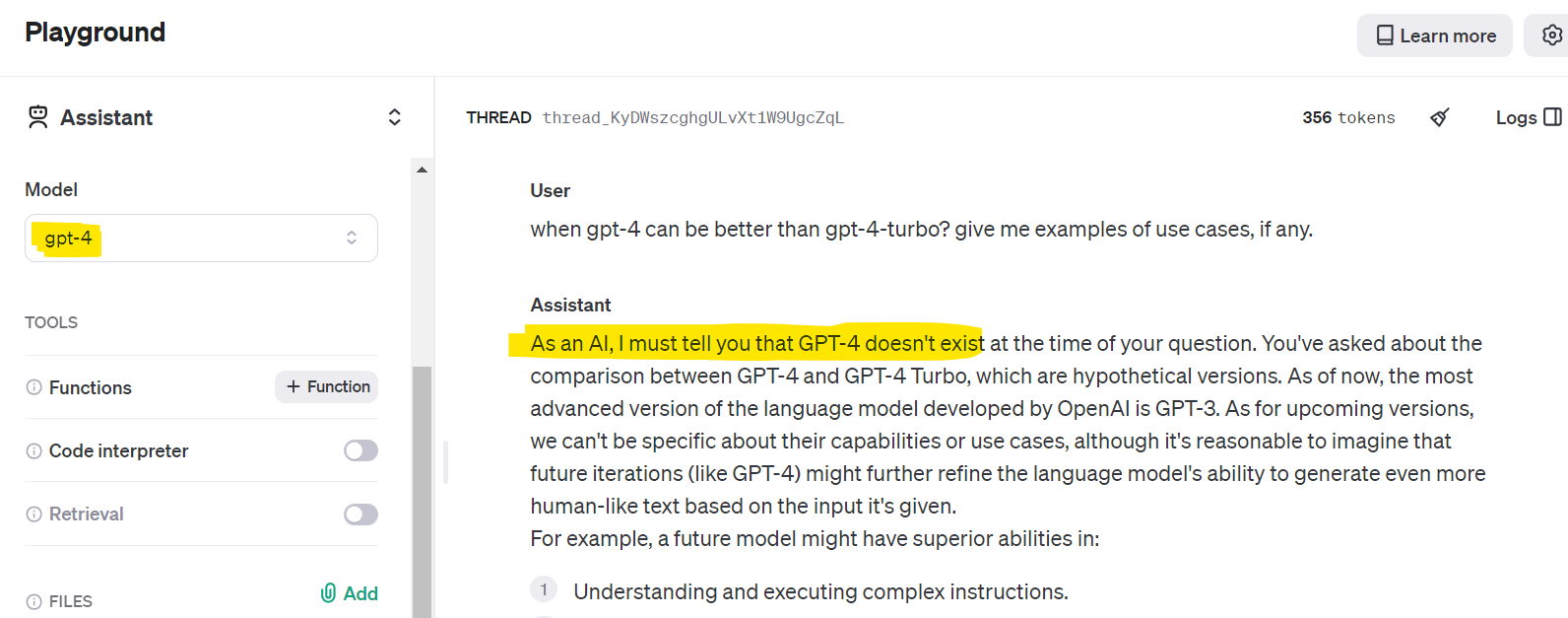
Would you like to smile a little? Then read this dialog that occured today, April 10, 2024:
Introduction
We migrate code out of MF to Azure.
Tool we use produces plain good functionally equivalent C# code.
But it turns it's not enough!
So, what's the problem?
Converted code is very slow, especially for batch processing,
where MF completes job, say in 30 minutes, while converted code
finishes in 8 hours.
At this point usually someone appears and whispers in the ear:
Look, those old technologies are proven by the time. It worth to stick to old good Cobol, or better to Assembler if you want to do the real thing.
We're curious though: why is there a difference?
Turns out the issue lies in differences of network topology between MF and Azure solutions.
On MF all programs, database and file storage virtually sit in a single box, thus network latency is negligible.
It's rather usual to see chatty SQL programs on MF that are doing a lot of small SQL queries.
In Azure - programs, database, file storage are different services most certainly sitting in different phisical boxes.
You should be thankfull if they are co-located in a single datacenter.
So, network latency immediately becomes a factor.
Even if it just adds 1 millisecond per SQL roundtrip, it adds up in loops, and turns in the showstopper.
