is very unfortunate, as it bans many use cases.
As a workaround we have defined a CLR function wrapping Windows Search call and returning rows as xml fragments. So now the query looks like this:
select
value.value('System.ItemName[1]', 'nvarchar(max)') ItemName,
value.value('System.FileName[1]', 'nvarchar(max)') FileName
from
dbo.WindowsSearch('SELECT "System.ItemName", "System.FileName" FROM SystemIndex')
Notice how we decompose xml fragment back to fields with the value() function.
The C# function looks like this:
using System;
using System.Collections;
using System.IO;
using System.Xml;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Data.OleDb;
using Microsoft.SqlServer.Server;
public class UserDefinedFunctions
{
[SqlFunction(
FillRowMethodName = "FillSearch",
TableDefinition="value xml")]
public static IEnumerator WindowsSearch(SqlString query)
{
const string provider =
"Provider=Search.CollatorDSO;" +
"Extended Properties='Application=Windows';" +
"OLE DB Services=-4";
var settings = new XmlWriterSettings
{
Indent = false,
CloseOutput = false,
ConformanceLevel = ConformanceLevel.Fragment,
OmitXmlDeclaration = true
};
string[] names = null;
using(var connection = new OleDbConnection(provider))
using(var command = new OleDbCommand(query.Value, connection))
{
connection.Open();
using(var reader = command.ExecuteReader())
{
while(reader.Read())
{
if (names == null)
{
names = new string[reader.FieldCount];
for (int i = 0; i < names.Length; ++i)
{
names[i] = XmlConvert.EncodeLocalName(reader.GetName(i));
}
}
var stream = new MemoryStream();
var writer = XmlWriter.Create(stream, settings);
for(int i = 0; i < names.Length; ++i)
{
writer.WriteElementString(names[i], Convert.ToString(reader[i]));
}
writer.Close();
yield return new SqlXml(stream);
}
}
}
}
public static void FillSearch(object value, out SqlXml row)
{
row = (SqlXml)value;
}
}
Notes:
- Notice the use of "
OLE DB Services=-4" in provider string to avoid transaction enlistment (required in SQL Server 2008).
- Permission level of the project that defines this extension function should be set to unsafe (see Project Properties/Database in Visual Studio) otherwise it does not allow the use OLE DB.
- SQL Server should be configured to allow CLR functions, see Server/Facets/Surface Area Configuration/ClrIntegrationEnabled in Microsoft SQL Server Management Studio
- Assembly should either be signed or a database should be marked as trustworthy, see Database/Facets/Trustworthy in Microsoft SQL Server Management Studio.
A search "java web service session object" has reached our site.
Unfortunately, we cannot help to the original searcher but a next one might find
this info usefull.
To get http session in the web service you should add a field to your class
that will be populated with request context.
@WebService
public class MyService
{
@WebMethod
public int method(String value)
{
MessageContext messageContext = context.getMessageContext();
HttpServletRequest request =
(HttpServletRequest)messageContext.get(MessageContext.SERVLET_REQUEST);
HttpSession session = request.getSession();
// go ahead.
}
// A web service context.
@Resource
private WebServiceContext context;
}
Last few days we were testing Java web-applications that expose web-services. During these tests we've found few interesting features.
The first feature allows to retrieve info about all endpoints supported by the web-application on GET request. The feature works at least for Metro that implements JAX-WS API v2.x. In order to get such info, a client sends any endpoint's URL to the server. The result is an HTML page with a table. Each row of such table contains an endpoint's data for each supported web-service method. This feature may be used as a web-services discovery mechanism.
The second feature is bad rather than good. JAX-WS API supposes that a developer annotates classes and methods that he/she wants to expose as web-services. Then, an implementation generates additional layer-bridge between developer's code and API that does all routine work behind the scene. May be that was a good idea, but Metro's implementation is imperfect. Metro dynamically generates such classes at run-time when a web-application starts. Moreover, Metro does such generation for all classes at once. So, in our case, when the generated web-based application contains dozens or even hundreds of web-services, the application's startup takes a lot of time.
Probably, Metro developers didn't want to deal with implementation of lazy algorithms, when a web-service is generated and cached on demand. We hope this issue will be solved in next releases.
A method pattern we have suggested to use along with @Yield annotation brought
funny questions like: "why should I mark my method with @Yield annotation at
all?"
Well, in many cases you may live with ArrayList populated with data, and then to
perform iteration. But in some cases this approach is not practical either due
to amount of data or due to the time required to get first item.
In later
case you usually want to build an iterator that calculates items on demand. The @Yield annotation is designed as a marker of such methods. They are refactored
into state machines at compilation time, where each addition to a result list is
transformed into a new item yielded by the iterator.
So, if you have decided to use @Yield annotation then at some point you will ask yourself what
happens with resources acquired during iteration. Will resources be released if
iteration is interrupted in the middle due to exception or a break statement?
To address the problem yield iterator implements Closeable interface.
This way when you call close() before iteration reached the end, the state machine
works as if break statement of the method body is injected after the yield
point. Thus all finally blocks of the original method are executed and resources
are released.
Consider an example of data iterator:
@Yield
public Iterable<Data> getData(final Connection connection)
throws Exception
{
ArrayList<Data> result = new ArrayList<Data>();
PreparedStatement statement =
connection.prepareStatement("select key, value from table");
try
{
ResultSet resultSet = statement.executeQuery();
try
{
while(resultSet.next())
{
Data data = new Data();
data.key = resultSet.getInt(1);
data.value = resultSet.getString(2);
result.add(data); // yield point
}
}
finally
{
resultSet.close();
}
}
finally
{
statement.close();
}
return result;
}
private static void close(Object value)
throws IOException
{
if (value instanceof Closeable)
{
Closeable closeable = (Closeable)value;
closeable.close();
}
}
public void daoAction(Connection connection)
throws Exception
{
Iterable<Data> items = getData(connection);
try
{
for(Data data: items)
{
// do something that potentially throws exception.
}
}
finally
{
close(items);
}
}
getData() iterates over sql data. During the lifecycle it creates and releases
PreparedStatement and ResultSet.
daoAction() iterates over results provided by getData() and performs some
actions that potentially throw an exception. The goal of close() is to release
opened sql resources in case of such an exception.
Here you can inspect how state machine is implemented for such a method:
@Yield()
public static Iterable<Data> getData(final Connection connection)
throws Exception
{
assert (java.util.ArrayList<Data>)(ArrayList<Data>)null == null;
class $state implements java.lang.Iterable<Data>, java.util.Iterator<Data>, java.io.Closeable
{
public java.util.Iterator<Data> iterator() {
if ($state$id == 0) {
$state$id = 1;
return this;
} else return new $state();
}
public boolean hasNext() {
if (!$state$nextDefined) {
$state$hasNext = $state$next();
$state$nextDefined = true;
}
return $state$hasNext;
}
public Data next() {
if (!hasNext()) throw new java.util.NoSuchElementException();
$state$nextDefined = false;
return $state$next;
}
public void remove() {
throw new java.lang.UnsupportedOperationException();
}
public void close() {
do switch ($state$id) {
case 3:
$state$id2 = 8;
$state$id = 5;
continue;
default:
$state$id = 8;
continue;
} while ($state$next());
}
private boolean $state$next() {
java.lang.Throwable $state$exception;
while (true) {
try {
switch ($state$id) {
case 0:
$state$id = 1;
case 1:
statement = connection.prepareStatement("select key, value from table");
$state$exception1 = null;
$state$id1 = 8;
$state$id = 2;
case 2:
resultSet = statement.executeQuery();
$state$exception2 = null;
$state$id2 = 6;
$state$id = 3;
case 3:
if (!resultSet.next()) {
$state$id = 4;
continue;
}
data = new Data();
data.key = resultSet.getInt(1);
data.value = resultSet.getString(2);
$state$next = data;
$state$id = 3;
return true;
case 4:
$state$id = 5;
case 5:
{
resultSet.close();
}
if ($state$exception2 != null) {
$state$exception = $state$exception2;
break;
}
if ($state$id2 > 7) {
$state$id1 = $state$id2;
$state$id = 7;
} else $state$id = $state$id2;
continue;
case 6:
$state$id = 7;
case 7:
{
statement.close();
}
if ($state$exception1 != null) {
$state$exception = $state$exception1;
break;
}
$state$id = $state$id1;
continue;
case 8:
default:
return false;
}
} catch (java.lang.Throwable e) {
$state$exception = e;
}
switch ($state$id) {
case 3:
case 4:
$state$exception2 = $state$exception;
$state$id = 5;
continue;
case 2:
case 5:
case 6:
$state$exception1 = $state$exception;
$state$id = 7;
continue;
default:
$state$id = 8;
java.util.ConcurrentModificationException ce = new java.util.ConcurrentModificationException();
ce.initCause($state$exception);
throw ce;
}
}
}
private PreparedStatement statement;
private ResultSet resultSet;
private Data data;
private int $state$id;
private boolean $state$hasNext;
private boolean $state$nextDefined;
private Data $state$next;
private java.lang.Throwable $state$exception1;
private int $state$id1;
private java.lang.Throwable $state$exception2;
private int $state$id2;
}
return new $state();
}
Now, you can estimate for what it worth to write an algorithm as a sound state machine
comparing to the conventional implementation.
Yield annotation processor can be downloaded from
Yield.zip
or Yield.jar
See also
Yield return feature in java.
We're happy to announce that we have implemented @Yield annotation
both in javac and in eclipse compilers.
This way you get built-in IDE support for the feature!
To download yield annotation processor please use the following link:
Yield.zip
It contains both yield annotation processor, and a test project.
If you do not want to compile the sources, you can download
Yield.jar
We would like to reiterate on how @Yield annotation works:
- A developer defines a method that returns either
Iterator<T> or
Iterable<T> instance and marks it with @Yield
annotation.
- A developer implements iteration logic following the pattern:
- declare a variable to accumulate results:
ArrayList<T> items = new ArrayList<T>();
- use the following statement to add item to result:
items.add(...);
- use
return items;
or
return items.iterator();
to return result;
- mark method's params, if any, as final.
- A devoloper ensures that yield annotation processor is available during
compilation (see details below).
YieldProcessor rewrites method into a state machine at
compilation time.
The following is an example of such a method:
@Yield
public static Iterable<Integer> generate(final int from, final int to)
{
ArrayList<Integer> items = new ArrayList<Integer>();
for(int i = from; i < to; ++i)
{
items.add(i);
}
return items;
}
The use is like this:
for(int value: generate(7, 20))
{
System.out.println("generator: " + value);
}
Notice that method's implementation still will be correct in absence of
YieldProcessor.
Other important feature is that the state machine returned after the yield
processor is closeable.
This means that if you're breaking the iteration before the end is reached you
can release resources acquired during the iteration.
Consider the example where break exits iteration:
@Yield
public static Iterable<String> resourceIteration()
{
ArrayList<String> items = new ArrayList<String>();
acquire();
try
{
for(int i = 0; i < 100; ++i)
{
items.add(String.valueOf(i));
}
}
finally
{
release();
}
return items;
}
and the use
int i = 0;
Iterable<String> iterator = resourceIteration();
try
{
for(String item: iterator)
{
System.out.println("item " + i + ":" + item);
if (i++ > 30)
{
break;
}
}
}
finally
{
close(iterator);
}
...
private static <T> void close(T value)
throws IOException
{
if (value instanceof Closeable)
{
Closeable closeable = (Closeable)value;
closeable.close();
}
}
Close will execute all required finally blocks. This way resources will be
released.
To configure yield processor a developer needs to refer Yield.jar in build path,
as it contains @Yield annotation. For javac it's enough, as
compiler will find annotation processor automatically.
Eclipse users need to open project properties and:
- go to the "Java Compiler"/"Annotation Processing"
- mark "Enable project specific settings"
- select "Java Compiler"/"Annotation Processing"/"Factory Path"
- mark "Enable project specific settings"
- add Yield.jar to the list of "plug-ins and JARs that contain annotation
processors".
At the end we want to point that @Yield annotation is a syntactic
suggar, but it's important the way the foreach statement is important, as it
helps to write concise and an error free code.
See also
Yield feature in java implemented!
Yield feature in java
We could not stand the temptation to implement the @Yield annotation that
we described
earlier.
Idea is rather clear but people are saying that it's not an easy task to update
the sources.
They were right!
Implementation has its price, as we were forced to access JDK's classes of javac
compiler. As result, at present, we don't support other compilers such as
EclipseCompiler.
We shall look later what can be done in this area.
At present, annotation processor works perfectly when you run javac either from
the command line, from ant, or from other build tool.
Here is an example of how method is refactored:
@Yield
public static Iterable<Long> fibonachi()
{
ArrayList<Long> items = new ArrayList<Long>();
long Ti = 0;
long Ti1 = 1;
while(true)
{
items.add(Ti);
long value = Ti + Ti1;
Ti = Ti1;
Ti1 = value;
}
}
And that's how we transform it:
@Yield()
public static Iterable<Long> fibonachi() {
assert (java.util.ArrayList<Long>)(ArrayList<Long>)null == null : null;
class $state$ implements java.lang.Iterable<Long>, java.util.Iterator<Long>, java.io.Closeable {
public java.util.Iterator<Long> iterator() {
if ($state$id == 0) {
$state$id = 1;
return this;
} else return new $state$();
}
public boolean hasNext() {
if (!$state$nextDefined) {
$state$hasNext = $state$next();
$state$nextDefined = true;
}
return $state$hasNext;
}
public Long next() {
if (!hasNext()) throw new java.util.NoSuchElementException();
$state$nextDefined = false;
return $state$next;
}
public void remove() {
throw new java.lang.UnsupportedOperationException();
}
public void close() {
$state$id = 5;
}
private boolean $state$next() {
while (true) switch ($state$id) {
case 0:
$state$id = 1;
case 1:
Ti = 0;
Ti1 = 1;
case 2:
if (!true) {
$state$id = 4;
break;
}
$state$next = Ti;
$state$id = 3;
return true;
case 3:
value = Ti + Ti1;
Ti = Ti1;
Ti1 = value;
$state$id = 2;
break;
case 4:
case 5:
default:
$state$id = 5;
return false;
}
}
private long Ti;
private long Ti1;
private long value;
private int $state$id;
private boolean $state$hasNext;
private boolean $state$nextDefined;
private Long $state$next;
}
return new $state$();
}
Formatting is automatic, sorry, but anyway it's for diagnostics only. You
will never see this code.
It's iteresting to say that this implementation is very precisely mimics
xslt state machine implementation we have done back in 2008.
You can
download YieldProcessor here. We hope that someone will find our solution
very interesting.
Several times we have already wished to see
yield feature in java and all the time came to the same implementation:
infomancers-collections.
And every time with dissatisfaction turned away, and continued with regular
iterators.
Why? Well, in spite of the fact it's the best implementation of the feature we have
seen, it's still too heavy, as it's playing with java byte code at run-time.
We never grasped the idea why it's done this way, while there is
post-compile
time annotation processing in java.
If we would implemented the yeild feature in java we would created a @Yield
annotation and would demanded to implement some well defined code pattern like
this:
@Yield
Iteratable<String> iterator()
{
// This is part of pattern.
ArrayList<String> list = new ArrayList<String>();
for(int i = 0; i < 10; ++i)
{
// list.add() plays the role of yield return.
list.add(String.valueOf(i));
}
// This is part of pattern.
return list;
}
or
@Yield
Iterator<String> iterator()
{
// This is part of pattern.
ArrayList<String> list = new ArrayList<String>();
for(int i = 0; i < 10; ++i)
{
// list.add() plays the role of yield return.
list.add(String.valueOf(i));
}
// This is part of pattern.
return list.iterator();
}
Note that the code will work correctly even, if by mischance, post-compile-time
processing will not take place.
At post comile time we would do all required refactoring to turn these
implementations into a state machines thus runtime would not contain any third
party components.
It's iteresting to recall that we have also implemented similar refactoring in
pure xslt.
See What you can do with jxom.
