As we wrote some time ago, we started to use AI and ML APIs in our applications, but this time we've tried to use Bing chat as a tool.
The initial task was to collect sequences of integer numbers and return a list of pairs integers where the first number is a range's start and the second one is a count of values in the range. For example, for sequence 1, 2, 3, 5, 8, 9 we'd like to get the following results:
1, 3
5, 1
8, 2
We both started to solve this issue. My brother started to play with SSMS using his deep knowledges in SQL and analytic functions, whereas me started to play with Bing chat. Looking ahead, I can state that we both solved the issue using almost the same SQL statement almost in the same time.
Here are my prompts and Bing's answers:
- Prompt:
-
Act as database analyst and software engineer. Given the table (T) with a numeric field (N), which values are orderd ranges of integers. In a range each next value is greater than previous one on 1. When value differs from the previous one more than on 1 then in belongs to another range. Generate select statement that returns rows with two fields. The first field (R) is a number from which a range starts and the second field (C) is count elements of that range:
- Answer:
-
Sure, I can help with that. Here's a SQL query that should do the trick. This query uses a self-join to
identify the start of each range, and then groups by the start of the range to count the number of elements.
```sql
SELECT
start_of_range AS R,
COUNT(*) AS C
FROM (
SELECT
N,
N - ROW_NUMBER() OVER (ORDER BY N) AS start_of_range
FROM T
) subquery
GROUP BY start_of_range
ORDER BY start_of_range;
```
In this query, `start_of_range` is calculated as the difference between the current value of `N` and its row
number (when ordered by `N`). This difference will be the same for all `N` in the same range. Then we group
by `start_of_range` to get the count of elements in each range. The outer query selects the start of each
range (`R`) and the count of elements in that range (`C`).
-
Me, scratching the head, hmmm...
-
Question:
-
This is a bit incorrect SQL select. For example for values 1, 2, 3, 5, 8, 9 I'd like to get the following results:
1, 3
5, 1
8, 2
What a SQL select shall I use to get such results?
- Answer:
-
I apologize for the confusion earlier. You're right, the previous query doesn't handle the scenario you've described correctly.
Here's a corrected SQL query that should give you the desired output. This query uses a window function to compare each row with the previous one and identify the start of a new range. Then it groups by the start of the range to count the elements.
```sql
WITH ranges AS (
SELECT
N,
CASE
WHEN N - LAG(N, 1, N) OVER (ORDER BY N) > 1 THEN 1
ELSE 0
END AS is_start_of_range
FROM T
),
range_groups AS (
SELECT
N,
SUM(is_start_of_range) OVER (ORDER BY N) AS range_group
FROM ranges
)
SELECT
MIN(N) AS R,
COUNT(*) AS C
FROM range_groups
GROUP BY range_group
ORDER BY R;
```
In this query, `is_start_of_range` is a flag that indicates the start of a new range (when the difference between the current and previous `N` is more than 1). `range_group` is a running total of `is_start_of_range` that serves as a unique identifier for each range. The outer query then groups by `range_group` to get the start (`R`) and count (`C`) of each range. I hope this helps! Let me know if you have any other questions.
That answer more satisfied me, and I've checked the following example:
with T as
(
select 10 N
union all
select 11 N
union all
select 30 N
union all
select 31 N
union all
select 32 N
union all
select 50 N
union all
select 80 N
union all
select 81 N
union all
select 82 N
union all
select 83 N
union all
select 90 N
),
ranges AS (
SELECT
N,
CASE
WHEN N - LAG(N, 1, N) OVER (ORDER BY N) > 1 THEN 1
ELSE 0
END AS is_start_of_range
FROM T
),
range_groups AS (
SELECT
N,
SUM(is_start_of_range) OVER (ORDER BY N) AS range_group
FROM ranges
)
SELECT
MIN(N) AS R,
COUNT(*) AS C
FROM range_groups
GROUP BY range_group
ORDER BY R;
The result was:
R C
------------
10 2
30 3
50 1
80 4
90 1
Conclusion:
Nowdays, using AI as a tool, you may improve your performance to the expert level and, may be, study something new...
P.S. Don't fool youself that AI can replace a developer (see the first answer of the chat), but together they can be much stornger than separatelly.
