Developing with KendoUI we try to formalize tasks. With this in mind we would like to have user controls.
We define user control as following:
It is a javascript class that extends Widget.
It offers a way to reuse UI.
It allows to define a model and a template with UI and data binding.
Unfortunately, KendoUI does not have such API, though one can easily define it; so we have defined our version.
Here we review our solution. We have taken a grid KendoUI example and converted it into a user control.
User control on the page
See index.html
<!DOCTYPE html>
<html>
<head>
<title>Test</title>
<!-- (1) Include templates for controls. -->
<script src="scripts/templates.js"></script>
<script src="scripts/jquery/jquery.js"></script>
<script src="scripts/kendo/kendo.web.min.js"></script>
<!-- (2) UserControl definition. -->
<script src="scripts/controls.js"></script>
<!-- (3) Confirm dialog user control. -->
<script src="scripts/controls/confirm.js"></script>
<!-- (4) Products user control. -->
<script src="scripts/controls/products.js"></script>
<link href="styles/kendo.common.min.css" rel="stylesheet" />
<link href="styles/kendo.default.min.css" rel="stylesheet" />
<script>
$(function ()
{
// (5) Bind the page.
kendo.bind(
document.body,
// (6) Model as a datasource.
{ source: [new nesterovskyBros.data.ProductsModel] });
});
</script>
</head>
<body>
<!-- (7) User control and its binding. -->
<div data-role="products" data-bind="source: source"></div>
</body>
</html>
That's what
we see here:
- Templates that define layouts. See "How To: Load KendoUI Templates from External Files", and templates.tt.
- Definition of the UserControl widget.
- Confirm dialog user control (we shall mention it later).
- Products user control.
- Data binding that instantiates page controls.
- Model is passed to a user control through the dataSource.
- Use of Products user control. Notice that "data-role" defines control type, "source" refers to the model.
User Control declaration
Declaration consists of a view and a model.
View is html with data binding. See products.tmpl.html
We build our project using Visual Studio, so templates packaging is done with templates.tt. This transformation converts products template into a tag:
<script id="products-template" type="text/x-kendo-template">
thus template can be referred by a utility function: nesterovskyBros.template("products-template").
Model inherits kedo.data.Model. Here how it looks:
// (1) Define a ProducsModel class.
nesterovskyBros.data.ProductsModel = kendo.data.Model.define(
{
// (2) Model properties.
fields:
{
productName: { type: "string", defaultValue: "Product Name" },
productPrice: { type: "number", defaultValue: 10 },
productUnitsInStock: { type: "number", defaultValue: 10 },
products: { type: "default", defaultValue: [] }
},
// (3) Model methods.
addProduct: function ()
{
...
},
deleteProduct: function (e)
{
...
},
...
});
// (4) Register user control.
nesterovskyBros.ui.Products = nesterovskyBros.defineControl(
{
name: "Products",
model: nesterovskyBros.data.ProductsModel
});
That's what we have here:
- We define a model that inherits KendoUI Model.
- We define model fields.
- We define model methods.
- Register user control with
nesterovskyBros.defineControl(proto) call, where:
proto.name - defines user control name;proto.model - defines model type;proto.template - defines optional template. If not specified, a template is retrieved from $("#" + proto.name.toLowerCase() + "-template").html().
UserControl API
Now, what's remained is API for the UserControl. See controls.js.
- UserControl defines following events:
change - triggered when data source is changed;dataBound - triggered when widget is data bound;dataBinding - triggered befor widget data binding;save - used to notify user to save model state.
- UserControl defines following options:
autoBind (default false) - autoBind data source;template (default $.noop) - user control template.
- UserControl defines
dataSource field and setDataSource() method.
- UserControl defines
rebind() method to manually rebuild widget's view from the template and model.
- UserControl sets/deletes model.owner, which is a function returning a user control widget when model is bound/unbound to the widget.
- When UserControl binds/unbinds model a
model.refresh method is called, if any.
- You usually define you control with a call
nesterovskyBros.defineControl(proto). See above.