Update: implementation can be found at Yield.zip
Michael Key, author of the Saxon xslt processor, being inspired by the GWT
ideas, has decided to compile Saxon HE into javascript. See
Compiling Saxon using GWT.
The resulting script is about 1MB of size.
But what we thought lately, that it's overkill to bring whole xslt engine on a
client, while it's possible to generate javascript from xslt the same way as he's building java from xquery. This will probably require some runtime
but of much lesser size.
Search at www.google.fr:
An empty sequence is not allowed as the @select attribute of xsl:analyze-string
That's known issue. See Bug 7976.
In xslt 2.0 you should either check the value before using xsl:analyze-string, or wrap it into string() call.
The problem is addressed in xslt 3.0
Recently we've seen a code like this:
<xsl:variable name="a" as="element()?" select="..."/>
<xsl:variable name="b" as="element()?" select="..."/>
<xsl:apply-templates select="$a">
<xsl:with-param name="b" tunnel="yes" as="element()" select="$b"/>
</xsl:apply-templates>
It fails with an error:
"An empty sequence is not allowed as the value of parameter $b".
What is interesting is that the value of $a is an empty sequence,
so the code could potentially work, provided processor evaluated $a first,
and decided not to evaluate xsl:with-param.
Whether the order of evaluation of @select and xsl:with-param is specified
by the standard or it's an implementation defined?
We asked this question on
xslt forum, and got the following answer:
The specification leaves this implementation-defined. Since the values
of the parameters are the same for every node processed, it's a
reasonably strategy for the processor to evaluate the parameters before
knowing how many selected nodes there are, though I guess an even better
strategy would be to do it lazily when the first selected node is found.
Well, that's an expected answer. This question will probably induce Michael Kay
to introduce a small optimization into the Saxon.
Suppose you have a timestamp string, and want to check whether it fits to one of the
following formats with leading and trailing spaces:
- YYYY-MM-DD-HH.MM.SS.NNNNNN
- YYYY-MM-DD-HH.MM.SS
- YYYY-MM-DD
We decided to use regex and its capture groups to extract timestamp parts. This
left us with only solution: xsl:analyze-string instruction. It took
a couple more minutes to reach a final solution:
<xsl:variable name="parts" as="xs:string*">
<xsl:analyze-string select="$value"
regex="
^\s*(\d\d\d\d)-(\d\d)-(\d\d)
(-(\d\d)\.(\d\d)\.(\d\d)(\.(\d\d\d\d\d\d))?)?\s*$"
flags="x">
<xsl:matching-substring>
<xsl:sequence select="regex-group(1)"/>
<xsl:sequence select="regex-group(2)"/>
<xsl:sequence select="regex-group(3)"/>
<xsl:sequence select="regex-group(5)"/>
<xsl:sequence select="regex-group(6)"/>
<xsl:sequence select="regex-group(7)"/>
<xsl:sequence select="regex-group(9)"/>
</xsl:matching-substring>
</xsl:analyze-string>
</xsl:variable>
<xsl:choose>
<xsl:when test="exists($parts)">
...
</xsl:when>
<xsl:otherwise>
...
</xsl:otherwise>
</xsl:choose>
How would you solve the problem? Is it the best solution?
One of our latest tasks was a conversion of data received from mainframe as an EBCDIC flat file into an XML file in UTF-8 encoding for further processing.
The solution was rather straightforward:
- read the source flat file, record-by-record;
- serialize each record as an element into target XML file using JAXB.
For reading data from EBCDIC encoded flat file, a good old tool named eXperanto was used. It allows to define C# and/or Java classes that suit for records in the source flat file. Thus we were able to read and convert records from EBCDIC to UTF-8.
The next sub-task was to serialize a Java bean to an XML element. JAXB marshaller was used for this.
Everything was ok, until we had started to test the implementation on real data.
We've realized that some decimal values (BigDecimal fields in Java classes) were serialized in scientific exponential notation. For example: 0.000000365 was serialized as 3.65E-7 and so on.
On the other hand, the target XML was used by another (non Java) application, which expected to receive decimal data, as it was defined in XSD schema (the field types were specified as xs:decimal).
According with W3C datatypes specification:
"...decimal has a lexical representation consisting of a finite-length sequence of decimal digits (#x30-#x39) separated by a period as a decimal indicator. An optional leading sign is allowed. If the sign is omitted, "+" is assumed. Leading and trailing zeroes are optional. If the fractional part is zero, the period and following zero(es) can be omitted. For example: -1.23, 12678967.543233, 100000.00, 210..."
So, the result was predictable, the consumer application fails.
Google search reveals that we deal with a well-known bug: "JAXB marshaller returns BigDecimal with scientific notation in JDK 6". It remains open already an year and half since May 2009, marked as "Fix in progress". We've tested our application with Java version 1.6.0_21-b07, JAXB 2.1.
Although this is rather critical bug that may affect on interoperability of Java applications (e.g. Java web services etc.), its priority was set just as "4-Low".
P.S. as a temporary workaround for this case only(!) we've replaced xs:decimal on xs:double in XSD schema for the target application.
Accidentally we have found that implementation of String and StringBuilder
have been considerably revised, while public interface has remained the
same.
public sealed class String
{
private int m_arrayLength;
private int m_stringLength;
private char
m_firstChar;
}
This layout is dated to .NET 1.0.
VM, in fact, allocates more memory than that defined in C# class, as
&m_firstChar refers to an inline char buffer.
This way string's buffer length and string's length were two different
values, thus StringBuilder used this fact and stored its content in a private string
which it modified in place.
In .NET 4, string is different:
public sealed class String
{
private int m_stringLength;
private char
m_firstChar;
}
Memory footprint of such structure is smaller, but string's length should
always be the same as its buffer. In fact layout of string is now the same as
layout of char[].
This modification leads to implementation redesign of the StringBuilder.
Earlier, StringBuilder looked like the following:
public sealed class StringBuilder
{
internal IntPtr m_currentThread;
internal int m_MaxCapacity;
internal volatile
string m_StringValue;
}
Notice that m_StringValue is used as a storage, and
m_currentThread is used to preserve thread affinity of the internal
string value.
Now, guys at Microsoft have decided to implement StringBuilder very differently:
public sealed class StringBuilder
{
internal int m_MaxCapacity;
internal int m_ChunkLength;
internal int m_ChunkOffset;
internal char[] m_ChunkChars;
internal StringBuilder m_ChunkPrevious;
}
Inspection of this layout immediately reveals implementation technique. It's a
list of chunks. Instance itself references the last chunk (most recently
appended), and the previous chunks.
Characteristics of this design are:
- while
Length is small, performance almost the same as it was earlier;
- there are no more thread affinity checks;
Append(), and ToString() works as fast a in the old version.Insert() in the middle works faster, as only a chuck should be splitted and
probably reallocated (copied), instead of the whole string;- Random access is fast at the end O(1) and slows when you approaching the start
O(chunk-count).
Personally, we would select a slightly different design:
public sealed class StringBuilder
{
private struct Chunk
{
public int length; // Chunk length.
public int offset; // Chunk offset.
public char[] buffer;
}
private int m_MaxCapacity;
// Alternatively, one can use
// private List<Chunk> chunks;
private int chunkCount; // Number of used chunks.
private Chunk[] chunks; // Array of chunks except last.
private Chunk last; // Last chunk.
private bool nonHomogenous; // false if all chunks are of the same size.
}
This design has better memory footprint, and random access time is O(1) when there were no
inserts in the middle (nonHomogenous=false), and
O(log(chunkCount)) after such inserts. All other characteristics are the
same.
We have run into another xslt bug, which depends on several independent
circumstances and often behaves differently being observed. That's clearly a
Heisenbug.
Xslt designers failed to realize that a syntactic suggar they introduce into
xpath can turn into obscure bugs. Well, it's easy to be wise afterwards...
To the point.
Consider you have a sequence consisting of text nodes and
elements, and now you want to "normalize" this sequence wrapping
adjacent text nodes into
separate elements. The following stylesheet is supposed to do the work:
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:t="http://www.nesterovsky-bros.com/xslt/this"
exclude-result-prefixes="xs t">
<xsl:template match="/">
<xsl:variable
name="nodes" as="node()*">
<xsl:text>Hello, </xsl:text>
<string value="World"/>
<xsl:text>! </xsl:text>
<xsl:text>Well, </xsl:text>
<string value="hello"/>
<xsl:text>, if not joking!</xsl:text>
</xsl:variable>
<result>
<xsl:sequence
select="t:normalize($nodes)"/>
</result>
</xsl:template>
<xsl:function
name="t:normalize" as="node()*">
<xsl:param name="nodes" as="node()*"/>
<xsl:for-each-group select="$nodes" group-starting-with="*">
<xsl:variable
name="string" as="element()?" select="self::string"/>
<xsl:variable name="texts"
as="node()*"
select="current-group() except $string"/>
<xsl:sequence
select="$string"/>
<xsl:if test="exists($texts)">
<string
value="{string-join($texts, '')}"/>
</xsl:if>
</xsl:for-each-group>
</xsl:function>
</xsl:stylesheet>
We're expecting the following output:
<result>
<string value="Hello, "/>
<string value="World"/>
<string value="! Well, "/>
<string value="hello"/>
<string value=", if not joking!"/>
</result>
But often we're getting other results, like:
<result>
<string value="Hello, "/>
<string value="World"/>
<string value="Well, ! "/>
<string value="hello"/>
<string value=", if not joking!"/>
</result>
Such output may seriously confuse, unless you will recall the rule for the
xpath except operator:
The except operator takes two node sequences as operands and returns a sequence containing all the nodes that occur in the first operand but not in the second operand.
... these operators eliminate duplicate nodes from their result sequences based
on node identity. The resulting sequence is returned in document order..
...
The relative order of nodes in distinct trees is stable but implementation-dependent
These words mean that result sequence may be very different from original
sequence.
In contrast, if we change $text definition to:
<xsl:variable name="texts"
as="node()*"
select="current-group()[not(. is $string)]"/>
then the result becomes stable, but less clear.
See also
Xslt Heisenbug
It does not matter that DataBindExtender looks not usual in the ASP.NET. It turns to be so handy that built-in data binding is not considered to be an option.
After a short try, you uderstand that people tried very hard and have invented many controls and methods like ObjectDataSource, FormView, Eval(), and Bind() with outcome, which is very specific and limited.
In contrast DataBindExtender performs:
- Two or one way data binding of any business data property to any control property;
- Converts value before it's passed to the control, or into the business data;
- Validates the value.
See an example:
<asp:TextBox id=Field8 EnableViewState="false" runat="server"></asp:TextBox>
<bphx:DataBindExtender runat='server'
EnableViewState='false'
TargetControlID='Field8'
ControlProperty='Text'
DataSource='<%# Import.ClearingMemberFirm %>'
DataMember='Id'
Converter='<%# Converters.AsString("XXXXX", false) %>'
Validator='<%# (extender, value) => Functions.CheckID(value as string) %>'/>
Here, we beside a regualar two way data binding of a property Import.ClearingMemberFirm.Id to a property Field8.Text, format (parse) Converters.AsString("XXXXX", false), and finally validate an input value with a lambda function (extender, value) => Functions.CheckID(value as string).
DataBindExtender works also well in template controls like asp:Repeater, asp:GridView, and so on. Having your business data available, you may reduce a size of the ViewState with EnableViewState='false'. This way DataBindExtender approaches page development to a pattern called MVC.
Recently, we have found that it's also useful to have a way to run a javascript during the page load (e.g. you want to attach some client side event, or register a component). DataBindExtender provides this with OnClientInit property, which is a javascript to run on a client, where this refers to a DOM element:
... OnClientInit='$addHandler(this, "change", function() { handleEvent(event, "Field8"); } );'/>
allows us to attach onchange javascript event to the asp:TextBox.
So, meantime we're very satisfied with what we can achieve with DataBindExtender. It's more than JSF allows, and much more stronger and neater to what ASP.NET has provided.
The sources can be found at DataBindExtender.cs
Lately, we have found that we've accustomed to declare C#'s local variables using var:
var exitStateName = exitState == null ? "" : exitState.Name;
var rules = Environment.NavigationRules;
var rule = rules[caller.Name];
var flow = rule.NavigationCases[procedure.OriginExitState];
This makes code cleaner, and in presense of good IDE still allows to figure out
types very easely.
We, howerer, found that var tends to have exceptions in its
uses. E.g. for some reason most of boolean locals in our code tend to remain explicit
(matter of taste?):
bool succeed = false;
try
{
...
succeed = true;
}
finally
{
if (!succeed)
{
...
}
}
Also, type often survives in for, but not in foreach:
for(int i = 0; i < sourceDataMapping.Length;
++i)
{
...
}
foreach(var property in properties)
{
...
}
In addition var has some limitations, as one cannot easily
initialize such local with null. From the following we prefer the first approach:
IWindowContext context = null;var context = (IWindowContext)null;var context = null as IWindowContext;var context = default(IWindowContext);
We might need to figure out a consistent code style as for var. It
might be like that:
- Numeric, booleans and string locals should use explicit type;
- Try to avoid locals initialized with null, or without initializer, or use type
if such variable cannot be avoided;
- Use var in all other cases.
Another code style could be like that:
- For the consistency, completely avoid the use of keyword
var.
Recently we were raising a question about serialization of ASPX output in xslt.
The question went like this:
What's the recommended way of ASPX page generation?
E.g.:
------------------------
<%@ Page AutoEventWireup="true"
CodeBehind="CurMainMenuP.aspx.cs"
EnableSessionState="True"
Inherits="Currency.CurMainMenuP"
Language="C#"
MaintainScrollPositionOnPostback="True"
MasterPageFile="Screen.Master" %>
<asp:Content ID="Content1" runat="server" ContentPlaceHolderID="Title">CUR_MAIN_MENU_P</asp:Content>
<asp:Content ID="Content2" runat="server" ContentPlaceHolderID="Content">
<span id="id1222146581" runat="server"
class="inputField system UpperCase" enableviewstate="false">
<%# Dialog.Global.TranCode %>
</span>
...
------------------------
Notice aspx page directives, data binding expessions, and prefixed tag names without namespace declarations.
There was a whole range of expected answers. We, however, looked whether somebody have already dealed with the task and has a ready solution at hands.
In general it seems that xslt community is very angry about ASPX: both format and technology. Well, put this aside.
The task of producing ASPX, which is almost xml, is not solvable when you're staying with pure xml serializer. Xslt's xsl:character-map does not work at all. In fact it looks as a childish attempt to address the problem, as it does not support character escapes but only grabs characters and substitutes them with strings.
We have decided to create ASPX serializer API producing required output text. This way you use <xsl:output method="text"/> to generate ASPX pages.
With this goal in mind we have defined a little xml schema to describe ASPX irregularities in xml form. These are:
<xs:element name="declared-prefix"> - to describe known prefixes, which should not be declared;
<xs:element name="directive"> - to describe directives like <%@ Page %>;
<xs:element name="content"> - a transparent content wrapper;
<xs:element name="entity"> - to issue xml entity;
<xs:element name="expression"> - to describe aspx expression like <%# Eval("A") %>;
<xs:element name="attribute"> - to describe an attribute of the parent element.
This approach greately simplified for us an ASPX generation process.
The API includes:
In previous posts we were crying about problems with JSF to ASP.NET migration. Let's point to another one.
Consider that you have an input field, whose value should be validated:
<input type="text" runat="server" ID="id1222146409" maxlength="4"/>
<bphx:DataBindExtender runat="server"
TargetControlID="id1222146409" ControlProperty="Value"
DataSource="<%# Import.AaControlAttributes %>"
DataMember="UserEnteredTrancode"/>
Here we have an input control, whose value is bound to Import.AaControlAttributes.UserEnteredTrancode property. But what is missed is a value validation. Somewhere we have a function that could answer the question whether the value is valid. It should be called like this: Functions.IsTransactionCodeValid(value).