P.P.S. Another interesting solution gave us our colleague. She used an additional field to avoid using analytics function, and she reached the same result:
with T as
(
select 10 ID, 1 N
union all
select 11 ID, 1 N
union all
select 30 ID, 1 N
union all
select 31 ID, 1 N
union all
select 32 ID, 1 N
union all
select 50 ID, 1 N
union all
select 80 ID, 1 N
union all
select 81 ID, 1 N
union all
select 82 ID, 1 N
union all
select 83 ID, 1 N
union all
select 90 ID, 1 N
),
Groups AS (
SELECT
ID,
N,
ROW_NUMBER() OVER (ORDER BY ID) - ID AS GroupNumber
FROM
T
)
SELECT
MIN(ID) AS R,
SUM(N) AS C
FROM
Groups
GROUP BY
GroupNumber
ORDER BY
StartID;
Many years ago we implemented Akinator like engine purely within SQL Server.
Today we use exactly the same technique to implement vector database.
Please see our GitHub repo: vector-database.
Recently our colleague turned to us and asked to help to deal with some complex query.
It has turned out that the complex part was to understand what he wants to achieve.
After listening to him we have forumulated the task in our words and have confirmed that that is what he wants.
So, that's the task in our formulation:
- Assume you have events.
- Each event acts upon one or more accounts.
- Find all events that act on the same set of accounts.
- Note we deal with mutiple millions of events and accounts.
Data is defined like this:
create table dbo.Event
(
EventID bigint not null,
AccountID varchar(18) not null,
primary key(EventID, AccountID)
);
Requested query turned out to be very simple, yet, not as simple as one would think to account big amout of data:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
count(*) Items,
checksum_agg(checksum(AccountID)) Hash
from
D
group by
EventID
)
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items = S2.Items and
S1.Hash = S2.Hash and
not exists
(
select AccountID from D where EventID = S1.EventID
except
select AccountID from D where EventID = S2.EventID
);
The idea is to:
- calculate a hash derived from list of accounts for each group;
- join groups with the same hash;
- verify that matched groups fit perfectly.
Even simpler solution that does not use hashes is not scaleable, as it's performance is slower than O(N^2), where N - is a number of events. It has unacceptable time with N ~1e4, nothing to say about N ~1e7.
At this point our colleague was already satisfied, as he got result in couple of minutes for a task that he could not even formalize as SQL.
But we felt it could be even better.
We looked at statistics:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
count(*) Items
from
D
group by
EventID
)
select
Items, count(*) EventCount
from
S
group by
Items
order by
EventCount desc;
and have seen that most of the events, about 90%, deal with single account,
and all other with two and more (some of them act upon big number of accounts).
The nature of the dataset gave us a hint of more verbose but more fast query:
with D as
(
select * from dbo.Event
),
S as
(
select
EventID,
min(AccountID) AccountID,
count(*) Items,
checksum_agg(checksum(AccountID)) Hash
from
D
group by
EventID
)
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items = 1 and
S2.Items = 1 and
S1.AccountID = S2.AccountID
union all
select
S1.EventID, S2.EventID
from
S S1
inner join
S S2
on
S1.EventID < S2.EventID and
S1.Items > 1 and
S2.Items > 1 and
S1.Items = S2.Items and
S1.Hash = S2.Hash and
not exists
(
select AccountID from D where EventID = S1.EventID
except
select AccountID from D where EventID = S2.EventID
);
This query produced results in twenty seconds instead of couple of minutes for a dataset with ~1e7 rows.
We often deal with different SQL DBs, and in particular DB2, Oracle, and SQL Server, and this is what we have found lately.
Our client has reported a problem with SQL insert into the DB2:
- subject table has a small number of columns, but large number of rows;
- insert should attempt to insert a row but tolerate the duplicate.
The prototype table is like this:
create table Link(FromID int, ToID int, primary key(FromID, ToID));
DB2 SQL insert is like this:
insert into Link(FromID, ToID)
values(1, 2)
except
select FromID, ToID from Link;
The idea is to have empty row set to insert if there is a duplicate.
SQL Server variant looks like this:
insert into Link(FromID, ToID)
select 1, 2
except
select FromID, ToID from Link;
Client reported ridiculously slow performance of this SQL, due to table scan to calculate results of except operator.