- There is also a convenience method to build a dialog based on a user control: nesterovskyBros.defineDialog(options), where
options.name - a user control name (used in the data-role);options.model - a model type;options.windowOptions - a window options.
This method returns a function that recieves a user control model, and returns a dialog (kendo.ui.Window) based on the user control.
Dialog has model() function that returns an instance of model.
Model has dialog() function that returns an instance of the dialog.
Dialog and model have result() function that returns an instance of deferred object used to track dialog completion.
The example of user control dialog is confirm.js and confirm.tmpl.html.
The use is in the products.js deleteProduct():
deleteProduct: function(e)
{
var that = this;
return nesterovskyBros.dialog.confirm(
{
title: "Please confirm",
message: "Do you want to delete the record?",
confirm: "Yes",
cancel: "No"
}).
open().
center().
result().
then(
function(confirmed)
{
if (!confirmed)
{
return;
}
...
});
}
Last
User controls along with technique to manage and cache templates allow us to build robust web applications. As the added value it's became a trivial task to build SPA.
See also: Compile KendoUI templates.
At present we inhabit in jquery and kendoui world.
There you deal with MVVM design pattern and build you page from blocks.
To avoid conflicts you usually restrict yourself from assigning ids
to elements, as they make code reuse somewhat problematic.
But what if you have a label that you would like to associate with an input. In
plain html you would write:
<label for="my-input">My label:</label> <input
id="my-input" type="text">
Html spec suggests to use element id to build such an association.
So, how to avoid introduction of id, and to allow to select input while
clicking on the label?
In our projects we use a little utility function that solves exactly this task.
It's easier to quote an example than to describe implementation:
<!DOCTYPE html>
<html>
<head>
<title>Label</title>
<script src="scripts/jquery.js"></script>
</head>
<body>
<div class="view">
<div>A template:</div>
<table>
<tr>
<td><label data-for="[name=field1]">Name1:</label></td>
<td><input name="field1" type="text" /></td>
</tr>
<tr>
<td><label data-for="[name=field2]">Name2:</label></td>
<td><input name="field2" type="text" /></td>
</tr>
<tr>
<td><label data-for="[name=field3]">Name3:</label></td>
<td><input name="field3" type="text" /></td>
</tr>
<tr>
<td><label data-for="[name=field4]">Name4:</label></td>
<td><input name="field4" type="checkbox" /></td>
</tr>
<tr>
<td><label data-for="[name=field5][value=0]">Name5:</label></td>
<td><input name="field5" value="0" type="radio" /></td>
</tr>
<tr>
<td><label data-for="[name=field5][value=1]">Name6:</label></td>
<td><input name="field5" value="1" type="radio" /></td>
</tr>
</table>
</div>
<script>
$(document).on(
"click",
"label[data-for]",
function(e)
{
var target = $(e.target);
target.closest(target.attr("data-view") || ".view").
find(target.attr("data-for")).
filter(":visible:enabled").first().click().focus().
filter("input[type=checkbox],input[type=radio]").change();
});
</script>
</body>
</html>
In our applications we must support IE 8, and unfortunately we hit some leak, which is registered as
Ticket #7054(closed bug: fixed).
While bug declared closed as fixed we can see that memory leak in IE8 like a mad.
Not sure if something can be done about it.
The test case is:
<!DOCTYPE html>
<html>
<head>
<title>Test</title>
<script src="scripts/jquery/jquery-1.9.0.js"></script>
</head>
<body>
<script>
function testLeak()
{
var handler = function () { };
$('<div></div>').html(new Array(1000).join(new Array(1000).join('x'))).bind('abc', handler).appendTo('#test').remove();
}
$(function() { setInterval(testLeak, 1000); });
</script>
<div id="test"></div>
</body>
</html>
Update: jaubourg has pointed that we have missed to define element with id="test". With this element leak stops.
Kendo UI Docs contains an article "How To:
Load Templates from External Files", where authors review two way of dealing
with Kendo UI templates.
While using Kendo UI we have found our own answer to: where will the Kendo
UI templates be defined and maintained?