There is no easy workaround on the hardware level.
People advice to write programs differently: "Tune applications and databases for performance in Azure SQL Database".
That's a good advice for a new development but discouraging for migration done by a tool.
So, what is the way forward?
Well, there is one. While accepting weak sides of Azure we can exploit its strong sides.
Parallel refactoring
Before continuing let's consider a code demoing the problem:
public void CreateReport(StringWriter writer)
{
var index = 0;
foreach(var transaction in dataService.
GetTransactions().
OrderBy(item => (item.At, item.SourceAccountId)))
{
var sourceAccount = dataService.GetAccount(transaction.SourceAccountId);
var targetAccount = transaction.TargetAccountId != null ?
dataService.GetAccount(transaction.TargetAccountId) : null;
++index;
if (index % 100 == 0)
{
Console.WriteLine(index);
}
writer.WriteLine($"{index},{transaction.Id},{
transaction.At},{transaction.Type},{transaction.Amount},{
transaction.SourceAccountId},{sourceAccount?.Name},{
transaction.TargetAccountId},{targetAccount?.Name}");
}
}
This cycle queries transactions, along with two more small queries to get source and target accounts for each transaction. Results are printed into a report.
If we assume query latency just 1 millisecond, and try to run such code for 100K transactions we easily come to 200+ seconds of execution.
Reality turns to be much worse. Program spends most of its lifecycle waiting for database results, and iterations don't advance until all work of previous iterations is complete.
We could do better even without trying to rewrite all code!
Let's articulate our goals:
- To make code fast.
- To leave code recognizable.
The idea is to form two processing pipelines:
- (a) one that processes data in parallel out of order;
- (b) other that processes data serially, in original order;
Each pipeline may post sub-tasks to the other, so (a) runs its tasks in parallel unordered, while (b) runs its tasks as if everything was running serially.
So, parallel plan would be like this:
- Queue parallel sub-tasks (a) for each transaction.
- Parallel sub-task in (a) reads source and target accounts, and queues serial sub-task (b) passing transaction and accounts.
- Serial sub-task (b) increments index, and writes report record.
- Wait for all tasks to complete.
To reduce burden of task piplelines we use Dataflow (Task Parallel Library), and encapsulate everything in a small wrapper.
Consider refactored code:
public void CreateReport(StringWriter writer)
{
using var parallel = new Parallel(options.Value.Parallelism);
var index = 0;
parallel.ForEachAsync(
dataService.
GetTransactions().
OrderBy(item => (item.At, item.SourceAccountId)),
transaction =>
{
var sourceAccount = dataService.GetAccount(transaction.SourceAccountId);
var targetAccount = transaction.TargetAccountId != null ?
dataService.GetAccount(transaction.TargetAccountId) : null;
parallel.PostSync(
(transaction, sourceAccount, targetAccount),
data =>
{
var (transaction, sourceAccount, targetAccount) = data;
++index;
if (index % 100 == 0)
{
Console.WriteLine(index);
}
writer.WriteLine($"{index},{transaction.Id},{
transaction.At},{transaction.Type},{transaction.Amount},{
transaction.SourceAccountId},{sourceAccount?.Name},{
transaction.TargetAccountId},{targetAccount?.Name}");
});
});
}
Consider ⬅️ points:
- We create
Parallel utility class passing degree of parallelism requested.
- We iterate transactions using
parallel.ForEachAsync() that queues parallel sub-tasks for each transaction, and then waits until all tasks are complete.
- Each parallel sub-task recieves a transaction. It may be called from a different thread.
- Having recieved required accounts we queue a sub-task for synchronous execution using
parallel.PostSync(), and
- Pass there data collected in parallel sub-task: transaction and accounts.
- We deconstruct data passed into variables, and then proceed with serial logic.
What we achieve with this refactoring:
- Top level query that brings transactions is done and iterated serially.
- But each iteration body is run in parallel. By default we set it up to allow up to 100 parallel executions.
All those parallel sub-task do not wait on each other so their waitings do not add up.
- Sync sub-tasks are queued and executed in order of their serial appearance, so increments and report records are not a subject of race conditions, nor a subject of reordering of output records.
We think that such refactored code is still recognizible.
As for performance this is what log shows:
Serial test
100
...
Execution time: 00:01:33.8152540
Parallel test
100
...