Out of interest we performed the same experiment with SQL Server, and found the execution plan is optimal, and index seek is used to check duplicates. See:
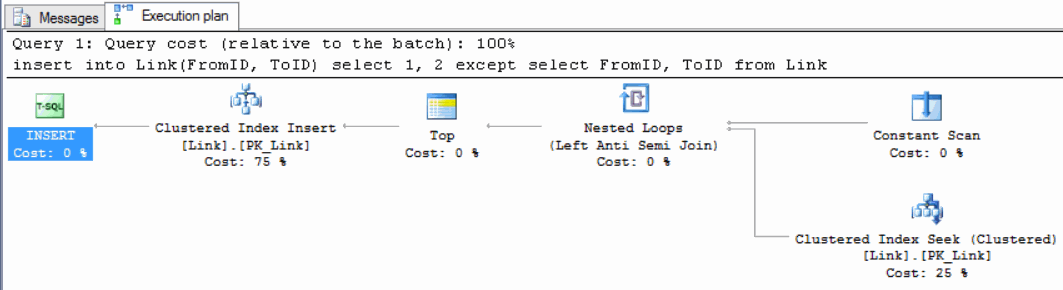
The only reasonable way of dealing with such DB2's peculiarity, except trying to insert and handle duplicate exception, was to qualify select with where clause:
insert into Link(FromID, ToID)
values(1, 2)
except
select FromID, ToID from Link where FromID = 1 and ToID = 2;
We think DB2 could do better.
A collegue has approached to us with a question on how Akinator engine may work.
To our shame we have never heard about this amazing game before. To fill the gap we have immediately started to play it, and have identified it as a Troubleshooting solver.
It took us a couple of minutes to come up with a brilliant solution: "We just need to google and find the engine in the internet". 
Unfortunately, this led to nowhere, as no Akinator itself is open sourced, and no other good quality open source solutions are available.
After another hour we have got two more ideas:
- The task should fit into SQL;
- The task is a good candidate for a neural network.
In fact, the first might be required to teach the second, so we have decided to formalize the problem in terms of SQL, while still keeping in mind a neural network.
With this goal we have created a GitHub project. Please see the algorithm and its implementation at github.com/nesterovsky-bros/KB.
These are initial positions for this writing:
- SQL Server allows to execute dynamic SQL.
- Dynamic SQL is useful and often unavoidable, e.g. when you have to filter or order data in a way that you cannot code efficiently in advance.
- Dynamic SQL has proven to be a dangerous area, as with improper use it can open hole in a security.
In general nothing stops you from building and then excuting of SQL string. Our goal, however, is to define rules that make work with dynamic SQL is more managable and verifiable.
Here we outline these rules, and then give some examples and tips.
Rule #1. Isolate dynamic SQL
Put all logic related to building of dynamic SQL into a separate function.
We usually define a separate scheme Dynamic, and define functions like Dynamic.GetSQL_XXX(params).
This makes it simple to perform code review.
Rule #2. Xml as parameters
Use xml type to pass parameters to a function that builds dynamic SQL.
In many cases dynamic SQL depends on variable number of parameters (like a list of values to check against).
Xml fits here to represent structured information.
On a client (e.g. in C# or java) you can define a class with all parameters, populate an instance and serialize it to an xml.
Rule #3. XQuery as template language
Use XQuery to define SQL template and to generate SQL tree from the input parameters.
Here is an example of such XQuery:
@data.query('
<sql>
select
T.*
from
Data.Ticket T
where
{
for $ticketID in data/ticketID return
<sql>(T.TicketID = <int>{$ticketID}</int>) and </sql>
}
(1 = 1)
</sql>')
You can see that output is an xml
with sql element to represent literal SQL, and int element to represent integer literal.
In fact whole output schema can be defined like this:
<xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="sql"/>
<xs:element name="name"/>
<xs:element name="string" nillable="true"/>
<xs:element name="int" nillable="true"/>
<xs:element name="decimal" nillable="true"/>
<xs:element name="date" nillable="true"/>
<xs:element name="time" nillable="true"/>
<xs:element name="datetime" nillable="true"/>
</xs:schema>
where sql is to represent literal content, name to represent a name, and other elements to represent different literal values.