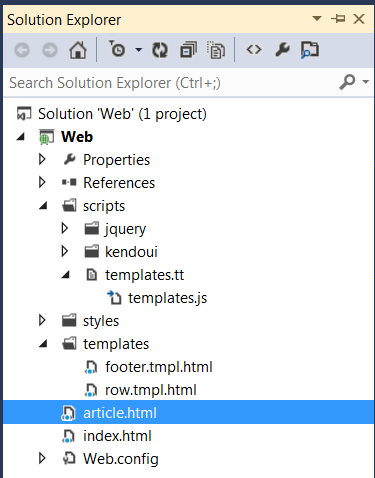
In our .NET project we have decided to keep templates separately, and to store
them under the "templates" folder. Those templates are in fact include html,
head, and stylesheet links. This is to help us to present those tempates in the
design view.
In our scripts folder, we have defined a small text transformation template:
"templates.tt", which produces "templates.js" file. This template takes body
contents of each "*.tmpl.html" file from "templates" folder and builds string of
the form:
document.write('<script id="footer-template" type="text/x-kendo-template">...</script><script id="row-template" type="text/x-kendo-template">...</script>');
In our page that uses templates, we include "templates.js":
<!DOCTYPE html>
<html>
<head>
<script
src="scripts/templates.js"></script>
...
Thus, we have:
- clean separation of templates and page content;
- automatically generated templates include file.
WebTemplates.zip contains a web project demonstrating our technique. "templates.tt" is
text template transformation used in the project.
See also: Compile KendoUI templates.
Our goal is to generate reports in streaming mode.
At some point we need to deal with data streams (e.g. xml streams for xslt
transformations). Often a nature of report demands several passes through the data.
To increase performance we have defined a class named StreamResource.
This class encapsulates input data, reads it once and caches it into a temp
file; thus data can be traversed many times. StreamResource can
read data lazily or in a eager way thus releasing resources early.
This class can be used as a variation of PipeStream, which never blocks, as if
a size of a buffer is not limited, and which can be read many times.
The API
looks like this:
public class StreamResource: IDisposable
{
/// <summary>
/// Creates a StreamSource instance.
/// </summary>
/// <param name="source">
/// A function that returns source as an input stream.
/// </param>
/// <param name="settings">Optional settings.</param>
public StreamResource(Func<Stream> source, Settings settings = null);
/// <summary>
/// Creates a StreamSource instance.
/// </summary>
/// <param name="source">
/// A function that writes source data into an output stream.
/// </param>
/// <param name="settings">Optional settings.</param>
public StreamResource(Action<Stream> source, Settings settings = null);
/// <summary>
/// Gets an input stream.
/// </summary>
/// <param name="shared">
/// Indicates that this StreamResouce should be disposed when returned
/// stream is closed and there are no more currently opened cache streams.
/// </param>
/// <returns>A input stream.</returns>
public Stream GetStream(bool shared = false);
}
The use pattern is following:
// Acquire resource.
using(var resource = new StreamResource(() =>
CallService(params...)))
{
// Read stream.
using(var stream = resource.GetStream())
{
...
}
...
// Read stream again.
using(var stream = resource.GetStream())
{
...
}
}
StreamResource is efficient even if you need to process content only once, as
it monitors timings of reading of source data and compares it with timings of
data consumption. If the difference exceeds some threshold then StreamResource
caches source greedily, otherwise source is pooled lazily. Thus, input resources
can be released promptly. This is important, for example, when the source
depends on a database connection.
The use pattern is following:
// Acquire resource and get shared stream.
using(var stream = new StreamResource(() =>
CallService(params...)).GetStream(true))
{
...
}
Finally, StreamResource allows to process
data in a pipe stream mode. This is when you have a generator function
Action<Stream> that can write to a stream, and you want to read that data.
The advantage of StreamResource over real pipe stream is that it
can work without blocking of generator, thus releasing resources early.
The use pattern is similar to the previous one:
using(var stream = new StreamResource(output =>
Generate(output, params...)).GetStream(true))
{
...