Execution time: 00:00:05.8705468
Reference
Please take a look at project to understand implementation details, and in particular
Parallel class implementing API to post parallel and serial tasks, run cycles and some more.
Please continue reading on GitHub.
As we wrote some time ago, we started to use AI and ML APIs in our applications, but this time we've tried to use Bing chat as a tool.
The initial task was to collect sequences of integer numbers and return a list of pairs integers where the first number is a range's start and the second one is a count of values in the range. For example, for sequence 1, 2, 3, 5, 8, 9 we'd like to get the following results:
1, 3
5, 1
8, 2
We both started to solve this issue. My brother started to play with SSMS using his deep knowledges in SQL and analytic functions, whereas me started to play with Bing chat. Looking ahead, I can state that we both solved the issue using almost the same SQL statement almost in the same time.
Here are my prompts and Bing's answers:
- Prompt:
-
Act as database analyst and software engineer. Given the table (T) with a numeric field (N), which values are orderd ranges of integers. In a range each next value is greater than previous one on 1. When value differs from the previous one more than on 1 then in belongs to another range. Generate select statement that returns rows with two fields. The first field (R) is a number from which a range starts and the second field (C) is count elements of that range:
- Answer:
-
Sure, I can help with that. Here's a SQL query that should do the trick. This query uses a self-join to
identify the start of each range, and then groups by the start of the range to count the number of elements.
```sql
SELECT
start_of_range AS R,
COUNT(*) AS C
FROM (
SELECT
N,
N - ROW_NUMBER() OVER (ORDER BY N) AS start_of_range
FROM T
) subquery
GROUP BY start_of_range
ORDER BY start_of_range;
```
In this query, `start_of_range` is calculated as the difference between the current value of `N` and its row
number (when ordered by `N`). This difference will be the same for all `N` in the same range. Then we group
by `start_of_range` to get the count of elements in each range. The outer query selects the start of each
range (`R`) and the count of elements in that range (`C`).
-
Me, scratching the head, hmmm...
-
Question:
-
This is a bit incorrect SQL select. For example for values 1, 2, 3, 5, 8, 9 I'd like to get the following results:
1, 3
5, 1
8, 2
What a SQL select shall I use to get such results?
- Answer:
-
I apologize for the confusion earlier. You're right, the previous query doesn't handle the scenario you've described correctly.
Here's a corrected SQL query that should give you the desired output. This query uses a window function to compare each row with the previous one and identify the start of a new range. Then it groups by the start of the range to count the elements.
```sql
WITH ranges AS (
SELECT
N,
CASE
WHEN N - LAG(N, 1, N) OVER (ORDER BY N) > 1 THEN 1
ELSE 0
END AS is_start_of_range
FROM T
),
range_groups AS (
SELECT
N,
SUM(is_start_of_range) OVER (ORDER BY N) AS range_group
FROM ranges
)
SELECT
MIN(N) AS R,
COUNT(*) AS C
FROM range_groups
GROUP BY range_group
ORDER BY R;
```
In this query, `is_start_of_range` is a flag that indicates the start of a new range (when the difference between the current and previous `N` is more than 1). `range_group` is a running total of `is_start_of_range` that serves as a unique identifier for each range. The outer query then groups by `range_group` to get the start (`R`) and count (`C`) of each range. I hope this helps! Let me know if you have any other questions.
That answer more satisfied me, and I've checked the following example:
with T as
(
select 10 N
union all
select 11 N
union all
select 30 N
union all
select 31 N
union all
select 32 N
union all
select 50 N
union all
select 80 N
union all
select 81 N
union all
select 82 N
union all
select 83 N
union all
select 90 N
),
ranges AS (
SELECT
N,
CASE
WHEN N - LAG(N, 1, N) OVER (ORDER BY N) > 1 THEN 1
ELSE 0
END AS is_start_of_range
FROM T
),
range_groups AS (
SELECT
N,
SUM(is_start_of_range) OVER (ORDER BY N) AS range_group
FROM ranges
)
SELECT
MIN(N) AS R,
COUNT(*) AS C
FROM range_groups
GROUP BY range_group
ORDER BY R;
The result was:
R C
------------
10 2
30 3
50 1
80 4
90 1
Conclusion:
Nowdays, using AI as a tool, you may improve your performance to the expert level and, may be, study something new...