Staying within standard components we can use a custom validator on the page:
<asp:CustomValidator runat="server"
ControlToValidate="id1222146409"
OnServerValidate="ValidateTransaction"
ErrorMessage="Invalid transaction code."/>
and add the following code-behind:
protected void ValidateTransaction(object source, ServerValidateEventArgs args)
{
args.IsValid = Functions.IsTransactionCodeValid(args.Value);
}
This approach works, however it pollutes the code-behind with many very similar methods. The problem is that the validation rules in most cases are not property of page but one of data model. That's why page validation methods just forward check to somewhere.
While thinking on how to simplify the code we have came up with more conscious and short way to express validators, namely using lambda functions. To that end we have introduced a Validator property of type ValueValidator over DataBindExtender. Where
/// <summary>A delegate to validate values.</summary>
/// <param name="extender">An extender instance.</param>
/// <param name="value">A value to validate.</param>
/// <returns>true for valid value, and false otherwise.</returns>
public delegate bool ValueValidator(DataBindExtender extender, object value);
/// <summary>An optional data member validator.</summary>
public virtual ValueValidator Validator { get; set; }
With this new property the page markup looks like this:
<input type="text" runat="server" ID="id1222146409" maxlength="4"/>
<bphx:DataBindExtender runat="server"
TargetControlID="id1222146409" ControlProperty="Value"
DataSource="<%# Import.AaControlAttributes %>"
DataMember="UserEnteredTrancode"
Validator='<%# (extender, value) => Functions.IsTransactionCodeValid(value as string) %>'
ErrorMessage="Invalid transaction code."/>
This is almost like an event handler, however it allowed us to call data model validation logic without unnecessary code-behind.
The updated DataBindExtender can be found at DataBindExtender.cs.
Being well behind of the latest news and traps of the ASP.NET, we're readily falling on each problem.
This time it's a script injection during data binding.
In JSF there is a component to output data called h:outputText. Its use is like this:
<span jsfc="h:outputText" value="#{myBean.myProperty}"/>
The output is a span element with data bound value embeded into content. The natural alternative in ASP.NET seems to be an asp:Label control:
<asp:Label runat="server" Text="<%# Eval("MyProperty") %>"/>
This almost works except that the h:outputText escapes data (you may override this and specify attribute escape="false"), and asp:Label never escapes the data.
This looks as a very serious omission in ASP.NET (in fact very close to a security hole). What are chances that when you're creating a new page, which uses data binding, you will not forget to fix code that wizard created for you and to change it to:
<asp:Label runat="server" Text="<%# Server.HtmlEncode(Eval("MyProperty")) %>"/>
Eh? Think what will happen if MyProperty will return a text that looks like a script (e.g.: <script>alert(1)</script>), while you just wanted to output a label?
To address the issue we've also introduced a property Escape into DataBindExtender. So at present we have a code like this:
<asp:Label runat="server" ID="MyLabel"/>
<bphx:DataBindExtender runat="server" TargetControlID="MyLabel"
ControlProperty="Text" ReadOnly="true" Escape="true"
DataSource="<%# MyBean %>" DataMember="MyProperty"/>
See also: A DataBindExtender, Experience of JSF to ASP.NET migration
After struggling with ASP.NET data binding we found no other way but to introduce our little extender control to address the issue.
We were trying to be minimalistic and to introduce two way data binding and to support data conversion. This way extender control (called DataBindExtender) have following page syntax:
<asp:TextBox id=TextBox1 runat="server"></asp:TextBox>
<cc1:DataBindExtender runat="server"
DataSource="<%# Data %>"
DataMember="ID"
TargetControlID="TextBox1"
ControlProperty="Text" />
Two way data binding is provided with DataSource object (notice data binding over this property) and a DataMember property from the one side, and TargetControlID and ControlProperty from the other side. DataBindExtender supports Converter property of type TypeConverter to support custom converters.
DataBindExtender is based on AjaxControlToolkit.ExtenderControlBase class and implements System.Web.UI.IValidator. ExtenderControlBase makes implementation of extenders extremely easy, while IValidator plugs natuarally into page validation (Validate method, Validators collections, ValidationSummary control).
The good point about extenders is that they are not visible in designer, while it exposes properties in extended control itself. The disadvantage is that it requires Ajax Control Toolkit, and also ScriptManager component of the page.
To simplify the use DataBindExtender gets data from control and puts the value into data source in Validate method, and puts data into control in OnPreRender method; thus no specific action is required to perform data binding.
Source for the DataBindExtender is DataBindExtender.cs.
At times a simple task in xslt looks like a puzzle. Today we have this one.
For a string and a regular expression find a position and a length of the matched
substring.
The problem looks so simple that you do not immediaty realize that you are going
to spend ten minutes trying to solve it in the best way.
Try it yourself before proceeding:
<xsl:variable name="match" as="xs:integer*">
<xsl:analyze-string select="$line"
regex="my-reg-ex">
<xsl:matching-substring>
<xsl:sequence select="1, string-length(.)"/>
</xsl:matching-substring>
<xsl:non-matching-substring>
<xsl:sequence select="0, string-length(.)"/>
</xsl:non-matching-substring>
</xsl:analyze-string>
</xsl:variable>
<xsl:choose>
<xsl:when test="$match[1]">
<xsl:sequence
select="1, $match[2]"/>
</xsl:when>
<xsl:when test="$match[3]">
<xsl:sequence select="$match[2], $match[4]"/>
</xsl:when>
</xsl:choose>
To see that the problem with Generator functions in xslt
is a bit more complicated compare two functions.
The first one is quoted from the earlier post:
<xsl:function name="t:generate" as="xs:integer*">
<xsl:param name="value" as="xs:integer"/>
<xsl:sequence select="$value"/>
<xsl:sequence select="t:generate($value * 2)"/>
</xsl:function>
It does not work in Saxon: crashes with out of memory.
The second one is slightly modified version of the same function:
<xsl:function name="t:generate" as="xs:integer*">
<xsl:param name="value" as="xs:integer"/>
<xsl:sequence select="$value + 0"/>
<xsl:sequence select="t:generate($value * 2)"/>
</xsl:function>
It's working without problems. In first case Saxon decides to cache all
function's output, in the second case it decides to evaluate data lazily on
demand.
It seems that optimization algorithms implemented in Saxon are so plentiful and
complex that at times they fool one another. :-)
See also:
Generator functions
At some point we needed to have an array with volatile elements in java.
We knew that such beast is not found in the java world. So we searched
the Internet and found the answers that are so wrong, and introduce so obscure
threading bugs that the guys who provided them would better hide them and run immediately to fix their
buggy programs...
The first one is
Volatile arrays
in Java. They suggest such solution:
volatile int[] arr = new int[...];
...
arr[4] = 100;
arr = arr;
The number two:
What Volatile Means in Java
A guy assures that this code works:
Fields:
int answer = 0;
volatile boolean ready = false;
Thread1:
answer = 42;
ready = true;
Thread2:
if (ready)
{
print(answer);
}
They are very wrong! Non volatile access can be reordered by the implementation.
See Java's
Threads and Locks:
The rules for volatile variables effectively require that main memory be touched exactly once for each use or assign of a volatile variable by a thread, and that main memory be touched in exactly the order dictated by the thread execution semantics. However, such memory actions are not ordered with respect to read and write actions on nonvolatile variables.
They probably thought of locks when they argued about volatiles:
a lock action acts as if it flushes all variables from the
thread's working memory; before use they must be assigned or loaded from main
memory.
P.S. They would better recommend
AtomicReferenceArray.
jxom else if (google search)
Google helps with many things but with retrospective support.
Probably guy's trying to build a nested if then else
jxom elements.
We expected this and have defined a function
t:generate-if-statement() in
java-optimizer.xslt.
Its signature:
<!--
Generates if/then/else if ... statements.
$closure - a series of conditions and blocks.
$index - current index.
$result - collected result.
Returns if/then/else if ... statements.
-->
<xsl:function name="t:generate-if-statement" as="element()">
<xsl:param name="closure" as="element()*"/>
<xsl:param name="index" as="xs:integer"/>
<xsl:param name="result" as="element()?"/>
Usage is like this:
<!-- Generate a sequence of pairs: (condition, scope). -->
<xsl:variable name="branches" as="element()+">
<xsl:for-each select="...">
<!-- Generate condition. -->
<scope>
<!-- Generate statemetns. -->
</scope>
</xsl:for-each>
</xsl:variable>
<xsl:variable name="else" as="element()?">
<!-- Generate final else, if any. -->
</xsl:variable>
<!-- This generates if statement. -->
<xsl:sequence
select="t:generate-if-statement($branches, count($branches)
- 1, $else)"/>
P.S. By the way, we like that someone is looking into jxom.
The very same simple tasks tend to appear in different languages (e.g.
C# Haiku).
Now we have to find:
- integer and fractional part of a decimal;
- length and precision of a decimal.
These tasks have no trivial solutions in xslt 2.0.
At present we have came up with the following answers:
Fractional part:
<xsl:function name="t:fraction" as="xs:decimal">
<xsl:param name="value" as="xs:decimal"/>
<xsl:sequence select="$value mod 1"/>
</xsl:function>
Integer part v1:
<xsl:function name="t:integer" as="xs:decimal">
<xsl:param name="value" as="xs:decimal"/>
<xsl:sequence select="$value - t:fraction($value)"/>
</xsl:function>
Integer part v2:
<xsl:function name="t:integer" as="xs:decimal">
<xsl:param name="value" as="xs:decimal"/>
<xsl:sequence select="
if ($value ge 0) then
floor($value)
else
-floor(-$value)"/>
</xsl:function>
Length and precision:
<!--
Gets a decimal specification as a closure:
($length as xs:integer, $precision as xs:integer).
-->
<xsl:function
name="t:decimal-spec" as="xs:integer+">
<xsl:param name="value"
as="xs:decimal"/>
<xsl:variable name="text" as="xs:string" select="
if ($value
lt 0) then
xs:string(-$value)
else
xs:string($value)"/>
<xsl:variable
name="length" as="xs:integer"
select="string-length($text)"/>
<xsl:variable
name="integer-length" as="xs:integer"
select="string-length(substring-before($text, '.'))"/>
<xsl:sequence select="
if
($integer-length) then
($length - 1, $length - $integer-length - 1)
else
($length, 0)"/>
</xsl:function>
The last function looks odious. In many other languages its implementation
would be considered as embarrassing.
Given:
public class N
{
public readonly N next;
}
What needs to be done to construct a ring of N: n1 refers to n2, n2 to n3, ... nk to n1? Is it possible?
To end with immutable trees, at least for now, we've implemented IDictionary<K, V>.
It's named Map<K, V>. Functionally it looks very like SortedDictionary<K, V>.
there are some differences, however:
Map in contrast to SortedDictionary is very cheap on
copy.- Bacause
Map is based on AVL tree, which is more rigorly balanced
than RB tree, so it's a little bit faster asymptotically for lookup than SortedDictionary,
and a little bit slower on modification.
- Due to the storage structure: node + navigator,
Map consumes less memory than
SortedDictionary, and is probably cheaper for GC (simple garbage
graphs).
- As AVL tree stores left and right subtree sizes, in contrast to a "color" in
RB tree, we able to index data in two ways: with integer index, and with key
value.
Sources are:
Update:
It was impossible to withstand temptation to commit some primitive performance
comparision. Map outperforms SortedDictionary both in population and in access.
this does not aggree with pure algorithm's theory, but there might be other
unaccounted factors: memory consumption, quality of implementation, and so on.
Program.cs is updated with measurements.
Update 2:
More occurate tests show that for some key types Map's faster, for others
SortedDictionary's faster. Usually Map's slower during population (mutable AVL
tree navigator may fix this). the odd thing is that Map<string, int> is faster
than SortedDictionary<string, int> both for allocaction and for access. See
excel report.
Update 3:
Interesing observation. The following table shows maximal and
average tree heights for different node sizes in AVL and RB trees after a random population:
|
AVL |
RB |
| Size |
Max |
Avg |
Max |
Avg |
| 10 |
4 |
2.90 |
5 |
3.00 |
| 50 |
7 |
4.94 |
8 |
4.94 |
| 100 |
8 |
5.84 |
9 |
5.86 |
| 500 |
11 |
8.14 |
14 |
8.39 |
| 1000 |
12 |
9.14 |
16 |
9.38 |
| 5000 |
15 |
11.51 |
18 |
11.47 |
| 10000 |
16 |
12.53 |
20 |
12.47 |
| 50000 |
19 |
14.89 |
23 |
14.72 |
| 100000 |
20 |
15.90 |
25 |
15.72 |
| 500000 |
25 |
18.26 |
28 |
18.27 |
| 1000000 |
25 |
19.28 |
30 |
19.27 |
Here, according with theory, the height of AVL tree is shorter than the height
of RB tree. But what is most interesting is that the depth of an "average
node". This value describes a number of steps required to find a random key. RB
tree is very close and often is better than AVL in this regard.
It was obvious as hell from day one of generics that there will appear obscure
long names when you will start to parametrize your types. It was the easiest
thing in the world to take care of this in advanvce. Alas, C# inherits C++'s bad
practices.
Read Associative containers in a functional languages
and
Program.cs to see what we're talking about.
Briefly, there is a pair (string, int), which in C# should be declared as:
System.Collections.Generic.KeyValuePair<string, int>
Obviously we would like to write it in a short way. These are our attempts, which
fail:
1. Introduce generic alias Pair<K, V>:
using System.Collections.Generic;
using Pair<K, V> = KeyValuePair<K, V>;
2. Introduce type alias for a generic type with specific types.
using System.Collections.Generic;
using Pair = KeyValuePair<string, int>;
And this is only one that works:
using Pair = System.Collections.Generic.KeyValuePair<string, int>;
Do you think is it bearable? Well, consider the following:
- There is a generic type
ValueNode<T>, where T
should be Pair.
- There is a generic type
TreeNavigator<N>, where N is should be ValueNode<Pair>.
The declaration looks like this:
using Pair = System.Collections.Generic.KeyValuePair<string, int>;
using Node = NesterovskyBros.Collections.AVL.ValueNode<
System.Collections.Generic.KeyValuePair<string, int>>;
using Navigator = NesterovskyBros.Collections.AVL.TreeNavigator<
NesterovskyBros.Collections.AVL.ValueNode<
System.Collections.Generic.KeyValuePair<string, int>>>;
Do you still think is it acceptable?
P.S. Legacy thinking led C#'s and java's designers to the use of word "new" for the
object construction. It is not required at all. Consider new Pair("A", 1) vs Pair("A", 1).
C++ prefers second form. C# and java always use the first one.
Continuing with the post "Ongoing xslt/xquery spec update"
we would like to articulate what options regarding associative containers do we
have in a functional languages (e.g. xslt, xquery), assuming that variables are
immutable and implementation is efficient (in some sense).
There are three common implementation techniques:
- store data (keys, value pairs) in sorted array, and use binary search to
access values by a key;
- store data in a hash map;
- store data in a binary tree (usually RB or AVL trees).
Implementation choice considerably depends on operations, which are taken over
the container. Usually these are:
- construction;
- value lookup by key;
- key enumeration (ordered or not);
- container modification (add and remove data into the
container);
- access elements by index;
Note that modification in a functional programming means a creation of a new
container, so here is a
division:
- If container's use pattern does not include modification, then probably the
simplest solution is to build it as an ordered sequence of
pairs, and use binary search to access the data. Alternatively, one could
implement associative container as a hash map.
- If modification is essential then neither ordered sequence of pairs, hash map
nor classical tree implementation can be used, as they are either too slow
or too greedy for a memory, either during modification or during access.
On the other hand to deal with container's modifications one can build
an implementation, which uses "top-down" RB
or AVL trees. To see the
difference consider a classical tree structure and its functional variant:
|
Classical |
Functional |
| Node structure: |
node
parent
left
right
other data |
node
left
right
other data |
| Node reference: |
node itself |
node path from a root of a tree |
| Modification: |
either mutable or requires a completely new tree |
O(LnN) nodes are created
|
Here we observe that:
- one can implement efficient map (lookup time no worse than O(LnN)) with no
modification support, using ordered array;
- one can implement efficient map with support of modification, using immutable binary tree;
- one can implement all these algorithms purely in xslt and xquery (provided that inline
functions are supported);
- any such imlementation will lose against the same implementation
written in C++, C#, java;
- the best implementation would probably start from sorted array and
will switch to binary tree after some size threshold.