}
The source of the class can be found at
Streaming.zip.
Two monthes ago we have started
a process of changing column type from smallint to int in a big database.
This was splitted in two phases:
- Change tables and internal stored procedures and functions.
- Change interface API and update all clients.
The first part took almost two monthes to complete. Please read earlier post about
the technique we have selected for the implementation. In total we have transferred
about 15 billion rows. During this time database was online.
The second part was short but the problem was that we did not control all clients,
so could not arbitrary change types of parameters and of result columns.
All our clients use Entity Framework 4 to access the database. All access is done
though stored procedures. So suppose there was a procedure:
create procedure Data.GetReports(@type smallint) as
begin
select Type, ... from Data.Report where Type = @type;
end;
where column "Type" was of type smallint. Now
we were going to change it to:
create procedure Data.GetReports(@type int) as
begin
select Type, ... from Data.Report where Type = @type;
end;
where "Type" column became of type int.
Our tests have shown that EF bears with change of types of input parameters, but throws
exceptions when column type has been changed, even when a value fits the
range. The reason is that EF uses method SqlDataReader.GetInt16
to access the column value. This method has a remark: "No
conversions are performed; therefore, the data retrieved must already be a 16-bit
signed integer."
Fortunately, we have found that EF allows additional columns in the result set. This helped us to formulate the solution.
We have updated the procedure definition like this:
create procedure Data.GetReports(@type int) as
begin
select
cast(Type as smallint) Type, -- deprecated
Type TypeEx, ...
from
Data.Report
where
Type = @type;
end;
This way:
- result column
"Type" is declared as deprecated;
- old clients still work;
- all clients should be updated to use
"TypeEx" column;
- after all clients will be updated we shall remove
"Type" column from the result
set.
So there is a clear migration process.
P.S. we don't understand why SqlDataReader doesn't support value
conversion.
If you deal with
web applications you probably have already dealt with export data to Excel.
There are several options to prepare data for Excel:
- generate CSV;
- generate HTML that excel understands;
- generate XML in Spreadsheet 2003 format;
- generate data using Open XML SDK or some other 3rd party libraries;
- generate data in XLSX format, according to Open XML specification.
You may find a good article with pros and cons of each solution
here. We, in our turn, would like to share our experience in this field. Let's start from requirements:
- Often we have to export huge data-sets.
- We should be able to format, parametrize and to apply different styles to the exported data.
- There are cases when exported data may contain more than one table per sheet or
even more than one sheet.
- Some exported data have to be illustrated with charts.
All these requirements led us to a solution based on XSLT processing of streamed data.
The advantage of this solution is that the result is immediately forwarded to a client as fast as
XSLT starts to generate output. Such approach is much productive than generating of XLSX using of Open XML SDK or any other third party library, since it avoids keeping
a huge data-sets in memory on the server side.
Another advantage - is simple maintenance, as we achieve
clear separation of data and presentation layers. On each request to change formatting or
apply another style to a cell you just have to modify xslt file(s) that generate
variable parts of XLSX.
As result, our clients get XLSX files according with Open XML specifications.
The details of implementations of our solution see in our next posts.
Recently we had a discussion with DBA regarding optimization strategey we have
selected for some queries.
We have a table in our database. These are facts about that table:
- the table is partitioned by date;
- each partition contains a month worth of data;
- the table contains at present about 110 million rows;
- the table ever grows;
- the table is most accessed in the database;
- the most accessed part of the data is related to last 2-3 days,
which is about 150000 rows.
The way we have optimized access to that table was a core of the dispute.
We have created filtered index that includes data for the last 3 days.
To achieve desired effect we had to:
- create a job that recreates that index once a day, as filter condition is
moving;
- adjust queries that access the table, as we had to use several access pathes
to the table depending on date.
As result we can see that under the load, stored procedures that access that table
became almost 50% faster. On the other hand maintainance became more
complicated.
DBA who didn't like the database complications had to agree that there are speed
improvements. He said that there should be a better way to achieve the same
effect but could not find it.
Are there a better way to optimize access to this table?