Rule #4. Escape literals
Use function Dynamic.ToSQL(@template) to build final SQL text.
Here we quote the definition:
-- Builds a text of SQL function for an sql template.
create function Dynamic.ToSQL
(
-- SQL template.
@template xml
)
returns nvarchar(max)
with returns null on null input
as
begin
return
(
select
case
when N.Node.exist('*[xs:boolean(@xsi:nil)]') = 1 then
'null'
when N.Node.exist('self::int') = 1 then
isnull(N.Node.value('xs:int(.)', 'nvarchar(max)'), '# int #')
when N.Node.exist('self::string') = 1 then
'N''' +
replace
(
N.Node.value('.', 'nvarchar(max)'),
'''',
''''''
) +
''''
when N.Node.exist('self::name') = 1 then
isnull
(
quotename(N.Node.value('.', 'nvarchar(128)'), '['),
'# name #'
)
when N.Node.exist('self::datetime') = 1 then
isnull
(
'convert(datetime2, ''' +
N.Node.value('xs:dateTime(.)', 'nvarchar(128)') +
''', 126)',
'# datetime #'
)
when N.Node.exist('self::date') = 1 then
isnull
(
'convert(date, ''' +
N.Node.value('xs:date(.)', 'nvarchar(128)') +
''', 126)',
'# date #'
)
when N.Node.exist('self::time') = 1 then
isnull
(
'convert(time, ''' +
N.Node.value('xs:time(.)', 'nvarchar(128)') +
''', 114)',
'# time #'
)
when N.Node.exist('self::decimal') = 1 then
isnull
(
N.Node.value('xs:decimal(.)', 'nvarchar(128)'),
'# decimal #'
)
when N.Node.exist('self::*') = 1 then
'# invalid template #'
else
N.Node.value('.', 'nvarchar(max)')
end
from
@template.nodes('//sql/node()[not(self::sql)]') N(Node)
for xml path(''), type
).value('.', 'nvarchar(max)');
end;
Now, we want to stress that this function plays an important role in prevention of the SQL injection, as it escapes literals from the SQL tree.
Rule #5 (optional). Collect data
Use SQL to collect additional data required to build dynamic SQL. Here is an example of how we get a Ticket by StatusID, while on input we receive a StatusName:
create function Dynamic.GetSQL_GetTicketByStatus(@data xml)
returns nvarchar(max)
as
begin
set @data =
(
select
@data,
(
select
T.StatusID
from
@data.nodes('/data/status') N(Node)
inner join
Metadata.Status T
on
T.StatusName = Node.value('.', 'nvarchar(128)')
for xml auto, type, elements
)
for xml path('')
);
return Dynamic.ToSQL
(
@data.query
('
<sql>
select
T.*
from
Data.Ticket T
where
T.Status in ({ for $status in /T/StatusID return <sql><int>{$status}</int>,</sql> } null)
</sql>
')
);
end;
Notice code in red that collects some more data before calling XQuery.
Rule #6. Execute
The final step is to call dynamic SQL.
This is done like this:
-- build
declare @sql nvarchar(max) = Dynamic.GetSQL_GetTicket(@data);
-- execute
execute sp_executesql
@sql
-- {, N'@parameter_name data_type [ OUT | OUTPUT ][ ,...n ]' }
-- { , [ @param1 = ] 'value1' [ ,...n ] }
with result sets
(
(
TicketID int not null,
CreatedAt datetime2 not null,
Summary nvarchar(256) null,
Status int,
Severity int,
DeadLineAt datetime2 null
)
);
Notice that the use of dynamic SQL does not prevent static parameters.
Notice also that with result sets clause is used to specify output.
Example. Tickets system
Let's assume you're dealing with a tickets system (like Bugzilla), and you have a table Data.Ticket to describe tickets. Assume that DDL for this table is like this:
create table Data.Ticket
(
TicketID bigint not null primary key,
CreatedAt datetime2 not null,
Summary nvarchar(128) null,
Status int not null,
UpdatedAt datetime2(7) not null
)
Suppose you have to build C# code to search different tickets, where Entity Framework is used to access the database.
Search should be done by a range of CreatedAt, a range of UpdatedAt, Summary, or by different Status values. It should be possible to order results in different ways.