Here we provide a C# implementation of a functional AVL tree, which also supports
element indexing:
Our intention was to show that the usual algorithms for associative
containers apply in functional
programming; thus a feature complete functional language must support
associative containers to make development more conscious, and to free a
developer from inventing basic things existing already for almost a half of
century.
A client asked us to produce Excel reports in ASP.NET
application. They've given an Excel templates, and also defined what they want to show.
What are our options?
- Work with Office COM API;
- Use Office Open XML SDK (which is a set of pure .NET
API);
- Try to apply xslt somehow;
- Macro, other?
For us, biased to xslt, it's hard to make a fair choice. To judge, we've
tried formalize client's request and to look into future support.
So, we have defined sql stored procedures to provide the data. This way data can be
represented either as ADO.NET DataSet, a set of classes, as xml, or in other reasonable format. We do not
predict any considerable problem with data representation if client will decide
to modify reports in future.
It's not so easy when we think about Excel generation.
Due to ignorance we've thought that Excel is much like xslt in some regard, and
that it's possible to provide a tabular data in some form and create Excel
template, which will consume the data to form a final output. To some extent
it's possible, indeed, but you should start creating macro or vb scripts to
achieve acceptable results.
When we've mentioned macroses to the client, they immediately stated that
such a solution won't work due to security reasons.
Comparing COM API and Open XML SDK we can see that both provide almost the same
level of service for us, except that the later is much more lighter and supports only Open XML format, and the earlier is a heavy
API exposing MS Office and supports earlier versions also.
Both solutions have a considerable drawback: it's not easy to create Excel
report in C#, and it will be a pain to support such solution if client will ask,
say in half a year, to modify something in Excel template or to create one more
report.
Thus we've approached to xslt. There we've found two more directions:
- generate data for Office Open XML;
- generate xml in format of MS Office 2003.
It's turned out that it's rather untrivial task to generate data for Open XML,
and it's not due to the format, which is not xml at all but a zipped folder
containing xmls. The problem is in the complex schemas and in many complex
relations between files constituting Open XML document. In contrast, MS
Office 2003 format allows us to create a single xml file for the spreadsheet.
Selecting between standard and up to date format, and older proprietary one, the
later looks more attractive for the development and support.
At present we're at position to use xslt and to generate files in MS Office
2003 format. Are there better options?
Did you ever hear that double numbers may cause roundings, and that
many financial institutions are very sensitive to those roundings?
Sure you did! We're also aware of this kind of problem, and we thought we've
taken care of it. But things are not that simple, as you're not always
know what an impact the problem can have.
To understand the context it's enough to say that we're converting (using xslt by the way) programs
written in a CASE tool called
Cool:GEN into java and into C#. Originally, Cool:GEN generated COBOL and C
programs as deliverables. Formally, clients compare COBOL results vs java or C#
results, and they want them to be as close as possible.
For one particular client it was crucial to have correct results during
manipulation with numbers with 20-25 digits in total, and with 10 digits after a decimal point.
Clients are definitely right, and we've introduced generation options to control
how to represent numbers in java and C# worlds; either as double or
BigDecimal (in java), and decimal (in C#).
That was our first implementation. Reasonable and clean. Was it enough? - Not at
all!
Client's reported that java's results (they use java and BigDecimal
for every number with decimal point) are too precise, comparing to Mainframe's
(MF) COBOL. This rather unusuall complain puzzles a litle, but client's
confirmed that they want no more precise results than those MF produces.
The reason of the difference was in that that both C# and especially java may
store much more decimal digits than is defined for the particualar result on MF.
So, whenever you define a field storing 5 digits after decimal point, you're
sure that exactly 5 digits will be stored. This contrasts very much with results
we had in java and C#, as both multiplication and division can produce many more
digits after the decimal point. The solution was to truncate(!) (not to round) the
numbers to the specific precision in property setters.
So, has it resolved the problem? - No, still not!
Client's reported that now results much more better (coincide with MF, in fact)
but still there are several instances when they observe differences in 9th and
10th digits after a decimal point, and again java's result are more accurate.
No astonishment this time from us but analisys of the reason of the difference.
It's turned out that previous solution is partial. We're doing a final truncation
but still there were intermediate results like in a/(b * c), or in a * (b/c).
For the intermediate results MF's COBOL has its, rather untrivial, formulas (and
options) per each operation defining the number of digits to keep after a
decimal point. After we've added similar options into the generator, several
truncations've manifested in the code to adjust intermediate results. This way
we've reached the same accurateness as MF has.
What have we learned (reiterated)?
- A simple problems may have far reaching impact.
- More precise is not always better. Client often prefers compatible rather than
more accurate results.
For some reason C# lacks a decimal truncation function
limiting result to a specified number of digits after a decimal point. Don't
know what's the reasoning behind, but it stimulates the thoughts. Internet
is plentiful with workarounds. A tipical answer is like this:
Math.Truncate(2.22977777 * 1000) / 1000; // Returns 2.229
So, we also want to provide our solution to this problem.
public static decimal Truncate(decimal value,
byte decimals)
{
decimal result = decimal.Round(value, decimals);
int c = decimal.Compare(value, result);
bool negative = decimal.Compare(value, 0) < 0;
if (negative ? c <= 0 : c >= 0)
{
return result;
}
return result - new decimal(1, 0, 0, negative, decimals);
}
Definitely, if the function were implemented by the framework it were much more efficient. We assume, however, that above's the best implementation that can be done externally.
A natural curiosity led us to the implementation of connection
pooling in Apache Tomcat (org.apache.commons.dbcp).
And what're results do you ask?
Uneasiness... Uneasiness for all those who use it. Uneasiness due to the
difference between our expectations and real implementation.
Briefly the design is following:
- wrap every jdbc object;
- cache prepared statements wrappers;
- lookup prepared statement wrappers in the cache before
asking original driver;
- upon close return wrappers into the cache.
It took us a couple of minutes to see that this is very problematic design, as
it does not address double close of statements properly (jdbc states that is
safe to call close() over closed jdbc object). With Apache's design it's safe
not to touch the object after the close() call, as it returned to the pool and
possibly already given to an other client who requested it.
The correct design would be:
- wrap every jdbc object;
- cache original prepared statements;
- lookup original prepared statement in the cache before asking original
driver, and return wrappers;
- detach wrapper upon close from original object, and put original object
into the cache.
A bit later. We've found a confirmation of our doubts on Apache site: see "JNDI Datasource HOW-TO
", chapter "Common Problems".
Our experience with facelets shows that when you're designing
a composition components you often want to add a level of customization. E.g.
generate
element with or without id, or define class/style if value is specified.
Consider for simplicity that you want to encapsulate a check box and pass
several attributes to it. The first version that you will probably think of is something like
this:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:c="http://java.sun.com/jstl/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:ex="http://www.nesterovsky-bros.com/jsf">
<body>
<!--
Attributes:
id - an optional id;
value - a data binding;
class - an optional element class;
style - an optional element inline style;
onclick - an optional script event handler for onclick event;
onchange - an optional script event handler for onchange event.
-->
<ui:component>
<h:selectBooleanCheckbox
id="#{id}"
value="#{value}"
style="#{style}"
class="#{class}"
onchange="#{onchange}"
onclick="#{onclick}"/>
</ui:component>
</body>
</html>
Be sure, this is not what you have expected. Output will contain all mentioned
attributes, even those, which weren't passed into a component (they will have empty
values). More than that, if you will omit "id", you will get an error like: "emtpy
string is not valid id".
The reason is in the EL! Attributes used in
this example are of type String, thus result of evaluation of value expression is coersed to String.
Values of attributes that weren't passed in are evaluated to null. EL returns ""
while coersing null to String. The interesting thing
is that, if EL were not changing null then those omitted attributes would not appear in the output.
The second attept would probably be:
<h:selectBooleanCheckbox value="#{value}">
<c:if test="#{!empty id}">
<f:attribute name="id" value="#{id}"/>
</c:if>
<c:if test="#{!empty onclick}">
<f:attribute name="onclick" value="#{onclick}"/>
</c:if>
<c:if test="#{!empty onchange}">
<f:attribute name="onchange" value="#{onchange}"/>
</c:if>
<c:if test="#{!empty class}">
<f:attribute name="class" value="#{class}"/>
</c:if>
<c:if test="#{!empty style}">
<f:attribute name="style" value="#{style}"/>
</c:if>
</h:selectBooleanCheckbox>
Be sure, this won't work either (it may work but not as you would expect). Instruction c:if
is evaluated on the stage of the building of a component tree, and not on the
rendering stage.
To workaround the problem you should prevent null to "" conversion in the EL.
That's, in fact, rather trivial to achieve: value expression should evaluate to
an object different from String, whose toString() method returns a required
value.
The final component may look like this:
<h:selectBooleanCheckbox
id="#{ex:object(id)}"
value="#{value}"
style="#{ex:object(style)}"
class="#{ex:object(class)}"
onchange="#{ex:object(onchange)}"
onclick="#{ex:object(onclick)}"/>
where ex:object() is a function defined like this:
public static Object object(final Object value)
{
return new Object()
{
public String toString()
{
return value == null ? null : value.toString();
}
}
}
A bit later: not everything works as we expected. Such approach doesn't work with the validator attribute, whereas it works with converter attribute. The difference between them is that the first attribute should be MethodExpression value, when the second one is ValueExpression value. Again, we suffer from ugly JSF implementation of UOutput component.
Recently we have seen a blog entry: "JSF: IDs and clientIds in Facelets", which provided wrong implementation of the feature.
I'm not sure how useful it is, but here is our approach to the same problem.
In the core is ScopeComponent. Example uses a couple of utility functions defined in Functions. Example itself is found at window.xhtml:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:c="http://java.sun.com/jstl/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:fn="http://java.sun.com/jsp/jstl/functions"
xmlns:ex="http://www.nesterovsky-bros.com/jsf">
<body>
<h:form>
<ui:repeat value="#{ex:sequence(5)}">
<f:subview id="scope" binding="#{ex:scope().value}">
#{scope.id}, #{scope.clientId}
</f:subview>
<f:subview id="script" uniqueId="my-script"
binding="#{ex:scope().value}" myValue="#{2 + 2}">
, #{script.id}, #{script.clientId},
#{script.bindings.myValue.expressionString},
#{ex:value(script.bindings.myValue)},
#{script.attributes.myValue}
</f:subview>
<br/>
</ui:repeat>
</h:form>
</body>
</html>
Update: ex:scope() is made to return a simple bean with property "value".
Another useful example:
<f:subview id="group" binding="#{ex:scope().value}">
<h:inputText id="input" value="#{bean.property}"/>
<script type="text/javascript">
var element = document.getElementById('#{group.clientId}:input');
</script>
</f:subview>
In the section about AJAX, JSF 2.0 spec (final draft) talks about partial requests...
This sounds rather strange. My perception was that the AJAX is about partial responses. What a sense to send partial requests? Requests are comparatively small anyway! Besides, a partial request may complicate restoring component tree on the server and made things fragile, but this largely depends on what they mean with these words.
Recently we were disputing (Arthur vs Vladimir) about the
benefits of ValueExpression references in JSF/Facelets.
Such dispute in itself presents rather funny picture when
you're defending one position and after a while you're taking opposite
point
and starting to maintain it. But let's go to the problem.
JSF/Facelets uses
Unified
Expression Language for the data binding, e.g.:
<h:inputText id="name" value="#{customer.name}" />
or
<h:selectBooleanCheckbox id="selected" value="#{customer.selected}" />
In these cases value from input and check boxes are mapped to a properties name, and selected of a bean named customer.
Everything is fine except of a case when selected
is not of boolean type (e.g. int). In this case you will have a hard time thinking
on how to adapt bean property to the jsf component. Basically, you have to
provide a bean adapter, or change type of property. Later is
unfeasible in our case, thus we're choosing bean adapter. More than that we have to create a
generic solution for int to boolean property type
adapter. With
this target in mind we may create a function receiving bean and a property name and
returning other bean with a single propery of boolean type:
<h:selectBooleanCheckbox id="selected"
value="#{ex:toBoolean(customer, 'selected').value}" />
But thinking further the question appears: whether we can pass ValueExpression by reference into a bean adapter function, and have something like this:
<h:selectBooleanCheckbox id="selected"
value="#{ex:toBoolean(byref customer.selected).value}" />
It turns out that it's possible to do this kind of thing. Unfortunately it requires custom facelets tag, like this:
<ex:ref var="selected"
value="#{customer.selected}"/>
<h:selectBooleanCheckbox id="selected"
value="#{ex:toBoolean(selected).value}" />
Implementation of such a tag is really primitive (in fact it mimics c:set tag
handler except one line), but still it's an extension on the level we don't
happy to introduce.
This way we were going circles considering pros and cons, regretting that el
references ain't native in jsf/facelets and weren't able to classify whether our
solution is a hack or a neat extension...
P.S. We know that JSF 2.0 provides solution for h:selectBooleanCheckbox but still there are cases when similar technique is required
even there.
We always tacitly assumed that protected modifier in java
permits member access from a class the member belongs to, or from an instance of
class's descendant. Very like the C++ defines it, in fact.
In other words no external client of an instance can directly access a protected member of that instance or class the instance belongs to.
It would be very interesting to know how many people live
with such a naivete, really!
Well, that's what java states:
The protected modifier specifies that the member can only be accessed within its own package (as with package-private) and, in addition, by a subclass of its class in another package.
If one'll think, just a little, she'll see that this gorgeous definition
is so different from C++'s and so meaningless that they would better dropped
this modifier altogether.
The hole is so huge that I can easily build an example
showing how to modify protected member of some other class in a perfectly valid
way. Consider:
MyClass.java
package com.mypackage;
import javax.faces.component.Hack;
import javax.faces.component.UIComponentBase;
import javax.faces.event.FacesListener;
public class MyClass
{
public void addFacesListener(
UIComponentBase component,
FacesListener listener)
{
Hack.addFacesListener(component, listener);
}
...
}
Hack.java
package javax.faces.component;
import javax.faces.event.FacesListener;
public class Hack
{
public static void addFacesListener(
UIComponentBase component,
FacesListener listener)
{
component.addFacesListener(listener);
}
}
An example is about to how one adds custom listener to an arbitrary jsf component. Notice that this is not
assumed by design, as a method addFacesListener() is protected. But see how easy one can hack this dummy "protected" notion.
Update: for a proper implementation of protected please read Manifest file, a part about package sealing.
Just in case, if you don't know what JSON stands for - it's JavaScript Object Notation.
You may find a plenty of JSON implementations in java, so we shall add one more idea. Briefly, it's about to plug it into xml serialization infrastructure JAXB. Taking into account that JAXB now is an integral part of java platform itself, benefits are that you can transparently use the same beans for xml and JSON serialization.
What you need to do is only to provide JSON reader and writer under the hood of XMLStreamReader and XMLStreamWriter interfaces.
In spare time we shall implement this idea.
If you by chance see lines like the following in your code:
private transient final Type field;
then know, you're in the trouble!
The reason is simple, really (provided you're sane and don't put field modifiers without reason). transient assumes that your class is serializable, and you have a particular field that you don't want to serialize. final states that the field is initialized in the constructor, and does not change the value for the rest life cycle.
This way if you will serialize an instance of class with such a field, and then deserialize it back, you will have the field initialized with null, and no way to have another value there.
P.S. That's what we have found in our code recently:
private transient final Lock sync = new ReentrantLock();
Generics in C# look inferior to templates (especially to concepts) in C++,
however now and then you can build a wonderful pieces the way a C++ profi would
envy.
Consider a generic converter method: T Convert<T>(object value).
In C++ I would create several template specializations for all supported
conversions. Well, to make things harder, think of converter provider supporting
conversion:
public interface IConverterProvider
{
Converter<object, T> Get<T>();
}
That begins to be a puzzle in C++, but C# handles it easily!