We're implementing UDT changes in the big database. Earlier, that
User Defined Type was based on smallint, and now we have to use int as the base.
The impact
here is manyfold:
- Clients of the database should be prepared to use wider types.
- All stored procedures, functions, triggers, and views should be updated
accordingly.
- Impact on the database size should be analyzed.
- Types of columns in tables should be changed.
- Performance impact should be minimal.
Now, we're trying to address (3),
(5) and to implement (4), while trying to keep interface with clients using old
types.
As for database size impact, we have found that an index fragmentation is a
primary disk space waster (see Reorganize index in SQL Server).
We have performed some partial index reorganization and can see now that we can gain
back hundreds of GB of a disk space. On the other hand we use page compression, so we expect that change of types will not increase
sizes of tables considerably. Indeed, our measurments show that tables will only be
~1-3% bigger.
The change of types of columns is untrivial task. The problem is that if you try
to change column's type (which is part of clustered index) directly then you
should temporary remove foreign keys, and to rebuild all indices. This won't
work neither due to disk space required for the operation (a huge transaction
log is required), nor due to availability of tables (we're talking about days or
even weeks to rebuild indices).
To work-around the problem we have selected another way. For each target table T
we performed the following:
- Renamed table T to T_old;
- Created a table T_new with required type changes;
- Created a view named T, which is union of T_old for the dates before a split
date and T_new for the dates after the split date;
- Created instead of insert/update/delete triggers for the view T.
- Created a procedures that move data in bulks from T_old to the T_new, update
split date in view definitions, and delete data from T_old.
Note that:
- the new view uses wider column types, so we had to change stored
procedures that clients use to cast those columns back to shorter types to
prevent side effects (fortunately all access to this database is through stored
procedures and functions);
- the procedures that transfer data between new and old tables may work online;
- the quality of execution plans did not degrade due to switch from table to a
view;
- all data related to the date after the split date are inserted into T_new
table.
After transfer will be complete we shall drop T_old tables, and T views, and
will rename T_new tables into T.
This will complete part 4 of the whole task. Our estimations are that it will
take a month or even more to complete the transfer. However solution is rather
slow, the database will stay online whole this period, which is required
condition.
The next task is to deal with type changes in parameters of stored procedures
and column types of output result sets. We're not sure yet what's the best way
to deal with it, and probably shall complain about in in next posts.
Back in 2006 and 2007 we have defined dbo.Numbers function:
Numbers table in SQL Server 2005,
Parade of numbers. Such construct is very important in a set based
programming. E.g. XPath 2 contains a range expression like this: "1 to 10" to
return a sequence of numbers.
Unfortunately neither SQL Server 2008 R2, nor SQL Server 2012 support such
construct, so dbo.Numbers function is still actual.
After all these years the function evolved a little bit to achieve a better
performance. Here is its source:
-- Returns numbers table.
-- Table has a following structure: table(value int not null);
-- value is an integer number that contains numbers from 1 to a specified value.
create function dbo.Numbers
(
-- Number of rows to return.
@count int
)
returns table
as
return
with Number8 as
(
select
*
from
(
values
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)
) N(Value)
),
Number32(Value) as
(
select
0
from
Number8 N1
left join
Number8 N2
on
@count > 0x100
left join
Number8 N3
left join
Number8 N4
on
@count > 0x1000000
on
@count > 0x10000
)
select top(@count) row_number() over(order by @count) Value from Number32;
We're working with an online database, which is ever populated with a new
data. Database activity is mostly around recent data. Activity against older
data declines with increasing the distance from today. The ratio of an amount of a
new data, say for a last month, to the whole data, at present stays at
~1%. The size of database is measured in TBs.
While we're developers and not DBA's, you will see from
a later blog
posts why we're bothered with the database size. In short we're planning to
change some UDF type from smallint to int. This will impact
on many tables, and the task now is to estimate that impact.
Our first attempts to measure the difference between table sizes before and
after type change showed that a data fragmentation often masks the difference, so
we started to look at a way to reduce fragmentation.