We start out solution from the C# and define classes for a request:
public enum Direction
{
Asc,
Desc
}
public struct Order
{
public string Field { get; set; }
public Direction Direction {get; set; }
}
public class DateRange
{
public DateTime? From { get; set; }
// This property is to omit From element if value is null.
// See rules for xml serialization.
public bool FromSpecified
{
get { return From != null; }
}
public DateTime? To { get; set; }
public bool ToSpecified
{
get { return To != null; }
}
}
public class TicketsRequest
{
public DateRange CreatedAt { get; set; }
public string Summary { get; set; }
public DateRange UpdatedAt { get; set; }
[XmlElement]
public Order[] Order { get; set; }
[XmlElement]
public int[] Status { get; set; }
}
Notice that we're going to use XmlSerializer to convert request to xml and then to pass parameter into EF's model. Here is utility method to perform such conversion:
public static string ToXmlString<T>(T value)
{
if (value == null)
{
return null;
}
var serializer = new XmlSerializer(typeof(T));
var builder = new StringBuilder();
var writer = XmlWriter.Create(
builder,
new XmlWriterSettings
{
OmitXmlDeclaration = true,
Indent = false
});
serializer.Serialize(writer, value);
writer.Flush();
return builder.ToString();
}
Now we proceed to the database and define a procedure that runs the search:
-- Gets tickets.
create procedure Data.GetTickets
(
-- A query parameters.
@params xml
)
as
begin
set nocount on;
-- This is for EF to guess type of result.
if (1 = 0)
begin
select
TicketID,
CreatedAt,
Summary,
Status,
UpdatedAt
from
Data.Ticket;
end;
declare @sql nvarchar(max) = Dynamic.GetSQL_GetTickets(@params);
execute sp_executesql @sql
with result sets
(
(
TicketID int not null,
CreatedAt datetime2 not null,
Summary nvarchar(256) null,
Status int,
UpdatedAt datetime2 null
)
);
end;
Switch back to C#, import the Data.GetTickets into the EF model, and create a search method:
public IEnumerable<Ticket> GetTickets(TicketsRequest request)
{
var model = new Model();
return model.GetTickets(ToXmlString(request));
}
The last ingredient is Dynamic.GetSQL_GetTickets() function.
create function Dynamic.GetSQL_GetTickets(@data xml)
returns nvarchar(max)
as
begin
return Dynamic.ToSQL
(
@data.query('
<sql>
select
T.TicketID,
T.CreatedAt,
T.Summary,
T.Status,
T.UpdatedAt
from
Data.Ticket T
where
{
for $range in */CreatedAt return
(
for $date in $range/From return
<sql>
(T.CreatedAt >= <datetime>{$date}</datetime>) and
</sql>,
for $date in $range/To return
<sql>
(<datetime>{$date}</datetime> > T.CreatedAt) and
</sql>
),
for $range in */UpdatedAt return
(
for $date in $range/From return
<sql>
(T.UpdatedAt >= <datetime>{$date}</datetime>) and
</sql>,
for $date in $range/To return
<sql>
(<datetime>{$date}</datetime> > T.UpdatedAt) and
</sql>
),
for $summary in */Summary return
<sql>
(T.Summary like <string>{$summary}</string>) and
</sql>,
if (*/Status) then
<sql>
T.Status in
({
for $status in */Status return
<sql><int>{$status}</int>, </sql>
} null) and
</sql>
else ()
}
(1 = 1)
order by
{
for $order in
*/Order
[
Field = ("TicketID", "CreatedAt", "Summary", "UpdatedAt", "Status")
]
return
<sql>
<name>{$order/Field}</name>
{" desc"[$order[Direction = "Desc"]]},
</sql>
}
(select null)
</sql>
')
);
end;
SQL text from Dynamic.GetSQL_GetTickets()
Consider now SQL text produced by this function. For an input:
<TicketsRequest>
<CreatedAt>
<From>2014-01-01T00:00:00</From>
</CreatedAt>
<Summary>hello%</Summary>
<Order>
<Field>Status</Field>
<Direction>Desc</Direction>
</Order>
<Status>1</Status>
<Status>3</Status>
</TicketsRequest>
the output is:
select
T.TicketID,
T.CreatedAt,
T.Summary,
T.Status,
T.UpdatedAt
from
Data.Ticket T
where
(T.CreatedAt >= convert(datetime2, '2014-01-01T00:00:00', 126)) and
(T.Summary like N'hello%') and
T.Status in
(1, 3, null) and
(1 = 1)
order by
[Status] desc,
(select null)
Though the text is not formatted as we would like, it's perfectly valid SQL.