P.S. Don't fool youself that AI can replace a developer (see the first answer of the chat), but together they can be much stornger than separatelly.
P.P.S. Another interesting solution gave us our colleague. She used an additional field to avoid using analytics function, and she reached the same result:
with T as
(
select 10 ID, 1 N
union all
select 11 ID, 1 N
union all
select 30 ID, 1 N
union all
select 31 ID, 1 N
union all
select 32 ID, 1 N
union all
select 50 ID, 1 N
union all
select 80 ID, 1 N
union all
select 81 ID, 1 N
union all
select 82 ID, 1 N
union all
select 83 ID, 1 N
union all
select 90 ID, 1 N
),
Groups AS (
SELECT
ID,
N,
ROW_NUMBER() OVER (ORDER BY ID) - ID AS GroupNumber
FROM
T
)
SELECT
MIN(ID) AS R,
SUM(N) AS C
FROM
Groups
GROUP BY
GroupNumber
ORDER BY
StartID;
Many years ago we implemented Akinator like engine purely within SQL Server.
Today we use exactly the same technique to implement vector database.
Please see our GitHub repo: vector-database.
Last few days we play with OpenAI API and out of pure interest have asked about few slogans for our team. As an input we fed info from "About us" page. And as one of the first slogans we've gotten the following slogan that catgh our eyes:
Excellence Through Experience: Nesterovsky Bros.
ChatGPT is not a bad copywriter at all...
While doing a migration of some big xslt 3 project into plain C# we run into a case that was not obvious to resolve.
Documents we process can be from a tiny to a moderate size. Being stored in xml they might take from virtually zero to, say, 10-20 MB.
In C# we may rewrite Xslt code virtually in one-to-one manner using standard features like XDocument, LINQ, regular classes, built-in collections, and so on. Clearly C# has a reacher repertoire, so task is easily solved unless you run into multiple opportunities to solve it.
The simplest solution is to use XDocument API to represent data at runtime, and use LINQ to query it. All features like xslt keys, templates, functions, xpath sequences, arrays and maps and primitive types are natuarally mapped into C# language and its APIs.
Taking several xslt transformations we could see that xslt to C# rewrite is rather straightforward and produces recognizable functional programs that have close C# source code size to their original Xslt. As a bonus C# lets you write code in asynchronous way, so C# wins in a runtime scalability, and in a design-time support.
But can you do it better in C#, especially when some data has well defined xml schemas?
The natural step, in our opinion, would be to produce C# plain object model from xml schema and use it for runtime processing.
Fortunately .NET has xml serialization attributes and tools to produce classes from xml schemas. With small efforts we have created a relevant class hierarchy for a rather big xml schema. XmlSerializer is used to convert object model to and from xml through XmlReader and XmlWriter. So, we get typed replacement of generic XDocument that still supports the same LINQ API over collections of objects, and takes less memory at runtime.
The next step would be to commit a simple test like:
-
read object model;
-
transform it;
-
write it back.
We have created such tests both for XDocument and for object model cases, and compared results from different perspectives.
Both solution produce very similar code, which is also similar to original xslt both in style and size.
Object model has static typing, which is much better to support.
But the most unexpected outcome is that object model was up to 20% slower due to serialization and deserialization even with pregenerated xmlserializer assemblies. Difference of transformation performance and memory consumption was so unnoticable that it can be neglected. These results were confirmed with multiple tests, with multiple cycles including heating up cycles.
Here we run into a case where static typing harms more than helps. Because of the nature of our processing pipeline, which is offline batch, this difference can be mapped into 10th of minutes or even more.
Thus in this particular case we decided to stay with runtime typing as a more performant way of processing in C#.
Xslt is oftentimes thought as a tool to take input xml, and run transformation to get html or some xml on output. Our use case is more complex, and is closer to a data mining of big data in batch. Our transformation pipelines often take hour or more to run even with SSD disks and with CPU cores fully loaded with work.
So, we're looking for performance opportunities, and xml vs json might be promising.
Here are our hypotheses:
- json is lighter than xml to serialize and deserialize;
- json stored as map(*), array(*) and other items() are ligher than node() at runtime, in particular subtree copy is zero cost in json;
- templates with match patterns are efficiently can be implemented with maps();
- there is incremental way forward from use of xml to use of json.