Internet is full with recomentations. An advice can be found in BOL at
Reorganize
and Rebuild Indexes.
So, our best help in this task is the function sys.dm_db_index_physical_stats,
which reports statistics about fragmentation.
Analysing what that function has given to us we could see that we had a highly
fragmented data. There was no reason to bear with that taking into an account that
the most of the data stored in the database is historical, which is rarely
accessed and even more rarely updated.
The next simplest instument adviced is:
alter index { index_name | ALL } on <object> reorganize [ PARTITION = partition_number ];
The less trivial but often more efficient instrument is the use of online index
rebuild and index reorganize depending on index type and a level of
fragmentation.
All in all our estimation is that rebuilding or reorganizing indices frees
~100-200GBs of disk space. While, it's only a small percent of total database
size, it gives us several monthes worth of a disk space!
Earlier we overlooked SQL Server API to monitor fragmentation, rebuild, and
reorganize indices, and now we're going to create a job that will regulary
defragment the database.
We have a large table in the form:
create table dbo.Data
(
Date date not null,
Type int not null,
Value nvarchar(50) null,
primary key clustered(Date, Type)
);
create unique nonclustered index IX_Data on dbo.Data(Type, Date);
Among other queries we often need a snapshot of data per each Type for a latest
Date available:
select
max(Date) Date,
Type
from
dbo.Data
group by
Type
We have
found that the above select does not run well on our data set. In fact dbo.Data
grows with time, while snapshot we need stays more or less of the same size. The
best solution to such query is to precalculate it. One way would be to create an
indexed view, but SQL Server does not support max() aggregate in indexed views.
So, we have decided to add additional bit field dbo.Data.Last indicating that
a row belongs to a last date snapshot, and to create filtered index to access
that snapshot:
create table dbo.Data
(
Date date not null,
Type int not null,
Value nvarchar(50) null,
Last bit not null default 0,
primary key clustered(Date, Type)
);
create unique nonclustered index IX_Data on dbo.Data(Type, Date);
create unique nonclustered index IX_Data_Last on dbo.Data(Type)
include(Date)
where Last = 1;
One way to support Last indicator is to create a trigger that will adjust Last
value:
create trigger dbo.Data_Update on dbo.Data
after insert,delete,update
as
begin
if (trigger_nestlevel(@@procid) < 2)
begin
set nocount on;
with
D as
(
select Date, Type from deleted
union
select Date, Type from inserted
),
U as
(
select
V.Date, V.Type
from
D
inner join
dbo.Data V
on
(V.Last = 1) and
(V.Type = D.Type)
union
select
max(V.Date) Date,
V.Type
from
D
inner join
dbo.Data V
on
V.Type = D.Type
group by
V.Type
),
V as
(
select
rank()
over(partition by
V.Type
order by
V.Date desc) Row,
V.*
from
dbo.Data V
inner join
U
on
(V.Date = U.Date) and
(V.Type = U.Type)
)
update V
set
Last = 1 - cast(Row - 1 as bit);
end;
end;
With Last indicator in action, our original query has been transformed to:
select Date, Type
from dbo.Data where Last = 1
Execution plan shows that a new filtered index
IX_Data_Last is used. Execution speed has increased considerably.
As our actual table contains other bit fields, so Last
indicator did not
increase the table size, as SQL Server packs each 8 bit fields in one byte.
Earlier we have shown
how to build streaming xml reader from business data and have reminded about
ForwardXPathNavigator which helps to create
a streaming xslt transformation. Now we want to show how to stream content
produced with xslt out of WCF service.
To achieve streaming in WCF one needs:
1. To configure service to use streaming. Description on how to do this can be
found in the internet. See web.config of the sample
Streaming.zip for the details.
2. Create a service with a method returning Stream:
[ServiceContract(Namespace = "http://www.nesterovsky-bros.com")]
[AspNetCompatibilityRequirements(RequirementsMode = AspNetCompatibilityRequirementsMode.Allowed)]
public class Service
{
[OperationContract]
[WebGet(RequestFormat = WebMessageFormat.Json)]
public Stream GetPeopleHtml(int count,
int seed)
{
...