Tips for building XQuery templates
What is called XQuery in SQL Server is in fact a very limited subset of XQuery 1.0. Microsoft clearly states this fact. What is trivial in XQuery is often impossible or ugly in XQuery of SQL Server.
Nevertheless XQuery in SQL Server works rather well as SQL template language. To make it most efficient, however, you should learn several tips.
Tip #1. Where clause
In template you might want to build a where clause:
<sql>
select
...
where
{
if (...) then
<sql>...</sql>
else ()
}
</sql>
and it might happen that for a certain input a condition under where might collapse, and you will be left with where keyword without a real condition, which is wrong. A simple work around is to always add some true condition under ther where like this:
<sql>
select
...
where
{
if (...) then
<sql>... and </sql>
else ()
} (1 = 1)
</sql>
Tip #2. "in" expression
If you want to generate "in" expression like this:
value in (item1, item2,...)
then you might find that it's much easier generate equivalent a code like this:
value in (item1, item2,..., null).
Here is a XQuery to generate such template:
value in
({
for $item in ... return
<sql><int>{$item}</int>, </sql>
} null) and
Tip #3. Order by
You can conclude an order by clause built from a data with a dummy expression like this:
order by
{
for $item in ... return
<sql>
<name>{$item/Field}</name>
{" desc"[$item/Direction = "Desc"]},
</sql>
} (select null)
Alternatively you can use first column from a clustered index.
Tip #4. Group by
In a group by clause we cannot introduce terminator expression as it was with order by, so a code is a less trivial:
{
let $items := ... return
if ($items) then
<sql>
group by <name>{$items[1]}</name>
{
for $item in $items[position() > 1] return
<sql>, <name>{$item}</name></sql>
}
</sql>
else ()
}
In fact similar logic may work with order by.
Tip #5. Escape literals
It's crusial not to introduce SQL injection while building SQL. Thus use:
<int>{...}</int> - for literal int;
<decimal>{...}</decimal> - for literal decimal;
<string>{...}</string> - for literal string;
<datetime>{...}</datetime> - for literal datetime2;
<date>{...}</date> - for literal date;
<time>{...}</time> - for literal time;
<name>{...}</name> - for a name to quote.
Note that you can use xsi:nil, so
<int xsi:nil="true"/> means null.
If you generate a field name from an input data then it worth to validate it against a list of available names.
Tip #6. Validate input.
It worth to define xml schema for an input xml, and to validate parameters against it.
This makes code more secure, and also adds a documentation.
Tip #7. Don't abuse dynamic SQL
There are not too many cases when you need a dynamic SQL. Usually SQL engine knows how to build a good execution plan. If your query contains optional conditions then you can write it a way that SQL Server can optimize, e.g.:
select
*
from
T
where
((@name is null) or (Name = @name)) and
((@date is null) or (Date = @date))
option(recompile)
Till recently we were living in simple world of string comparisons in SQL style,
and now everything has changed.
From the university years we knew that strings in SQL are compared by first
trimming traling spaces, and then comparing in C style.
Well, the picture was a little more complex, as collations were involved
(national, case sensivity), and as different SQL vendors implemented it
differently.
Next,
we're dealing with programs converted from COBOL, which we originally
thought follow SQL rules when strings are compared.
Here is where the problem has started.
Once we have found that java program has branched differently than original
COBOL, and the reason was that the COBOL and java compared two strings
differently:
- COBOL:
"A\n" < "A";
- Java:
"A\n" > "A"
We have looked into
COBOL Language Reference and found the rules:
- Operands of equal size
- Characters in corresponding positions of the two operands are compared,
beginning with the leftmost character and continuing through the rightmost
character.
If all pairs of characters through the last pair test as equal, the operands are
considered as equal.
If a pair of unequal characters is encountered, the characters are tested to
determine their relative positions in the collating sequence. The operand that
contains the character higher in the sequence is considered the greater operand.