My first C#'s implementation was too naive, and spent too many cycles in
provider, resolving which converter to use. So, I went on, and have created a
sofisticated implementation like this:
private IConverterProvider provider = ...
public T Convert<T>(object value)
{
var converter = provider.Get<T>();
return converter(value);
}
...
public class ConverterProvider: IConverterProvider
{
public Converter<object, T> Get<T>()
{
return Impl<T>.converter;
}
private static class Impl<T>
{
static Impl()
{
// Heavy implementation initializing converters.
converter = ...
}
public static readonly Converter<object, T> converter;
}
}
Go, and do something close in C++!
If you have a string variable $value as xs:string, and want to know whether it starts from a digit, then what's the best way to do it in the xpath?
Our answer is: ($value ge '0') and ($value lt ':').
Looks a little funny (and disturbing).
In our project we're generating a lot of xml files, which are subjects of manual
changes, and repeated generations (often with slightly different generation
options). This way a life flow of such an xml can be described as following:
- generate original xml (version 1)
- manual changes (version 2)
- next generation (version 3)
- manual changes integrated into the new generation (version 4)
If it were a regular text files we could use diff utility to prepare
patch between versions 1 and 2, and apply it with patch utility to
a version 3. Unfortunately xml has additional semantics compared to a plain text. What's an
invariant or a simple modification in xml is often a drastic change in text.
diff/patch does not work well for us. We need xml diff
and patch.
The first guess is to google it! Not so simple.
We have failed to find a tool or an API that can be used from ant. There are a
lot of GUIs to show xml differences and to perform manual merge, or doing
similar but different things to what we need
(like MS's xmldiffpatch).
Please point us to such a program!
Meantime, we need to proceed. We don't believe that such a tool can be
done on the knees, as it's a heuristical and mathematical at the same time
task requiring a careful design and good statistics for the use cases. Our idea
is to exploit
diff/patch. To achieve the goals we're going to
perform some normalization of xmls before diff to remove redundant
invariants, and normalization after the patch to return it into a readable form.
This includes:
- ordering attributes by their names;
- replacing unsignificant whitespaces with line breaks;
- entering line breaks after element names and before attributes, after
attribute name and before it's value, and after an attribute value.
This way we expect to recieve files reacting to modifications similarly to text
files.
Sunny> Look what have I found! Consider a C#:
public class T
{
public T free;
}
public void NewTest()
{
T cache = new T();
Stopwatch timer = new Stopwatch();
timer.Reset();
timer.Start();
for(int i = 0; i < 10000000; ++i)
{
// Get from cache.
T t;
if (cache.free == null)
{
cache.free = new T();
}
t = cache.free;
// Release
cache.free = t;
t = null;
}
timer.Stop();
long cacheTicks = timer.ElapsedTicks;
timer.Reset();
timer.Start();
for(int i = 0; i < 10000000; ++i)
{
new T();
}
timer.Stop();
long newTicks = timer.ElapsedTicks;
Console.WriteLine("cache: {0}, new: {1}", cacheTicks, newTicks);
}
Gloomy> And?
Sunny> Tests show that new T() is almost as fast as
caching! GC's "new" probably has a fast route, where it shifts free memory border
in an atomic way, thus allocation takes just several cycles.
Gloomy> Well, you're probably right, there is a fast route. I, however,
have a different opinion. To track references, a generational garbage collector
implements field assign as a call rather than a mov.
This routine, except move itself, marks touched memory page in a special card
table (who said GC is cheap?); thus, I think, a reference field setter is
almost as slow as the "new" call.
.Net is known for its array covariance. That means that any array can be cast to
an array of base elements:
public class T: B
{
}
T[] tlist = ...
B[] blist = tlist;
This feature comes at cost:
B b = ...
T t = ...
blist[0] = b; // This efficiently is: blist[0] = (T)b;
tlist[0] = t; // This is the same: tlist[0] = (T)t;
We pay the cost of additional cast, just for nothing. Let this dubious design decision opresses .Net/Java inventors.
You can eliminate the cast. Just use array of structs:
struct S<T>
{
public T t;
}
S<T>[] slist = ...
slist[0].t = t; // Works without cast.
Measurment show that S[] is ~35% faster than T[] on write, and slower (JIT could do better) on read.
Well, ugly workaround of ugly design.
P.S. In java there is no relief...
There is a method Right() in the RB tree implementation:
public int Right(int node)
{
return items[node].right;
}
JIT does not want to inline it, probably as the method may throw:
public int Right(int node)
{
return items[node].right;
00000000 mov eax,dword ptr [ecx+4]
00000003 cmp edx,dword ptr [eax+4]
00000006 jae 00000013
00000008 shl edx,4
0000000b lea eax,[eax+edx+8]
0000000f mov eax,dword ptr [eax+8]
00000012 ret
00000013 call 74C3A62C
00000018 int 3
Too sad.
Early in 2001 we've read that .NET's JIT is smart enough to optimize repeated
boundary checks.
In the year 2009 we still can verify that this is not the case (no matter how
hard you try).
C#:
private int CharAt(int offset)
{
string text = this.text;
return (uint)offset >= (uint)text.Length ? -1 : text[offset];
}
Disassembly:
private int CharAt(int offset)
{
string text = this.text;
00000000 push ebp
00000001 mov ebp,esp
00000003 mov ecx,dword ptr [ecx+30h]
return (uint)offset >= (uint)text.Length ? -1 : text[offset];
00000006 cmp dword ptr [ecx+8],edx
00000009 jbe 00000017
0000000b cmp edx,dword ptr [ecx+8]
0000000e jae 0000001C
00000010 movzx eax,word ptr [ecx+edx*2+0Ch]
00000015 pop ebp
00000016 ret
00000017 or eax,0FFFFFFFFh
0000001a pop ebp
0000001b ret
0000001c call 74C24C6C
00000021 int 3
P.S. Neither this method is inlined (IL length is 25 bytes).
Yesterday, I've installed IE8.
Looks better here and there.
Today, I'm shocked!
I've reopened my web mail and it remembered the session. It keeps session cookies after closing IE8 instance!
I did not believe to myself and logged into an another web application, and then opened another IE8 instance. What do you think? - It shares the session between instances!
That is a serious security problem.
It prevents me from opening two sessions of a web application on my computer.
P.S. we have found that this problem was already discussed. See IE8 handles sessions/cookies different than IE7 - big trouble for - ...
Someone needs a brain surgery...
Quick solution: run IE8 with -nomerge command line option.
We'd like to return to the binary tree algorithms and spell what you cannot
do with generics in C#. Well, you can do many things, however with generalization
penalty.
Consider a binary tree node: Node(Parent, Left, Right). RB, AVL, and
others algorithms attach some private information to this node to perform
balancing.
You can express this idea methematically (and in C++), you cannot implement it efficiently in C#.
More focused example. Consider RB tree: Node(Parent, Left, Right, Color).
There are a number of ways you may implement the internal structure of the tree.
Algorithms themselves stay the same.
Straightforward implementation:
class Node
{
Node Parent;
Node Left;
Node Right;
bool Color;
}
This implementation allocates nodes in the heap and each node refers to other
nodes.
Node navigator implementation:
class Node
{
Node Left;
Node Right;
bool Color;
}
struct NodeNavigator
{
Node[] nodes;
int index;
}
Node does not refer to the parent. This reduces the memory consumption and
simplifies object graph, which is good for GC. Tree is walked using a node
navigator, which stores ancestors of the node.
Node as a structure:
struct Node
{
int Parent;
int Left;
int Right;
bool Color; // This might be integrated as highest bit of parent.
}
Tree is stored as an array of nodes. This is compact and GC efficient
implementation.
Node as a structure, and with node navigator:
struct Node
{
int Left;
int Right;
bool Color; // This might be integrated as highest bit of left.
}
struct NodeNavigator
{
Tree tree;
int[] nodes;
int index;
}
Tree is stored as an array of nodes, and a navigator is used to walk it. This is the most compact implementation.
Each implementation has its virtues. The common between implementations is that
they share the same balancing and navigation algorithms. Storage
differences prevent a single C# implementation. To the contrast, C++ allows to
define a concept "tree" and to define specializations of this concept, allowing
a unified algorithms; all this is done without performance penalty.
P.S. java in this regard, is almost alternativeless...
Do you agree that binary trees and algorithms that keep trees reasonably balanced
are important?
Our answer is yes!
It's interesting enough, however, that you won't easily find these algorithms
publicly available.
Though red-black,
AVL and other algorithms
described in the wikipedia are defined in terms of tree manipulation, all
implementations we have seen, deal with trees annotated with keys and values.
These implementations really use tree balancing algorithms behind the schene,
and expose a commonplace set or map containers to a client. Even
C++ Standard
Library suffers from this disease.
We think that binary trees are valuable independent concepts, and they worth to
be implemented separately, at least because there are other algorithms, except
sets and maps, using trees.
And well, we did it in C#! See
RedBlackTree.cs.
Consider an example - a simple scheduler,
ScheduleBookmark.cs, with operations:
- schedule an action;
- remove an action from the schedule;
- enumerate actions;
- find a date, an action is scheduled for;
- find an action (or at least closest one) for a specified date;
- postpone actions due to delays;
A balanced binary tree allows efficient implementation of such a scheduler. Tree
node stores an action, and a time span between parent node and this node.
This way:
| Operation |
Steps |
| schedule an action |
find place + link node + rebalance tree |
| remove an action from the schedule |
unlink node + rebalance tree |
| enumerate actions |
navigate tree |
| find a date, an action is scheduled for |
find node in tree |
| find an action for a specified date |
cumulate time spans up to the tree root |
| postpone actions due to delays |
fixup time spans from a node up to the tree root |
Compare operation complexities between tree, array, list and map:
| Operation |
Tree |
Array |
List |
Map |
| schedule an action |
O(ln(N)) |
O(N) |
O(N) |
O(ln(N)) |
| remove an action from the schedule |
O(ln(N)) |
O(N) |
O(1) |
O(ln(N)) |
| enumerate actions |
O(ln(N)) |
O(1) |
O(1) |
O(ln(N)) |
| find a date, an action is scheduled for |
O(ln(N)) |
O(1) |
O(1) |
O(1) |
| find an action for a specified date |
O(ln(N)) |
O(ln(N)) |
O(N) |
O(ln(N)) |
| postpone actions due to delays |
O(ln(N)) |
O(N) |
O(N) |
O(N*ln(N)) |
Complexity of each operation for the tree is O(ln(N)). No arrays, lists, or maps achieve similar worst case guaranty.
Finally, the test program is
Program.cs,
and a whole project (VS2008) is
Tree.zip
Could you think of a C# method accepting an ancestor, and
forbidding a descendant of a class at compile time?
The answer to this probably is: why do you need such a reptile.
Well, I don't. I didn't meant to create such a method, but generics help a lot!
public class BinaryTreeNode<Node>
where Node: BinaryTreeNode<Node>
{
public Node parent;
public Node left;
public Node right;
}
public class MyNode: BinaryTreeNode<MyNode>
{
public int key;
}
public class MyRoot: MyNode
{
}
public class Test
{
public void test()
{
MyRoot root = new MyRoot();
// print((MyNode)root); // This works.
print(root); // This does not work.
}
private static void print<T>(T node)
where T: BinaryTreeNode<T>
{
Console.WriteLine("print me");
}
}
By the way, BinaryTreeNode is an "abstract" class, as you cannot instantiate it but inherit only.
Once upon a time, we created a function mimicking
decapitalize() method defined in java in java.beans.Introspector. Nothing
special, indeed. See the source:
/**
* Utility method to take a string and convert it to normal Java variable
* name capitalization. This normally means converting the first
* character from upper case to lower case, but in the (unusual) special
* case when there is more than one character and both the first and
* second characters are upper case, we leave it alone.
* <p>
* Thus "FooBah" becomes "fooBah" and "X" becomes "x", but "URL" stays
* as "URL".
*
* @param name The string to be decapitalized.
* @return The decapitalized version of the string.
*/
public static String decapitalize(String name) {
if (name == null || name.length() == 0) {
return name;
}
if (name.length() > 1 && Character.isUpperCase(name.charAt(1)) &&
Character.isUpperCase(name.charAt(0))){
return name;
}
char chars[] = name.toCharArray();
chars[0] = Character.toLowerCase(chars[0]);
return new String(chars);
}
We typed implementation immediately:
<xsl:function name="t:decapitalize" as="xs:string">
<xsl:param name="value" as="xs:string?"/>
<xsl:variable name="c" as="xs:string"
select="substring($value, 2, 1)"/>
<xsl:sequence select="
if ($c = upper-case($c)) then
$value
else
concat
(
lower-case(substring($value, 1, 1)),
substring($value, 2)
)"/>
</xsl:function>
It worked, alright, until recently, when it has fallen to work, as the output was
different from java's counterpart.
The input was W9Identifier. Function naturally returned the same value, while
java returned w9Identifier. We has fallen with the assumption that
$c = upper-case($c) returns true when character is an upper case letter. That's
not correct for numbers. Correct way is:
<xsl:function name="t:decapitalize" as="xs:string">
<xsl:param name="value" as="xs:string?"/>
<xsl:variable name="c" as="xs:string"
select="substring($value, 2, 1)"/>
<xsl:sequence select="
if ($c != lower-case($c)) then
$value
else
concat
(
lower-case(substring($value, 1, 1)),
substring($value, 2)
)"/>
</xsl:function>
Although in last our projects we're using more Java and XSLT, we always compare Java and .NET features. It's not a secret that in most applications we may find cache solutions used to improve performance. Unlike .NET providing a robust cache solution Java doesn't provide anything standard. Of course Java's adept may find a lot of caching frameworks or just to say: "use HashMap (ArrayList etc.) instead", but this is not the same.
Think about options for Java:
1. Caching frameworks (caching systems). Yes, they do their work. Do it perfectly. Some of them are brought to the state of the art, but there are drawbacks. The crucial one is that for simple data caching one should use a whole framework. This option requires too many efforts to solve a simple problem.
2. Collection classes (HashMap, ArrayList etc.) for caching data. This is very straightforward solution, and very productive. Everyone knows these classes, nothing to configure. One should declare an instance of such class, take care of data access synchronization and everything starts working immediately. An admirable caching solution but for "toy applications", since it solves one problem and introduces another one. If an application works for hours and there are a lot of data
to cache, the amount of data grows only and never reduces, so this is the reason why such caching is very quickly surrounded with all sort of rules that somehow reduce its size at run-time. The solution very quickly lost its shine and become not portable, but it's still applicable for some applications.
3. Using Java reference objects for caching data. The most appropriate for cache solution is a java.util.WeekHashMap class. WeakHashMap works exactly like a hash table but uses weak references internally. In practice, entries in the WeakHashMap are reclaimed at any time if they are not refered outside of map. This caching strategy
depends on GC's whims and is not entirely reliable, may increase a number of cache misses.
We've decided to create our simple cache with sliding expiration of data.
One may create many cache instances but there is only one global service that tracks expired objects among these instances:
private Cache<String, Object> cache = new Cache<String, Object>();
There is a constructor that specifies an expiration interval in milliseconds for all cached objects:
private Cache<String, Object> cache = new Cache<String, Object>(15 * 60 * 1000)
Access is similar to HashMap:
instance = cache.get("key"); and cache.put("key", instance);
That's all one should know to start use it. Click here to download the Java source of this class. Feel free to use it in your applications.
Yesterday I've read of a new Garbage Collection implementation
G1.
To be honest I was not impressed.
I think Garbage Collection is an evil, or at least its present implementations.
I do not believe in algorithms that in their very core assume a centralized
execution.
On the other hand it's clear it's not in my power to change the status quo. My
lot is to give advices mostly incompetent and ignorable.
I'm waiting for the time when someone will reach the idea to bring some parts of
GC logic out of runtime scope. This will require more VM intelligence,
however will bear its fruits.
JIT or compiler during a static analysis may prove that some objects being
collected may make some of their referring objects unreachable, provided it can
prove that referring objects are not reachable through the other means (e.g.
private field which is not stored in other places). This is close to the ideas
expressed in
Muse on value types in java. It's possible to prepare a garbage graph in
advance before runtime.