}
}
2. Return a Stream from xsl transformation.
Unfortunately (we mentioned it already), XslCompiledTransform generates its
output into XmlWriter (or into output Stream) rather than exposes result as
XmlReader, while WCF gets input stream and passes it to a client.
We could generate xslt output into a file or a memory Stream and then return
that content as input Stream, but this will defeat a goal of streaming, as
client would have started to get data no earlier that the xslt completed its
work. What we need instead is a pipe that form xslt output Stream to an input
Stream returned from WCF.
.NET implements pipe streams, so our task is trivial.
We have defined a utility method that creates an input Stream from a generator
populating an output Stream:
public static Stream GetPipedStream(Action<Stream> generator)
{
var output = new AnonymousPipeServerStream();
var input = new AnonymousPipeClientStream(
output.GetClientHandleAsString());
Task.Factory.StartNew(
() =>
{
using(output)
{
generator(output);
output.WaitForPipeDrain();
}
},
TaskCreationOptions.LongRunning);
return input;
}
We wrapped xsl transformation as such a generator:
[OperationContract]
[WebGet(RequestFormat = WebMessageFormat.Json)]
public Stream GetPeopleHtml(int count, int seed)
{
var context = WebOperationContext.Current;
context.OutgoingResponse.ContentType = "text/html";
context.OutgoingResponse.Headers["Content-Disposition"] =
"attachment;filename=reports.html";
var cache = HttpRuntime.Cache;
var path = HttpContext.Current.Server.MapPath("~/People.xslt");
var transform = cache[path] as XslCompiledTransform;
if (transform == null)
{
transform = new XslCompiledTransform();
transform.Load(path);
cache.Insert(path, transform, new CacheDependency(path));
}
return Extensions.GetPipedStream(
output =>
{
// We have a streamed business data.
var people = Data.CreateRandomData(count, seed, 0, count);
// We want to see it as streamed xml data.
using(var stream =
people.ToXmlStream("people", "http://www.nesterovsky-bros.com"))
using(var reader = XmlReader.Create(stream))
{
// XPath forward navigator is used as an input source.
transform.Transform(
new ForwardXPathNavigator(reader),
new XsltArgumentList(),
output);
}
});
}
This way we have build a code that streams data directly from business data to a
client in a form of report. A set of utility functions and classes helped us to
overcome .NET's limitations and to build simple code that one can easily
support.
The sources can be found at
Streaming.zip.
In the previous
post about streaming we have dropped at the point where we have XmlReader
in hands, which continously gets data from IEnumerable<Person>
source.
Now we shall remind about ForwardXPathNavigator - a class we have built
back in 2002, which adds streaming transformations to .NET's xslt processor.
While XslCompiledTransform is desperately obsolete, and no upgrade
will possibly follow; still it's among the fastest xslt 1.0 processors. With
ForwardXPathNavigator we add ability to transform input data of arbitrary size to this processor.
We find it interesting that
xslt 3.0 Working Draft defines streaming processing in a way that closely
matches rules for ForwardXPathNavigator:
Streaming achieves two important objectives: it allows large documents to be transformed
without requiring correspondingly large amounts of memory; and it allows the processor
to start producing output before it has finished receiving its input, thus reducing
latency.
The rules for streamability, which are defined in detail in 19.3 Streamability
Analysis, impose two main constraints:
-
The only nodes reachable from the node that is currently being processed are its
attributes and namespaces, its ancestors and their attributes and namespaces, and
its descendants and their attributes and namespaces. The siblings of the node, and
the siblings of its ancestors, are not reachable in the tree, and any attempt to
use their values is a static error. However, constructs (for example, simple forms
of xsl:number, and simple positional patterns) that require knowledge
of the number of preceding elements by name are permitted.
-
When processing a given node in the tree, each descendant node can only be visited
once. Essentially this allows two styles of processing: either visit each of the
children once, and then process that child with the same restrictions applied; or
process all the descendants in a single pass, in which case it is not possible while
processing a descendant to make any further downward selection.