If it pays off we might be switching xml format to json all over, even though it is a development effort.
But to proceed we need to commit an experiment to measure processing speed of xml vs json in xslt.
Now our task is to find an isolated small representative sample to prove or reject our hypotheses.
Better to start off with some existing transformation, and change it from use of xml to json.
The question is whether there is such a candidate.
Couple of days ago, while integrating with someones C# library, we had to debug it, as something went wrong.
The code is big and obscure but for the integration purposes it's rather simple: you just create and call a class, that's all.
Yet, something just did not work. We had to prove that it's not our fault, as the other side is uncooperative and would not run common debug session to resolve the problem.
To simplify the matter as much as possible here is the case:
var input = ...
var x = new X();
var output = x.Execute(input);
You pass correct input, and get correct output. Simple, right? But it did not work!
So, we delved into the foreign code, and this is what we have seen:
class X: Y
{
public Output Execute(Input input)
{
return Perform(input);
}
protected override Output Run(Input input)
{
...
return output;
}
}
class Y: Z
{
...
}
class Z
{
protected Output Perform(Input input)
{
return Run(Input);
}
protected virtual Output Run(Input input)
{
return null;
}
}
Do you see, still flow is simple, right?
We call X.Execute(), it calls Z.Perform(), which in turn calls overriden X.Run() that returns the result.
But to our puzzlement we got null on output, as if Z.Run() was called!
We stepped through the code in debugger and confirmed that Z.Perform() calls Z.Run(), even though "this" instance is of type X.
How can it be? It's a nonsence! Yet, no overriden method was ever called.
No matter how much scrunity we applied to sources X and Z it just did not work.
We verified that the signature of X.Run() matches the signature of Z.Run(), so it overrides the method.
Then what do we see here?
And then enlightenment come! Yes, X.Run() overrides the method, but what method?
We looked closely at class Y, and bingo, we can see there following:
class Y: Z
{
...
protected virtual Output Run(Input input)
{
return null;
}
...
}
So, X.Run() overrides Y.Run() and not Z.Run()!
Per .NET Y.Run() and Z.Run() are two independant virtual methods, where Y.Run() in addition hides Z.Run().
IDE even issued a warning that it's better declare Y.Run() as:
protected new virtual Output Run(Input input)
{
return null;
}
So, someones code was plainly wrong: Y.Run() had to use override rather than virtual.
We won, right?
Well, it's hard to call it a win.
We spent a hour looking at someones ugly code just to prove we're still sane.
So, what is conclusion of this story?
We think here it is:
- be cautious while looking at someones code;
- look at IDE warnings, don't disregard them, and try to resolve all of them in your code base;
- try to write simple code.
Lately we work great deal of time with Azure's CosmosDB.
This is how it's defined:
"It is schema-agnostic, horizontally scalable, and generally classified as a NoSQL database."
This, unconfident in itself, quote below is clarified as:
"The SQL API lets clients create, update and delete containers and items. Items can be queried with a read-only, JSON-friendly SQL dialect."
To be honest this SQL API made us favor CosmosDB.
So, we started a development with CosmosDB as a data storage.
The next development ingredient we learned the hard way is to try to refrain from clever techniques.
The lesson we learned is simple: after you finish with a project, provided it's not a toy, you give it to people who will be supporting it. You should think about those future developers before you're going to insert some cleverness in you code.
With this common sense we selected EF Core as a library that will serve as an interface between C# and the database.
Initialy all went well until we needed to store a list of strings as a document property and found it's not possible.
Why? - was a naive question.
Answer puzzled us a lot - because string is not an "Entity" (what ever it means), and EF is about framework of entities.
You could argue with this argument as long as you like, it just does not work. It is especially bad if you need to store a class that you do not directly control e.g. structures returned from other services.
Next pothole with EF was when we tried to run an innocent query that joins the data from document: e.g. document contains items, and you want to query some items from some documents.
Guess what?
Right, EF Core does not support it.
Why?
Because!
Later we have found that many other constructs and functions that you easily use in SQL dialect of CosmosDB are not possible or supported in EF Core.
We were very upset with those crutches and came to a conclusion that EF Core harms more than helps when you work with CosmosDB.
We went on and looked at how you work directly with CosmosDB client, and have found that it has all features ready:
- you may give it SQL and bind parameters;
- you may convert result items to objects;
- you may create, delete, update and query data;
So, do we need EF Core?