In many cases it's also possible to prove that when method's variable goes out
of scope it's not reachable through the other means and may be collected. This
allows to implement a stage of automatic garbage collection when objects that
are proven to be a garbage be immedeately added to a free memory set.
As an example I'm thinking of java's ArrayList object which stores private
array. When ArrayList is reclaimed or resized a reference to the private array
is getting lost and memory can be added to the free set immediately.
This mechanics being integrated as the first stage of GC will make it less
centralized, as I believe many objects will be collected this way.
Suppose you have constructed a sequence of attributes.
How do you access a value of attribute "a"?
Simple, isn't it? It has taken a couple of minutes to find a solution!
<xsl:variable name="attributes" as="attribute()*">
<xsl:apply-templates mode="t:generate-attributes" select="."/>
</xsl:variable>
<xsl:variable name="value" as="xs:string?"
select="$attributes[self::attribute(a)]"/>
Saying
Our project, containing many different xslt files, generates many different
outputs (e.g: code that uses DB2 SQL, or Oracle SQL, or DAO, or some
other flavor of code). This results in usage of
indirect calls to handle different generation options, however to allow xslt
to work we had to create a big main xslt including stylesheets for each kind of
generation. This impacts on a compilation time.
Alternatives
- A big main xslt including everything.
- A big main xslt including everything and using "use-when" attribute.
- Compose main xslt on the fly.
We were eagerly inclined to the second alternative. Unfortunately a limited set of information is available when "use-when" is evaluated. In
particular there are neither parameters nor documents available. Using
Saxon's extensions one may reach only static variables, or access
System.getProperty(). This isn't flexible.
We've decided to try the third alternative.
Solution
We think we have found a nice solution: to create XsltSource,
which receives a list of includes upon construction, and creates an xslt
when getReader() is called.
import java.io.Reader;
import java.io.StringReader;
import javax.xml.transform.stream.StreamSource;
/**
* A source to read generated stylesheet, which includes other stylesheets.
*/
public class XsltSource extends StreamSource
{
/**
* Creates an {@link XsltSource} instance.
*/
public XsltSource()
{
}
/**
* Creates an {@link XsltSource} instance.
* @param systemId a system identifier for root xslt.
*/
public XsltSource(String systemId)
{
super(systemId);
}
/**
* Creates an {@link XsltSource} instance.
* @param systemId a system identifier for root xslt.
* @param includes a list of includes.
*/
public XsltSource(String systemId, String[] includes)
{
super(systemId);
this.includes = includes;
}
/**
* Gets stylesheet version.
* @return a stylesheet version.
*/
public String getVersion()
{
return version;
}
/**
* Sets a stylesheet version.
* @param value a stylesheet version.
*/
public void setVersion(String value)
{
version = value;
}
/**
* Gets a list of includes.
* @return a list of includes.
*/
public String[] getIncludes()
{
return includes;
}
/**
* Sets a list of includes.
* @param value a list of includes.
*/
public void setIncludes(String[] value)
{
includes = value;
}
/**
* Generates an xslt on the fly.
*/
public Reader getReader()
{
String[] includes = getIncludes();
if (includes == null)
{
return super.getReader();
}
String version = getVersion();
if (version == null)
{
version = "2.0";
}
StringBuilder builder = new StringBuilder(1024);
builder.append("<stylesheet version=\"");
builder.append(version);
builder.append("\" xmlns=\"http://www.w3.org/1999/XSL/Transform\">");
for(String include: includes)
{
builder.append("<include href=\"");
builder.append(include);
builder.append("\"/>");
}
builder.append("</stylesheet>");
return new StringReader(builder.toString());
}
/**
* An xslt version. By default 2.0 is used.
*/
private String version;
/**
* A list of includes.
*/
private String[] includes;
}
To use it one just needs to write:
Source source = new XsltSource(base, stylesheets);
Templates templates = transformerFactory.newTemplates(source);
...
where:
base is a base uri for the generated stylesheet; it's used to
resolve relative includes;stylesheets is an array of hrefs.
Such implementation resembles a dynamic linking when separate parts are bound at
runtime. We would like to see dynamic modules in the next version of xslt.
We strongly object against persistence frameworks in their contemporary meaning.
This includes a long row of names like Hibernate, Java Persistence API, LINQ,
and others.
Consider how one of them describes itself:
...high performance object/relational persistence and query service... lets you
develop persistent classes following object-oriented idiom - including
association, inheritance, polymorphism, composition, and collections... allows you to express queries in its own portable SQL extension...
Sounds good, right?
We think not! Words "own" and "portable" regarding SQL are heard
almost like antonyms. When one creates a unified language (a noble rush, opposed to a
proprietary one (?)) she will inevitably adds a peer, increasing
plurality in the family of languages.
Attempts to create similar layers between data and business logic are not new.
This happens throughout the computer history. IDMS, NATURAL, COOL:GEN these are
20-30 years old examples.
Our reasoning (nothing new).
One need to approach to a design (development and maintainance) from different
perspectives, thus she will understand the question under the design better, and
will estimate skills to accomplish the problem. This will lead to a
modularization e.g: business layer, data layer, appearance; and to development
(maintainance) roles: program developer, database specialist, appearance
speciaist. On a small scale several roles are often fulfilled with one person;
this should not mean, however, that these roles are redundant, one just need to
try on different roles.
Why does one separate business layer and data layer?
Pragmatic perspective. There are databases, which may accomplish most of data
storage tasks in a more efficient way than one may achieve without database.
There are two worlds of database specialists and program developers. These two
layers and roles are facts of reality.
A desiner's goal is to keep these roles separate:
- do not force a database specialist to know the business logic details;
- do not force a program developer to know details on how to organize a storage
in more efficient way, or on how to optimize a particular query;
Modularity helps here. Databases are well equipped to solve these tasks: the data
layer should expose a database API through stored procedures, functions, and
views, while the business layer should use this API to access the database.
With persistence frameworks there are two alterantives:
- still use data layer API;
- rely on a persistence framework.
When the first case is selected then a framework provides almost no aditional
value comparing to traditional database access (jdbc, ado.net, an so on).
When one relies on a framework then a data layer interface virtually disappears
(in fact a framework substitutes this interface). Database specialist has very
little control over tuning the data structure, and optimizing queries, unless
she starts digging in the business code but even then she always cannot control
queries to the database. Moreover database specialist must learn a proprietary
query language.
Result is that a persistence framework erodes a division of responsibilities,
complicating development and maintainance.
We often hear a following explanation on why one should use Persistence
Frameworks: "It eases database vendor switch". This is the most stupid reason to use
Persistence Frameworks! It looks as if they plan to switch vendors once a
day.
A design needs to focus on a modularity. This will make code more robust, faster
and maintainable. This also eases potential migration process, as the data layer
should be migrated only, with minimal (mostly configurational) changes in the
business layer.
We are certain xslt/xquery are the best for web application frameworks from the
design perspective; or, in other words, pipeline frameworks allowing use of
xslt/xquery are preferable way to create web applications.
Advantages are obvious:
-
clear separation of business logic, data, and presentation;
-
richness of languages, allowing to implement simple presentation, complex
components, and sophisticated data binding;
-
built-in extensibility, allowing comunication with business logic, written in
other languages and/or located at different site.
It seems the agitation for a such technologies is like to force an open
door. There are such frameworks out there:
Orbeon Forms, Cocoon, and others.
We're not qualified to judge of their virtues, however...
Look at the current state of affairs. The main players in this area (well, I
have a rather limited vision) push other technologies: JSP/JSF/Faceletes and
alike in the Java world, and ASP.NET in the .NET world. The closest thing they
are providing is xslt servlet/component allowing to generate an output.
Their variants of syntaxis, their data binding techniques allude to similar
paradigms in xslt/xquery:
<select>
<c:forEach var="option" items="#{bean.options}">
<option value="#{option.key}">#{parameter.value}</option>
</c:forEach>
</select>
On the surface, however, we see much more limited (in design and in the
application) frameworks.
And here is a contradiction: how can it be that at present such a good design is
not as popular, as its competitors, at least?
Someone can say, there is no such a problem. You can use whatever you want. You
have a choice! Well, he's lucky. From our perspective it's not that simple.
We're creating rather complex web applications. Their nature isn't important in
this context, but what is important is that there are customers. They are not
thoroughly enlightened in the question, and exactly because of this they prefer
technologies proposed by leaders. It seems, everything convince them: main
stream, good support, many developers who know technology.
There is no single chance to promote anything else.
We believe that the future may change this state, but we're creating at present,
and cannot wait...
Java has no value types: objects allocated inplace, in contrast to objects
referred by a pointer in the heap. This, in my opinion, has a negative impact on
a program design and on a performance.
Incidentally, I've thought of a use case, which can be understood as a value
type by the jvm implementations. Consider an example:
class A
{
private final B b = new B();
}
Implementation may layout class A, in a way that field b will be a content of
an instance of class B itself rather than a pointer to an instance of a class B. This way we
save a pointer and a heap allocation of instance B. Another example:
class C
{
C(int size)
{
values = new D[size];
for(int i = 0; i < values.length; i++)
{
values[i] = new D();
}
}
private final D[] values;
}
Here field values is never a null and each item of array contains a non null
value. Assuming these conditions are kept for a whole life cycle, and values are
not passed by reference, we can consider values as an array of value types.
A use case conditions are following:
- a field contains a non null value;
- the field value is an instance of the field type and not
descendant type;
- if the field is an array, then all elements of the array are
initialized with instances of element type, and not descendant type.
- the field or an element of the array can be assigned through the
operator
new only (field = new T(), array[i] = new T());
- the array field is not passed by reference
(
Arrays.sort(array) never happens).
JIT's allowed to interpret a field as a
value type provided it proves these conditions.
Later...
There is another use case to detect value types:
- a method variable contains no null value, and
- that variable is never stored in any field, and
- no synchronization is used on the instance of value in variable, and
- a value to the variable is assigned through the operator
new only.
A variable can be layed out directly onto the stack, provided a preceding conditions are satisfied.
P.S. In spite that .NET has built in value types, it may use the very same technique to optimize reference types.
Yesterday, incidentally, I've arrived to a problem of a dynamic error during evaluation of a template's match.
This reminded me
SFINAE in C++. There the principle is applied at compile time to find a
matching template.
I think people underestimate the meaning of this behaviour. The effect of
dynamic errors occurring during pattern evaluation is described in the
specification:
Any dynamic error or type error that occurs during the evaluation of a pattern against a particular node is treated as a recoverable error even if the error would not be recoverable under other circumstances. The optional recovery action is to treat the pattern as not matching that node.
This has far reaching consequences, like an error recovery. To illustrate what I'm talking about please look at this simple stylesheet that recovers from "Division by zero.":
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<xsl:variable name="operator" as="element()+">
<div divident="10" divisor="0"/>
<div divident="10" divisor="2"/>
</xsl:variable>
<xsl:apply-templates select="$operator"/>
</xsl:template>
<xsl:param name="NaN" as="xs:double" select="1.0 div 0"/>
<xsl:template
match="div[(xs:integer(@divident) div xs:integer(@divisor)) ne $NaN]">
<xsl:message select="xs:integer(@divident) div xs:integer(@divisor)"/>
</xsl:template>
<xsl:template match="div">
<xsl:message select="'Division by zero.'"/>
</xsl:template>
</xsl:stylesheet>
Here, if there is a division by zero a template is not matched and other
template is selected, thus second template serves as an error handler for the
first one. Definitely, one may define much more complex construction to be
handled this way.
I never was a purist (meaning doing everything in xslt), however this example
along with
indirect function call, shows that xslt is rather equiped language. One just
need to be smart enough to understand how to do a things.
See also: Try/catch block in xslt 2.0 for Saxon 9.
Among other job activities, we're from time to time asked to check technical skills of job applicants.
Several times we were interviewing people who're far below the
acceptable professional skills. It's a torment for both sides, I should say.
To ease things we have designed a small
questionnaire (specific to our projects) for job applicants. It's sent to an applicant before the
meeting. Even partially answered, this
questionnaire constitutes a good filter against profanes:
<questionnaire>
<item>
<question>
Please estimate your knowledge in XML Schema
(xsd) as lacking, bad, good, or perfect.
</question>
<answer/>
</item>
<item>
<question>
Please estimate your
knowledge in xslt 2.0/xquery 1.0 as lacking, bad, good, or perfect.
</question>
<answer/>
</item>
<item>
<question>
Please estimate your
knowledge in xslt 1.0 as lacking, bad, good, or perfect.
</question>
<answer/>
</item>
<item>
<question>
Please estimate your
knowledge in java as lacking, bad, good, or perfect.
</question>
<answer/>
</item>
<item>
<question>
Please estimate your
knowledge in c# as lacking, bad, good, or perfect.
</question>
<answer/>
</item>
<item>
<question>
Please estimate your
knowledge in sql as lacking, bad, good, or perfect.
</question>
<answer/>
</item>
<item>
<question>
For logical values A, B,
please rewrite logical expression "A and B" using operator "or".
</question>
<answer/>
</item>
<item>
<question>
For logical values A, B,
please rewrite logical expression "A = B" using operators "and" and "or".
</question>
<answer/>
</item>
<item>
<question>
There are eight balls, with
only one heavier than some other.
What is a minimum number of weighings reveals the
heavier ball?
Please be suspicious about the "trivial" solution.
</question>
<answer/>
</item>
<item>
<question>
If A results in B. What one
may say about the reason of B?
</question>
<answer/>
</item>
<item>
<question>
If only A or B result in C.
What one may say about the reason of C?
</question>
<answer/>
</item>
<item>
<question>
Please define an xml schema
for this questionnaire.
</question>
<answer/>
</item>
<item>
<question>
Please create a simple
stylesheet creating an html table based on this questionnaire.
</question>
<answer/>
</item>
<item>
<question>
For a table A with columns
B, C, and D, please create an sql query selecting B groupped by C and ordered by
D.
</question>
<answer/>
</item>
<item>
<question>
For a sequence of xml
elements A with attribute B, please write a stylesheet excerpt creating a
sequence of elements D, grouping elements A with the same string value of
attribute B, sorted in the order of ascending of B.
</question>
<answer/>
</item>
<item>
<question>
Having a java class A with
properties B and C, please sort a collection of A for B in ascending, and C in
descending order.
</question>
<answer/>
</item>
<item>
<question>
What does a following line
mean in c#?
int? x;
</question>
<answer/>
</item>
<item>
<question>
What is a parser?
</question>
<answer/>
</item>
<item>
<question>
How to issue an error in the
xml stylesheet?
</question>
<answer/>
</item>
<item>
<question>
What is a lazy evaluation?
</question>
<answer/>
</item>
<item>
<question>
How do you understand a
following sentence?
For each line of code there should be a comment.
</question>
<answer/>
</item>
<item>
<question>
Have you used any
supplemental information to answer these questions?
</question>
<answer/>
</item>
<item>
<question>
Have you independently
answered these questions?
</question>
<answer/>
</item>
</questionnaire>
We are designing a rather complex xslt 2.0 application, dealing with semistructured
data. We must tolerate with errors during processing, as there are cases where an
input is not perfectly valid (or the program is not designed or ready to get
such an input).
The most typical error is unsatisfied expectation of tree structure like:
<xsl:variable name="element" as="element()" select="some-element"/>
Obviously, dynamic error occurs if a specified element is not present. To
concentrate on primary logic, and to avoid a burden of illegal (unexpected) case
recovery we have created a try/catch API. The goal of such API is:
- to be able to continue processing in case of error;
- report as much as possible useful information related to an error.
Alternatives:
Do not think this is our arrogance, which has turned us to create a custom API. No, we
were looking for alternatives! Please see
[xsl] saxon:try() discussion:
- saxon:try()
function - is a kind of pseudo function, which explicitly relies on lazy
evaluation of its arguments, and ... it's not available in SaxonB;
- ex:error-safe
extension instruction - is far from perfect in its implementation quality, and provides no error location.
We have no other way except to design this feature by ourselves. In our defence one
can say that we are using innovatory approach that encapsulates details of the
implementation behind template and calls handlers indirectly.