The only significant difference between ForwardXPathNavigator and
xlst 3.0 streaming is in that we reported violations of rules for streamability
at runtime, while xslt 3.0 attempts to perform this analysis at compile time.
Here the C# code for the xslt streamed transformation:
var transform = new XslCompiledTransform();
transform.Load("People.xslt");
// We have a streamed business data.
var people = Data.CreateRandomData(10000, 0, 0, 10000);
// We want to see it as streamed xml data.
using(var stream =
people.ToXmlStream("people", "http://www.nesterovsky-bros.com"))
using(var reader = XmlReader.Create(stream))
using(var output = File.Create("people.html"))
{
// XPath forward navigator is used as an input source.
transform.Transform(
new ForwardXPathNavigator(reader),
new XsltArgumentList(),
output);
}
Notice how XmlReader is wrapped into ForwardXPathNavigator.
To complete the picture we need xslt that follows the streaming rules:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:d="http://www.nesterovsky-bros.com"
exclude-result-prefixes="msxsl d">
<xsl:output method="html" indent="yes"/>
<!-- Root template processed in the streaming mode. -->
<xsl:template match="/d:people">
<html>
<head>
<title>List of persons</title>
<style type="text/css">
.even
{
}
.odd
{
background: #d0d0d0;
}
</style>
</head>
<body>
<table border="1">
<tr>
<th>ID</th>
<th>First name</th>
<th>Last name</th>
<th>City</th>
<th>Title</th>
<th>Age</th>
</tr>
<xsl:for-each select="d:person">
<!--
Get element snapshot.
A
snapshot allows arbitrary access to the element's content.
-->
<xsl:variable name="person">
<xsl:copy-of select="."/>
</xsl:variable>
<xsl:variable name="position" select="position()"/>
<xsl:apply-templates mode="snapshot" select="msxsl:node-set($person)/d:person">
<xsl:with-param name="position" select="$position"/>
</xsl:apply-templates>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
<xsl:template mode="snapshot" match="d:person">
<xsl:param name="position"/>
<tr>
<xsl:attribute name="class">
<xsl:choose>
<xsl:when test="$position mod 2 = 1">
<xsl:text>odd</xsl:text>
</xsl:when>
<xsl:otherwise>
<xsl:text>even</xsl:text>
</xsl:otherwise>
</xsl:choose>
</xsl:attribute>
<td>
<xsl:value-of select="d:Id"/>
</td>
<td>
<xsl:value-of select="d:FirstName"/>
</td>
<td>
<xsl:value-of select="d:LastName"/>
</td>
<td>
<xsl:value-of select="d:City"/>
</td>
<td>
<xsl:value-of select="d:Title"/>
</td>
<td>
<xsl:value-of select="d:Age"/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
So, we have started with a streamed entity data, proceeded to the streamed
XmlReader and reached to the streamed xslt transformation.
But at the final post about streaming we shall remind a simple way of building
WCF service returning html stream from our xslt transformation.
The sources can be found at
Streaming.zip.
If you're using .NET's IDictionary<K, V> you have probably found
its access API too boring. Indeed at each access point you have to write a code
like this:
MyValueType value;
var hasValue = dictionary.TryGetValue(key, out value);
...
In many, if not in most, cases the value is of a reference type, and you do not
usually store null values, so it would be fine if dictionary
returned null when value does not exist for the key.
To deal with this small nuisance we have declared a couple of accessor
extension methods:
public static class Extensions
{
public static V Get<K, V>(this IDictionary<K, V> dictionary, K key)
where V: class
{
V value;
if (key == null)
{
value = null;
}
else
{
dictionary.TryGetValue(key, out value);
}
return value;
}
public static V Get<K, V>(this IDictionary<K, V> dictionary, K? key)
where V: class
where K: struct
{
V value;
if (key == null)
{
value = null;
}
else
{
dictionary.TryGetValue(key.GetValueOrDefault(), out value);
}
return value;
}
}
These methods simplify dictionary access to:
var value = dictionary.Get(key);
...
|