We answered, no.
This does not mean we reject the value of EF Core but here our conclusion was that this API layer just complicated things instead making them simpler. It might be that EF Core for CosmosDB is not mature enough at this time.
Recently we have found that BinaryFormatter.Serialize and BinaryFormatter.Deserialize methods are marked as obsolete in .NET 5.0, and are declared dangerous:
The BinaryFormatter type is dangerous and is not recommended for data processing. Applications should stop using BinaryFormatter as soon as possible, even if they believe the data they're processing to be trustworthy. BinaryFormatter is insecure and can't be made secure.
See BinaryFormatter security guide for more details.
That guide along with its links go and expand on what problems BinaryFormatter poses. The schema of dangeous use cases, we have seen so far, is like that:
- two different sides communicate to each other;
- one side supplies input in BinaryFormatter's format;
- other side reads input using BinaryFormatter and instantiates classes.
A threat arises when two sides cannot trust to each other or cannot establish trusted communication chanel. In these cases malign input can be supplied to a side reading the data, which might lead to unexpected code execution, deny of service, data exposure and to other bad consequences.
Arguing like this, today's maintainers of .NET concluded that it's better to tear down BinaryFormatter and similar APIs out of the framework.
Note that they don't claim BinaryFormatter itself, or Reflection API that it uses, as a core of the problem. They blame on communication.
Spelling out clearly what are concerns could help to everyone to better understand how to address it.
In the area of security of communication there are a lot of ready solutions like:
- use signature to avoid tampering the data;
- use encription to avoid spying the data;
- use access rights to avoid even access to the data;
- use secure communication channels.
We can surely state that without applying these solutions no other serialization format is reliable and is subject of the same vulnerabilities.
After all it looked like an attempt to throw out the baby with the bath water. The good news is that thankfully to now modular structure of .NET runtime we're able to access binary serialization library, which are (and will be) available on nugets repositories. So, it's futile effort to erase this usefull API.
Earlier we wrote that recently we've gotten few tasks related to Machine Learning.
The prerequisites to such task is to collect and prepare the input data.
Usually the required data is scattered across public sites, some of them are in plain text format (or close to it),
but others are accessible as output of public applications. To obtain the required data for such sites
you have to navigate thourgh pages, which often requires keeping state between navigations.
In order to implement this task you need some kind of crawler/scraper of the websites.
Fortunately, there are a lot of frameworks, libraries and tools in C# (and in other languages too) that allow to do this (visit this or this site to see most popular of them), for example:
- ScrapySharp
- ABot
- HtmlAgilityPack
- DotnetSpider
There are pros and cons of using these libraries. Most crucial cons is a lack of support of rich UI based on heavy client-side scripts and client-side state support.
Since not all such libraries implement fully browser emulation and even more, some of them do not support Javascript execution.
So, they suit for gathering information from simple web pages, but no library allows to easy navigate to some page of a web application
that keeps rich client-side state. Even best of them, like ScrapySharp, require heavy programming to achieve the result.
Then, suddenly, we've recalled that already for several years we're using Selenium and web drivers to automate web tests for AngularJS/Angular projects.
After short discussion we came to conclusion that there is no big difference between testing web application and collecting data, since one of testing stages is collecting of actual results (data)
from the tested page, and usually our tests consist of chains of actions performed on consequently visited pages.
This way we came to idea to use WebDriver API implemented by Selenium project.
There are implementations of this API in different languages, and in C# too.
Using WebDriver we easily implement cumbersome navigation of a complex web application and can collect required data. Moreover, it allows to run WebDriver in screenless mode.
Some of its features allow to create a snapshots of virtual screen and store HTML sources that would resulted of Javascript execution. These features are very
useful during run-time troubleshooting. To create a complex web application navigation we need only a bit more knowledge than usual web application's user - we need
to identify somehow pages' elements for example by CSS selectors or by id of HTML elements (as we do this for tests). All the rest, like coockies, view state (if any),
value of hidden fields, some Javascript events will be transparent in this case.
Although one may say that approach with Selenium is rather fat, it's ought to mention that it is rather scalable.
You may either to run several threads with different WebDriver instances in each thread or run several processes simultaneously.
However, beside pros there are cons in the solution with Selenium. They will appear when you'll decide to publish it, e.g. to Azure environment.