Use:
Try/catch API is designed as a template
<xsl:template name="t:try-block"/> calling a "try" handler, and, if
required, a "catch" hanler using
<xsl:apply-templates mode="t:call"/> instruction. Caller passes any
information to these handlers by the means of tunnel parameters.
Handlers must be in a "t:call" mode. The "catch" handler
may recieve following error info parameters:
<xsl:param name="error" as="xs:QName"/>
<xsl:param name="error-description" as="xs:string"/>
<xsl:param name="error-location" as="item()*"/>
where $error-location is a sequence of pairs (location as
xs:string, context as item())*.
A sample:
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:t="http://www.nesterovsky-bros.com/xslt/public/"
exclude-result-prefixes="xs t">
<xsl:include href="try-block.xslt"/>
<xsl:template match="/">
<result>
<xsl:for-each select="1 to 10">
<xsl:call-template name="t:try-block">
<xsl:with-param name="value" tunnel="yes"
select=". - 5"/>
<xsl:with-param name="try" as="element()">
<try/>
</xsl:with-param>
<xsl:with-param name="catch" as="element()">
<t:error-handler/>
</xsl:with-param>
</xsl:call-template>
</xsl:for-each>
</result>
</xsl:template>
<xsl:template mode="t:call" match="try">
<xsl:param
name="value" tunnel="yes" as="xs:decimal"/>
<value>
<xsl:sequence select="1 div
$value"/>
</value>
</xsl:template>
</xsl:stylesheet>
The sample prints values according to the formula "1/(i - 5)", where "i" is a
variable varying from 1 to 10. Clearly, division by zero occurs when "i" is equal
to 5.
Please notice how to access try/catch API through
<xsl:include href="try-block.xslt"/>. The main logic is
executed in
<xsl:template mode="t:call" match="try"/>, which
recieves parameters using tunneling. A default error handler
<t:error-handler/> is used to report errors.
Error report:
Error: FOAR0001
Description:
Decimal divide by zero
Location:
1. systemID: "file:///D:/style/try-block-test.xslt", line: 34
2. template mode="t:call"
match="element(try, xs:anyType)"
systemID: "file:///D:/style/try-block-test.xslt", line: 30
context node:
/*[1][local-name() = 'try']
3. template mode="t:call"
match="element({http://www.nesterovsky-bros.com/xslt/private/try-block}try, xs:anyType)"
systemID: "file:///D:/style/try-block.xslt", line: 53
context node:
/*[1][local-name() = 'try']
4. systemID: "file:///D:/style/try-block.xslt", line: 40
5. call-template name="t:try-block"
systemID: "file:///D:/style/try-block-test.xslt", line: 17
6. for-each
systemID: "file:///D:/style/try-block-test.xslt", line: 16
context item: 5
7. template mode="saxon:_defaultMode"
match="document-node()"
systemID: "file:///D:/style/try-block-test.xslt", line: 14
context node:
/
Implementation details:
You were not expecting this API to be pure xslt, weren't you?
Well, you're right, there is an extension function. Its pseudo code is like
this:
function tryBlock(tryItems, catchItems)
{
try
{
execute xsl:apply-templates for tryItems.
}
catch
{
execute xsl:apply-templates for catchItems.
}
}
The last thing. Please get the implementation
saxon.extensions.zip. There you will find sources of the try/catch, and
tuples/maps API.
Right now we're inhabiting in the java world, thus all our tasks are (in)directly
related to this environment.
We want to store stylesheets as resources of java application, and at
the same time to point to these stylesheets without jar qualification. In .NET this idea would not
appear at all, as there are well defined boundaries between assemblies, but java uses
rather different approach. Whenever you have a resource name, it's up to
ClassLoader to find this resource. To exploit this feature we've created
an uri resolver for the stylesheet
transformation. The protocol we use has a following format: "resource:/resource-path".
For example to store stylesheets in the
META-INF/stylesheets folder we use uri "resource:/META-INF/stylesheets/java/main.xslt".
Relative path is resolved naturally. A path "../jxom/java-serializer.xslt"
in previously mentioned stylesheet is resolved to "resource:/META-INF/stylesheets/jxom/java-serializer.xslt".
We've created a small class ResourceURIResolver. You need to
supply an instance of TransformerFactory with this resolver:
transformerFactory.setURIResolver(new ResourceURIResolver());
The class itself is so small that we qoute it here:
import java.io.InputStream;
import java.net.URI;
import java.net.URISyntaxException;
import javax.xml.transform.Source;
import javax.xml.transform.TransformerException;
import javax.xml.transform.URIResolver;
import javax.xml.transform.stream.StreamSource;
/**
* This class implements an interface that can be called by the processor
* to turn a URI used in document(), xsl:import, or xsl:include into a
* Source object.
*/
public class ResourceURIResolver implements URIResolver
{
/**
* Called by the processor when it encounters
* an xsl:include, xsl:import, or document() function.
*
* This resolver supports protocol "resource:".
* Format of uri is: "resource:/resource-path", where "resource-path" is
an
* argument of a {@link ClassLoader#getResourceAsStream(String)} call.
* @param href - an href attribute, which may be relative or absolute.
* @param base - a base URI against which the first argument will be
made
* absolute if the absolute URI is required.
* @return a Source object, or null if the href cannot be resolved, and
* the processor should try to resolve the URI itself.
*/
public Source resolve(String href, String base)
throws TransformerException
{
if (href == null)
{
return null;
}
URI uri;
try
{
if (base == null)
{
uri = new URI(href);
}
else
{
uri = new URI(base).resolve(href);
}
}
catch(URISyntaxException e)
{
// Unsupported uri.
return null;
}
if (!"resource".equals(uri.getScheme()))
{
return null;
}
String resourceName = uri.getPath();
if ((resourceName == null) || (resourceName.length() == 0))
{
return null;
}
if (resourceName.charAt(0) == '/')
{
resourceName = resourceName.substring(1);
}
ClassLoader classLoader =
Thread.currentThread().getContextClassLoader();
InputStream stream =
classLoader.getResourceAsStream(resourceName);
if (stream == null)
{
return null;
}
return new StreamSource(stream, uri.toString());
}
}
The project we're working on requires us to generate a java web application from a some ancient language. The code being converted, we have transformed into java classes
(thanks to
jxom),
the presentation is converted into JSF (facelets) pages.
By the way, long before java (.net) platform has been conceived, there were
languages and environments, worked out so good that contemporary client - server
paradigms (like JSF, ASP.NET, and so on) are just their isomorphisms.
The problem we were dealing with recently is JSF databinding for a bean properties
of types java.sql.Date, java.sql.Time, java.sql.Timestamp.
At some point of design we have decided that these types are most natural
representation of data in the original language, as the program's activity is
tightly connected to the database. Later on it's became clear that JSF
databinding does not like these types at all. We were to decide either to fall
back and use java.util.Date as bean property types, or do something with
databinding.
It was not clear what's the best way until we have found an elegant solution,
namely: to create ELResolver to handle bean properties of these types. The solution
works because custom el resolvers are applied before standard resolvers (except
implicit one).
The class
DateELResolver is rather simple extension of the
BeanELResolver. To use it you only need to register it the faces-config.xml:
<faces-config version="1.2"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-facesconfig_1_2.xsd">
<application>
<el-resolver>com.nesterovskyBros.jsf.DateELResolver</el-resolver>
</application>
</faces-config>
Does WebSphere MQ library for .NET support a connection pool? This is the question, which ask many .NET developers who deal with IBM WebSphere MQ and write multithread applications. The answer to this question unfortunately is NO… The .NET version supports only individual connection types.
I have compared two MQ libraries Java's and one for .NET, and I’ve found that most of the classes have the same declarations except one crucial for me difference. As opposed to .NET, the Java MQ library provides several classes implementing MQ connection pooling. There is nothing similar in .NET library.
There are few common workarounds for this annoying restriction. One of such workarounds (is recommended by IBM in their “MQ using .NET”) is to keep open one MQ connection per thread. Unfortunately such approach is not working for ASP.NET applications (including web services).
The good news is that starting from service pack 5 for MQ 5.3, and of course for MQ 6.xx they are supporting sharing MQ connections in blocked mode:
“The implementation of WebSphere MQ .NET ensures that, for a given connection (MQQueueManager object instance), all access to the target WebSphere MQ queue manager is synchronized. The default behavior is that a thread that wants to issue a call to a queue manager is blocked until all other calls in progress for that connection are complete.”
This allows creating an MQ connection (pay attention that MQQueueManager object is a wrapper for MQ connection) in one thread and exclusive use it in another thread without side-effects caused by multithreading.
Taking in account this feature, I’ve created a simple MQ connection pool. It’s ease in use. The main class MQPoolManager has only two static methods:
public static MQQueueManager Get(string QueueManagerName, string ChannelName, string ConnectionName);
and
public static void Release(ref MQQueueManager queueManager);
The method Get returns MQ queue manager (either existing from pool or newly created one), and Release returns it to the connection pool. Internally the logic of MQPoolManager tracks expired connections and do some finalizations, if need.
So, you may use one MQ connection pool per application domain without additional efforts and big changes in existing applications.
By the way, this approach has allowed us to optimize performance of MQ part considerably in one of ours projects.
Later on...
To clarify using of MQPoolManager I've decided to show here following code snippet:
MQQueueManager queueManager =
MQPoolManager.Get(QueueManagerName, ChannelName, ConnectionName);
try
{
// TODO: some work with MQ here
}
finally
{
MQPoolManager.Release(ref queueManager);
}
// at this point the queueManager is null
In the xslt world there is no widely used custom to think of stylesheet members
as of public and private in contrast to other programming languages like
C++/java/c# where access modifiers are essential. The reason is in complexity of
stylesheets: the less size of code - the easier to developer to keep all details
in memory. Whenever xslt program grows you should modularize
it to keep it manageable.
At the point where modules are introduced one starts thinking of public
interface of module and its implementation details. This separation is
especially important for the template matching as you won't probably want to
match private template just because you've forgotten about some template in
implementation of some module.
To make public or private member distinction you can introduce two namespaces in
your stylesheet, like:
For the private namespace you can use a unique name, e.g. stylesheet name as
part of uri.
The following example is based on
jxom. This stylesheet builds expression from expression tree. Public part
consists only of t:get-expression function, other members are private:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet
version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:t="http://www.nesterovsky-bros.com/public"
xmlns:p="http://www.nesterovsky-bros.com/private/expression.xslt"
xmlns="http://www.nesterovsky-bros.com/download/jxom.zip"
xpath-default-namespace="http://www.nesterovsky-bros.com/download/jxom.zip"
exclude-result-prefixes="xs t p">
<xsl:output method="text" indent="yes"/>
<!--
Entry point. -->
<xsl:template match="/">
<xsl:variable name="expression"
as="element()">
<lt>
<sub>
<mul>
<var name="b"/>
<var name="b"/>
</mul>
<mul>
<mul>
<int>4</int>
<var name="a"/>
</mul>
<var name="c"/>
</mul>
</sub>
<double>0</double>
</lt>
</xsl:variable>
<xsl:value-of
select="t:get-expression($expression)" separator=""/>
</xsl:template>
<!--
Gets
expression.
$element - expression element.
Returns expression tokens.
-->
<xsl:function name="t:get-expression" as="item()*">
<xsl:param name="element"
as="element()"/>
<xsl:apply-templates mode="p:expression" select="$element"/>
</xsl:function>
<!--
Gets binary expression.
$element - assignment expression.
$type - expression type.
Returns expression token sequence.
-->
<xsl:function
name="p:get-binary-expression" as="item()*">
<xsl:param name="element"
as="element()"/>
<xsl:param name="type" as="xs:string"/>
<xsl:sequence
select="t:get-expression($element/*[1])"/>
<xsl:sequence select="' '"/>
<xsl:sequence select="$type"/>
<xsl:sequence select="' '"/>
<xsl:sequence
select="t:get-expression($element/*[2])"/>
</xsl:function>
<!-- Mode
"expression". Empty match. -->
<xsl:template mode="p:expression"
match="@*|node()">
<xsl:sequence select="error(xs:QName('invalid-expression'),
name())"/>
</xsl:template>
<!-- Mode "expression". or. -->
<xsl:template
mode="p:expression" match="or">
<xsl:sequence select="p:get-binary-expression(.,
'||')"/>
</xsl:template>
<!-- Mode "expression". and. -->
<xsl:template
mode="p:expression" match="and">
<xsl:sequence
select="p:get-binary-expression(., '&&')"/>
</xsl:template>
<!-- Mode
"expression". eq. -->
<xsl:template mode="p:expression" match="eq">
<xsl:sequence select="p:get-binary-expression(., '==')"/>
</xsl:template>
<!--
Mode "expression". ne. -->
<xsl:template mode="p:expression" match="ne">
<xsl:sequence select="p:get-binary-expression(., '!=')"/>
</xsl:template>
<!--
Mode "expression". le. -->
<xsl:template mode="p:expression" match="le">
<xsl:sequence select="p:get-binary-expression(., '<=')"/>
</xsl:template>
<!--
Mode "expression". ge. -->
<xsl:template mode="p:expression" match="ge">
<xsl:sequence select="p:get-binary-expression(., '>=')"/>
</xsl:template>
<!--
Mode "expression". lt. -->
<xsl:template mode="p:expression" match="lt">
<xsl:sequence select="p:get-binary-expression(., '<')"/>
</xsl:template>
<!--
Mode "expression". gt. -->
<xsl:template mode="p:expression" match="gt">
<xsl:sequence select="p:get-binary-expression(., '>')"/>
</xsl:template>
<!--
Mode "expression". add. -->
<xsl:template mode="p:expression" match="add">
<xsl:sequence select="p:get-binary-expression(., '+')"/>
</xsl:template>
<!--
Mode "expression". sub. -->
<xsl:template mode="p:expression" match="sub">
<xsl:sequence select="p:get-binary-expression(., '-')"/>
</xsl:template>
<!--
Mode "expression". mul. -->
<xsl:template mode="p:expression" match="mul">
<xsl:sequence select="p:get-binary-expression(., '*')"/>
</xsl:template>
<!--
Mode "expression". div. -->
<xsl:template mode="p:expression" match="div">
<xsl:sequence select="p:get-binary-expression(., '/')"/>
</xsl:template>
<!--
Mode "expression". neg. -->
<xsl:template mode="p:expression" match="neg">
<xsl:sequence select="'-'"/>
<xsl:sequence select="t:get-expression(*[1])"/>
</xsl:template>
<!-- Mode "expression". not. -->
<xsl:template
mode="p:expression" match="not">
<xsl:sequence select="'!'"/>
<xsl:sequence
select="t:get-expression(*[1])"/>
</xsl:template>
<!-- Mode "expression".
parens. -->
<xsl:template mode="p:expression" match="parens">
<xsl:sequence
select="'('"/>
<xsl:sequence select="t:get-expression(*[1])"/>
<xsl:sequence
select="')'"/>
</xsl:template>
<!-- Mode "expression". var. -->
<xsl:template
mode="p:expression" match="var">
<xsl:sequence select="@name"/>
</xsl:template>
<!-- Mode "expression". int, short, byte, long, float, double. -->
<xsl:template
mode="p:expression"
match="int | short | byte | long | float | double">
<xsl:sequence select="."/>
</xsl:template>
</xsl:stylesheet>
Hello again!
To see first part about jxom please read.
I'm back with jxom (Java xml object model). I've finally managed to create an xslt that generates java code from jxom document.
Will you ask why it took as long as a week to produce it?
There are two answers:
1. My poor talents.
2. I've virtually created two implementations.
My first approach was to directly generate java text from xml. I was a truly believer that this is the way. I've screwed things up on that way, as when you're starting to deal with indentations, formatting and reformatting of text you're generating you will see things are not that simple. Well, it was a naive approach.
I could finish it, however at some point I've realized that its complexity is not composable from complexity of its parts, but increases more and more. This is not permissible for a such simple task. Approach is bad. Point.
An alternative I've devised is simple and in fact more natural than naive approach. This is a two stage generation:
a) generate sequence of tokens - serializer;
b) generate and then print a sequence of lines - streamer.