Take a note that approach with Selenium requires a browser on the server, there is also a problem with Azure itself, as it's Microsoft's platform
and Selenium is a product of their main competitor Google... So, some issues aren't techincals. The only possible solution is to use PaaS approach
instead of SaaS, but in this case you have to support everything by yourself...
The other problem is that if your application will implement rather aggressive crawling, so either servers where you gather data or your own host might ban it.
So, be gentle, play nice, and implement delays between requests.
Also, take into account that when you're implementing any crawler some problems may appear on law level, since not all web sites allow pull anything you want.
Many sites use terms & conditions that defines rules for the site users (that you cralwer should follow to), otherwise legal actions may
be used against them (or their owners in case of crawler). There is
very interesting article that describes many
pitfalls when you implement your own crawler.
To summarize everything we told early, the Selenium project could be used in many scenarios, and one of them is to create a powerful crawler.
While doing Cool:GEN migratiotions to Java and C# we produce rather big Angular applications.
Everything is fine: server runs a REST APIs, and client is an Angular application with components per each window, dialog or screen. The only problem is with the word big.
We observe that enterprises that used Cool:GEN to develop their workflow come to migration stage with applications containing thousands of windows. In simple cases, after assessment, clients are able to split their monolith workflow into a set of independent applications. But even then we are dealing with Angular applications containing hundreds to many thousands components.
Now, lets look at Angular world. Best practices advice to (and actually almost force you to) use Ahead Of Time, Ivy compilation of all components and their templates.
Naive attempt to build such monolith Angular application will most surely fail. Angular uses nodejs for build, and chances are close to 100% of nodejs to run out of memory during the ng build.
You may fight and throw at it a capable build machine with 16 or better with 32GB of RAM, and instruct nodejs to use all of it.
Well, it's rather poor and extensive way of dealing with scale problems but it works.
Next hurdle you run into is time. We know it might take days just to build it.
You may ask why?
Well, angular is doing its best to validate templates!
Unfortunately the only viable workaround is to switch this nice feature off for such a big project.
With such setup you're able to build angular project in just 20-30 minutes!
Well, this is a big progress if you compare complete failure vs something that at least passes the build.
But what's next?
Sure, there are next problems:
- scripts both development and production are of nonsense size: like several dozen megabytes for production, and some even higher number for development.
ng serve eats even more memory and builds even longer making nightmare out of development and support of such an application;- startup of such application, if it will start at all, is very slow.
So, what can be done? How can we create a manageable Angular application containing that many components?
Angular advices Lazy-loading feature modules.
That's reasonable advice!
We can create coarse grained modules containing subsets of components or fine grained modules containing one component.
So, does it help?
Yes, but it does not solve all problems:
ng build and ng serve are still very slow;- build produces multiple small scripts that are loaded on demand, so at least application works in browser.
Yet, other important problem is still there: we have multiple severly separated server REST controllers with components that represent them.
On the server side we have Java or C# REST controllers hosting business logic. They are separated per multiple projects probably managed by separate teams, and probably kept in separate GITs (or whatever). On the client side we have a fat angular project storing everything kept in single source repository.
This is not going to work from management perspective.
So the next step is try to split fat Angular project into multiple small projects. So, let's say we shall have 100 small angular libraries combinded by master project.
This is not going to work either due to nature of npm projects, as it will requre terabytes of cloned node_modules folders for each library, and many hours to build each of them.
It seems there is a room for improvments in npm area. There is no point to make dedicated copies of node_modules. It's much easier to have a local cache of artifacts.
So, what is the direction? How to create big angular project after all?
What we have here is:
- a big enterprise level application;
- it is modular but modules must work together to form desired workflow;
- different modules are supported by different teams (both server and client side);
- client Angular components correspond to REST controllers on the server.
- all pages use the same styles and the same set of UI controls;
Looking from this perspective all development can be seen as:
- development and support of unified styles and ui components that must be reused through the application;
- development of server side and REST controllers that implement business logic;
- development of templates of components (note that components themselves do nothing except expose their templates).
Studying this design suggests important and independent role of templates just like it is in AngularJS!
In contrast Angular templates are only a tool used by components. It's not obvious how to use thousands of templates without first building thousands components; neither it's obvious how to dynamically host those templates (routes do not help here).
Though not obvious it's still possible to do it though it requires use a bit lower level API than tutorials suggest. Ingredients are:
- use of Just In Time (in contrast to Ahead Of Time) compilation, and use View Enginev (in contrast to Ivy);
- use ViewContainerRef to host components dynamically;
- Dynamic components and modules that you can create on demand using templates loaded e.g. through
HttpClient.
To make things short we shall show the example of dynamic components in next article.
Here we shall emphasize that such design allows us to create small angular application that builds under 20 seconds with component templates served along with the REST controllers, and stored in the same Git.
So, if you say have a server subproject exposing REST controller say in the form: api/area/MyComponent then its template may be exposed as resource: page/area/MyComponent. Templates are loaded and compiled on demand at runtime thus making application light. At the same time templates may be cached in browser cache thus reducing number of roundtrips to the server.
 Eventually we've started to deal with tasks that required machine learning. Thus, the good tutorial for ML.NET was required and we had found this one that goes along with good simple codesamples. Thanks to Jeff Prosise. Hope this may be helpfull to you too. Eventually we've started to deal with tasks that required machine learning. Thus, the good tutorial for ML.NET was required and we had found this one that goes along with good simple codesamples. Thanks to Jeff Prosise. Hope this may be helpfull to you too.
Recently our colleague turned to us and asked to help to deal with some complex query.
It has turned out that the complex part was to understand what he wants to achieve.
After listening to him we have forumulated the task in our words and have confirmed that that is what he wants.
So, that's the task in our formulation:
- Assume you have events.
- Each event acts upon one or more accounts.
- Find all events that act on the same set of accounts.
- Note we deal with mutiple millions of events and accounts.
Data is defined like this:
create table dbo.Event
(
EventID bigint not null,
AccountID varchar(18) not null,
primary key(EventID, AccountID)
);
Requested query turned out to be very simple, yet, not as simple as one would think to account big amout of data:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
count(*) Items,
checksum_agg(checksum(AccountID)) Hash
from
D
group by
EventID
)
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items = S2.Items and
S1.Hash = S2.Hash and
not exists
(
select AccountID from D where EventID = S1.EventID
except
select AccountID from D where EventID = S2.EventID
);
The idea is to:
- calculate a hash derived from list of accounts for each group;
- join groups with the same hash;
- verify that matched groups fit perfectly.
Even simpler solution that does not use hashes is not scaleable, as it's performance is slower than O(N^2), where N - is a number of events. It has unacceptable time with N ~1e4, nothing to say about N ~1e7.
At this point our colleague was already satisfied, as he got result in couple of minutes for a task that he could not even formalize as SQL.
But we felt it could be even better.
We looked at statistics:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
count(*) Items
from
D
group by
EventID
)
select
Items, count(*) EventCount
from
S
group by
Items
order by
EventCount desc;
and have seen that most of the events, about 90%, deal with single account,
and all other with two and more (some of them act upon big number of accounts).
The nature of the dataset gave us a hint of more verbose but more fast query:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
min(AccountID) AccountID,
count(*) Items,
checksum_agg(checksum(AccountID)) Hash
from
D
group by
EventID
)
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items = 1 and
S2.Items = 1 and
S1.AccountID = S2.AccountID
union all
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items > 1 and
S2.Items > 1 and
S1.Items = S2.Items and
S1.Hash = S2.Hash and
not exists
(
select AccountID from D where EventID = S1.EventID
except
select AccountID from D where EventID = S2.EventID
);
This query produced results in twenty seconds instead of couple of minutes for a dataset with ~1e7 rows.
Not sure what is use of our Xslt Graph exercises but what we are sure with is that it stresses different parts of Saxon Xslt engine and helps to find and resolve different bugs.
While implementing biconnected components algorithm we incidently run into internal error with Saxon 10.1 with rather simple xslt:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:array="http://www.w3.org/2005/xpath-functions/array"
exclude-result-prefixes="xs array">
<xsl:template match="/">
<xsl:sequence select="
array:fold-left
(
[8, 9],
(),
function($first as item(), $second as item())
{
min(($first, $second))
}
)"/>
</xsl:template>
</xsl:stylesheet>
More detail can be found at Saxon's issue tracker: Bug #4578: NullPointerException when array:fold-left|right $zero argument is an empty sequence.
Bug is promptly resolved.
|