Tokens (item()*) are either control words (xs:QName), or literals (xs:string).
I've defined following control tokens:
| Token |
Description |
| t:indent |
indents following content. |
| t:unindent |
unindents following content. |
| t:line-indent |
resets indentation for one line. |
| t:new-line |
new line token. |
| t:terminator |
separates token sequences. |
| t:code |
marks line as code (default line type). |
| t:doc |
marks line as documentation comment. |
| t:begin-doc |
marks line as begin of documentation comment. |
| t:end-doc |
marks line as end of documentation comment. |
| t:comment |
marks line as comment. |
Thus an input for the streamer looks like:
<xsl:sequence select="'public'"/>
<xsl:sequence select="' '"/>
<xsl:sequence select="'class'"/>
<xsl:sequence select="' '"/>
<xsl:sequence select="'A'"/>
<xsl:sequence select="$t:new-line"/>
<xsl:sequence select="'{'"/>
<xsl:sequence select="$t:new-line"/>
<xsl:sequence select="$t:indent"/>
<xsl:sequence select="'public'"/>
<xsl:sequence select="' '"/>
<xsl:sequence select="'int'"/>
<xsl:sequence select="' '"/>
<xsl:sequence select="'a'"/>
<xsl:sequence select="';'"/>
<xsl:sequence select="$t:unindent"/>
<xsl:sequence select="$t:new-line"/>
<xsl:sequence select="'}'"/>
<xsl:sequence select="$t:new-line"/>
Streamer receives a sequence of tokens and transforms it in a sequence of lines.
One beautiful thing about tokens is that streamer can easily perform line breaks in order to keep page width, and another convenient thing is that code generating tokens should not track indentation level, as it just uses t:indent, t:unindent control tokens to increase and decrease current indentation.
The way the code is built allows mimic any code style. I've followed my favorite one. In future I'll probably add options controlling code style. In my todo list there still are several features I want to implement, such as line breaker to preserve page width, and type qualification optimizer (optional feature) to reduce unnecessary type qualifications.
Current implementation can be found at jxom.zip. It contains:
| File |
Description |
| java.xsd |
jxom xml schema. |
| java-serializer-main.xslt |
transformation entry point. |
| java-serializer.xslt |
generates tokens for top level constructs. |
| java-serializer-statements.xslt |
generates tokens for statements. |
| java-serializer-expressions.xslt |
generates tokens for expressions. |
| java-streamer.xslt |
converts tokens into lines. |
| DataAdapter.xml |
sample jxom document. |
This was my first experience with xslt 2.0. I feel very pleased with what it can do. The only missed feature is indirect function call (which I do not want to model with dull template matching approach).
Note that in spite that xslt I've built is platform independed I want to point out that I was experimenting with saxon 9. Several times I've relied on efficient tail call implementation (see t:cumulative-integer-sum), which otherwise will lead to xslt stack overflow.
I shall be pleased to see your feedback on the subject.
Hello,
I was not writing for a long time. IMHO: nothing to say? - do not noise!
Nowadays I'm busy with xslt.
Should I be pleased that w3c committee has finally delivered xpath 2.0/xslt 2.0/xquery? There possibly were people who have failed to wait till this happened, and who have died. Be grateful to the fate we have survived!
I'm working now with saxon 9. It's good implementation, however too interpreter like in my opinion. I think these languages could be compiled down to machine/vm code the same way as c++/java/c# do.
To the point.
I need to generate java code in xslt. I've done this earlier; that time I dealt with relatively simple templates like beans or interfaces. Now I need to generate beans, interfaces, classes with logic. In fact I should cover almost all java 6 features.
Immediately I've started thinking in terms of java xml object model (jxom). Thus there will be an xml schema of jxom (Am I inventing bicycle? I pray you to point me to an existing schema!) - java grammar as xml. There will be xslts, which generate code according to this schema, and xslt that will serialize jxom documents derectly into java.
This two stage generation is important as there are essentially two different tasks: generate java code, and serialize it down to a text format. Moreover whenever I have jxom document I can manipulate it! And finally this will allow to our team to concentrate efforts, as one should only generate jxom document.
Yesterday, I've found java ANLT grammar, and have converted it into xml schema: java.xsd. It is important to have this xml schema defined, even if no one shall use it except in editor, as it makes jxom generation more formal.
The next step is to create xslt serializer, which is in todo list.
To feel how jxom looks I've created it manually for some simple java file:
// $Id: DataAdapter.java 1122 2007-12-31 12:43:47Z arthurn $
package com.bphx.coolgen.data;
import java.util.List;
/**
* Encapsulates encyclopedia database access.
*/
public interface DataAdapter
{
/**
* Starts data access session for a specified model.
* @param modelId - a model to open.
*/
void open(int modelId)
throws Exception;
/**
* Ends data access session.
*/
void close()
throws Exception;
/**
* Gets current model id.
* @return current model id.
*/
int getModelId();
/**
* Gets data objects for a specified object type for the current model.
* @param type - an object type to get data objects for.
* @return list of data objects.
*/
List<DataObject> getObjectsForType(short type)
throws Exception;
/**
* Gets a list of data associations for an object id.
* @param id - object id.
* @return list of data associations.
*/
List<DataAssociation> getAssociations(int id)
throws Exception;
/**
* Gets a list of data properties for an object id.
* @param id - object id.
* @return list of data properties.
*/
List<DataProperty> getProperties(int id)
throws Exception;
}
jxom:
<unit xmlns="http://www.bphx.com/java-1.5/2008-02-07" package="com.bphx.coolgen.data">
<comment>$Id: DataAdapter.java 1122 2007-12-31 12:43:47Z arthurn $</comment>
<import package="java.util.List"/>
<interface access="public" name="DataAdapter">
<comment doc="true">Encapsulates encyclopedia database access.</comment>
<method name="open">
<comment doc="true">
Starts data access session for a specified model.
<para type="param" name="modelId">a model to open.</para>
</comment>
<parameters>
<parameter name="modelId"><type name="int"/></parameter>
</parameters>
<throws><type name="Exception"/></throws>
</method>
<method name="close">
<comment doc="true">Ends data access session.</comment>
<throws><type name="Exception"/></throws>
</method>
<method name="getModelId">
<comment doc="true">
Gets current model id.
<para type="return">current model id.</para>
</comment>
<returns><type name="int"/></returns>
<throws><type name="Exception"/></throws>
</method>
<method name="getObjectsForType">
<comment doc="true">
Gets data objects for a specified object type for the current model.
<para name="param" type="type">
an object type to get data objects for.
</para>
<para type="return">list of data objects.</para>
</comment>
<returns>
<type>
<part name="List">
<typeArgument><type name="DataObject"/></typeArgument>
</part>
</type>
</returns>
<parameters>
<parameter name="type"><type name="short"/></parameter>
</parameters>
<throws><type name="Exception"/></throws>
</method>
<method name="getAssociations">
<comment doc="true">
Gets a list of data associations for an object id.
<para type="param" name="id">object id.</para>
<para type="return">list of data associations.</para>
</comment>
<returns>
<type>
<part name="List">
<typeArgument><type name="DataAssociation"/></typeArgument>
</part>
</type>
</returns>
<parameters>
<parameter name="id"><type name="int"/></parameter>
</parameters>
<throws><type name="Exception"/></throws>
</method>
<method name="getProperties">
<comment doc="true">
Gets a list of data properties for an object id.
<para type="param" name="id">object id.</para>
<para type="return">list of data properties.</para>
</comment>
<returns>
<!-- Compact form of generic type. -->
<type name="List<DataProperty>"/>
</returns>
<parameters>
<parameter name="id"><type name="int"/></parameter>
</parameters>
<throws><type name="Exception"/></throws>
</method>
</interface>
</unit>
To read about xslt for jxom please follow this link.
C++ Standard Library Issues List, Issue 254I'm tracking this issue already for the several years, and have my unpretentious opinion. To make my arguments clear I'll bring the issue description here.
254. Exception types in clause 19 are constructed from std::string
Section: 19.1 [std.exceptions], 27.4.2.1.1 [ios::failure] Status: Tentatively Ready Submitter: Dave Abrahams Date: 2000-08-01
Discussion:
Many of the standard exception types which implementations are required to throw are constructed with a const std::string& parameter. For example: 19.1.5 Class out_of_range [lib.out.of.range]
namespace std {
class out_of_range : public logic_error {
public:
explicit out_of_range(const string& what_arg);
};
}
1 The class out_of_range defines the type of objects thrown as excep-
tions to report an argument value not in its expected range.
out_of_range(const string& what_arg);
Effects:
Constructs an object of class out_of_range.
Postcondition:
strcmp(what(), what_arg.c_str()) == 0.
There are at least two problems with this:
- A program which is low on memory may end up throwing std::bad_alloc instead of out_of_range because memory runs out while constructing the exception object.
- An obvious implementation which stores a std::string data member may end up invoking terminate() during exception unwinding because the exception object allocates memory (or rather fails to) as it is being copied.
There may be no cure for (1) other than changing the interface to out_of_range, though one could reasonably argue that (1) is not a defect. Personally I don't care that much if out-of-memory is reported when I only have 20 bytes left, in the case when out_of_range would have been reported. People who use exception-specifications might care a lot, though.
There is a cure for (2), but it isn't completely obvious. I think a note for implementors should be made in the standard. Avoiding possible termination in this case shouldn't be left up to chance. The cure is to use a reference-counted "string" implementation in the exception object. I am not necessarily referring to a std::string here; any simple reference-counting scheme for a NTBS would do.
Further discussion, in email:
...I'm not so concerned about (1). After all, a library implementation can add const char* constructors as an extension, and users don't need to avail themselves of the standard exceptions, though this is a lame position to be forced into. FWIW, std::exception and std::bad_alloc don't require a temporary basic_string.
...I don't think the fixed-size buffer is a solution to the problem, strictly speaking, because you can't satisfy the postcondition
strcmp(what(), what_arg.c_str()) == 0
For all values of what_arg (i.e. very long values). That means that the only truly conforming solution requires a dynamic allocation.
Further discussion, from Redmond:
The most important progress we made at the Redmond meeting was realizing that there are two separable issues here: the const string& constructor, and the copy constructor. If a user writes something like throw std::out_of_range("foo"), the const string& constructor is invoked before anything gets thrown. The copy constructor is potentially invoked during stack unwinding.
The copy constructor is a more serious problem, becuase failure during stack unwinding invokes terminate. The copy constructor must be nothrow. Curaçao: Howard thinks this requirement may already be present.
The fundamental problem is that it's difficult to get the nothrow requirement to work well with the requirement that the exception objects store a string of unbounded size, particularly if you also try to make the const string& constructor nothrow. Options discussed include:
- Limit the size of a string that exception objects are required to throw: change the postconditions of 19.1.2 [domain.error] paragraph 3 and 19.1.6 [runtime.error] paragraph 3 to something like this: "strncmp(what(), what_arg._str(), N) == 0, where N is an implementation defined constant no smaller than 256".
- Allow the const string& constructor to throw, but not the copy constructor. It's the implementor's responsibility to get it right. (An implementor might use a simple refcount class.)
- Compromise between the two: an implementation is not allowed to throw if the string's length is less than some N, but, if it doesn't throw, the string must compare equal to the argument.
- Add a new constructor that takes a const char*
(Not all of these options are mutually exclusive.)
...
To be honest, I do not understand their (committee members') decisions. It seems they are trying to conceal themselves from the problem virtually proposing to store character buffer in the exception object. In fact the problem is more general, and is related to any exception types that store some data, and which can throw during copy construction. How to avoid problems during copy construction? Well, do not perform activity that can lead to an exception. If copying data can throw, then do not copy it! Thus we have to share data between exception objects.
This logic brought me to a safe exception type design. E.g. exception object should keep refcounted handle to a data object that is shared between type instances.
The only question is: why didn't they even consider this way?
In one of our latest projects (GUI on .NET 2.0) we've felt all the power of .NET globalization, but an annoying thing happened too...
In our case such an annoying thing was sharing of UI culture info between main (UI) thread and all auxiliary threads (threads from ThreadPool, manually created threads etc.). It seems we've fallen into a .NET globalization pitfall.
We guessed that the same as main thread UI culture info for, at least, all asynchronous delegates' calls is used. This is a common mistake, and what's more annoying, there is no a single line in MSDN documentation about this issue. 
Let's look closer at this issue. Our application starts on computer with English regional settings ("en-En"), and during application starting we are changing UI culture info to one specified in configuration file: // set the culture from the config file
try
{
Thread.CurrentThread.CurrentUICulture =
new CultureInfo(Settings.Default.CultureName);
}
catch
{
// use the default UI culture info
}
Thus, all the screens of this GUI application will be displayed according with the specified culture. There are also localized strings stored in resource files that are used as log, exception messages etc., which can be displayed from within different threads (e.g. asynchronous delegates' calls).
So, when application is running and even all screens are displayed according with the specified culture, all the exceptions from auxiliary threads still in English.  This happened since threads for asynchronous calls are pulled out from ThreadPool, and all these threads were created using default culture. This happened since threads for asynchronous calls are pulled out from ThreadPool, and all these threads were created using default culture.
Conclusion
Take care about CurrentUICulture in different threads by yourself, and be careful - there are still pitfalls on this way...
Return a table of numbers from 0 up to a some value. I'm facing this recurring task once in several years. Such periodicity induces me to invent solution once again but using contemporary features.
November 18:
This time I have succeeded to solve the task in one select:
declare @count int;
set @count = 1000;
with numbers(value) as
(
select 0
union all
select value * 2 + 1 from numbers where value < @count / 2
union all
select value * 2 + 2 from numbers where value < (@count - 1) / 2
)
select
row_number() over(order by U.V) value
from
numbers cross apply (select 1 V) U;
Do you have a better solution?
We're building a .NET 2.0 GUI application. A part of a project is a localization. According to advices of msdn we have created *.resx files and sent them to foreign team that performs localization using WinRes tool.
Several of our user controls contained SplitContainer control. We never thought this could present a problem. Unfortunately it is!
When you're trying to open resx for a such user control you're getting:
Eror - Failed to load the resource due to the following error:
System.MissingMethodException: Constructor on type 'System.Windows.Forms.SplitterPanel' not found.
We started digging the WinRes.exe (thanks to .NET Reflector) and found the solution: we had to define the name of split container the way that its parent name appeared before (in ascending sort order) than splitter itself.
Say if you have a form "MyForm" and split container "ASplitContainer" then you should rename split container to say "_ASplitContainer". In this case resources are stored as:
| Name |
Parent Name |
| MyForm |
|
| _ASplitContainer |
MyForm |
| _ASplitContainer.Panel1 |
_ASplitContainer |
| _ASplitContainer.Panel2 |
_ASplitContainer |
This makes WinRes happy.
Today we had spent some time looking for samples of web-services in RPC/encoded style, and we have found a great site http://www.xmethods.com/. This site contains a lot of web-services samples in Document/literal and RPC/encoded styles. We think this link will be useful for both developers and testers.
Yesterday we had ran into following problem: how to retrieve session object from within Java web-service? The crucial point of the problem was that we are generating automatically our web-service from Java bean and this web-service works under WebSphere v5.1.1.
After some time we had spent to find acceptable solution, we have found that it's possible either to implement “session substitution” using EJB SessionBean or somehow to retrieve HttpSession instance.
The first approach has a lot of advantages before the second one, but it requires to implement bunch of EJB objects (session bean itself, home object etc.). The second approach just solve our problem for web-service via HTTP, and no more, but... it requires only few lines to be changed in Java bean code. This second approach is based on implementation of javax.xml.rpc.server.ServiceLifecyle interface for our Java bean. For details take a look at the following article: “Web services programming tips and tricks: Build stateful sessions in JAX-RPC applications“.
Actually, only two additional methods init() and destroy() were implemented. The init() method retrieves (during initialization) an ServletEndpointContext instance that is stored somewhere in private filed of the bean. Further the ServletEndpointContext.getHttpSession() is called in order to get HttpSession. So easy, so quickly - we just was pleased.
|