- Operands of unequal size
- If the operands are of unequal size, the comparison is made as though the
shorter operand were extended to the right with enough spaces to make the
operands equal in size.
You can see that strings must not be trimmed but padded with spaces
to the longer string, and only then they are compared. This subtle difference
has significant impact for characters below the space.
So, here we've found that COBOL and SQL comparisons are different.
But then we have questioned how really SQL beheaves?
We've tested comparisons in SQL Server and DB2, and have seen that our
understanding of SQL comparison holds. It works as if trimming spaces, and then
comparing.
But again we have looked into SQL-92 definition, and that's what we see there:
8.2 <comparison predicate>
3) The comparison of two character strings is determined as follows:
a) If the length
in characters of X is not equal to the length
in
characters of Y, then the shorter string is effectively
replaced, for the purposes of comparison, with a copy of
itself that has been extended to the length of the longer
string by concatenation on the right of one or more pad characters, where the pad character is chosen based on CS. If
CS
has the NO PAD attribute, then the pad character is an
implementation-dependent character different from any character
in the character set of X and Y that collates less
than
any string under CS. Otherwise, the pad character is a
<space>.
So, what we see is that SQL-92 rules are very close to COBOL rules, but then we
reach the question: how come that at least SQL Server and DB2 implement string
comparison differently than SQL-92 dictates?
Update: we have found that both SQL Server and DB2 have their string collation defined in a way that <space> is less than any other character.
So the following is always true: '[' + char(13) + ']' > '[ ]'.
Two monthes ago we have started
a process of changing column type from smallint to int in a big database.
This was splitted in two phases:
- Change tables and internal stored procedures and functions.
- Change interface API and update all clients.
The first part took almost two monthes to complete. Please read earlier post about
the technique we have selected for the implementation. In total we have transferred
about 15 billion rows. During this time database was online.
The second part was short but the problem was that we did not control all clients,
so could not arbitrary change types of parameters and of result columns.
All our clients use Entity Framework 4 to access the database. All access is done
though stored procedures. So suppose there was a procedure:
create procedure Data.GetReports(@type smallint) as
begin
select Type, ... from Data.Report where Type = @type;
end;
where column "Type" was of type smallint. Now
we were going to change it to:
create procedure Data.GetReports(@type int) as
begin
select Type, ... from Data.Report where Type = @type;
end;
where "Type" column became of type int.
Our tests have shown that EF bears with change of types of input parameters, but throws
exceptions when column type has been changed, even when a value fits the
range. The reason is that EF uses method SqlDataReader.GetInt16
to access the column value. This method has a remark: "No
conversions are performed; therefore, the data retrieved must already be a 16-bit
signed integer."
Fortunately, we have found that EF allows additional columns in the result set. This helped us to formulate the solution.
We have updated the procedure definition like this:
create procedure Data.GetReports(@type int) as
begin
select
cast(Type as smallint) Type, -- deprecated
Type TypeEx, ...
from
Data.Report
where
Type = @type;
end;
This way:
- result column
"Type" is declared as deprecated;
- old clients still work;
- all clients should be updated to use
"TypeEx" column;
- after all clients will be updated we shall remove
"Type" column from the result
set.
So there is a clear migration process.
P.S. we don't understand why SqlDataReader doesn't support value
conversion.
Recently we had a discussion with DBA regarding optimization strategey we have
selected for some queries.
We have a table in our database. These are facts about that table:
- the table is partitioned by date;
- each partition contains a month worth of data;
- the table contains at present about 110 million rows;
- the table ever grows;
- the table is most accessed in the database;
- the most accessed part of the data is related to last 2-3 days,
which is about 150000 rows.
The way we have optimized access to that table was a core of the dispute.
We have created filtered index that includes data for the last 3 days.
To achieve desired effect we had to:
- create a job that recreates that index once a day, as filter condition is
moving;
- adjust queries that access the table, as we had to use several access pathes
to the table depending on date.
As result we can see that under the load, stored procedures that access that table
became almost 50% faster. On the other hand maintainance became more
complicated.
DBA who didn't like the database complications had to agree that there are speed
improvements. He said that there should be a better way to achieve the same
effect but could not find it.
Are there a better way to optimize access to this table?
We're implementing UDT changes in the big database. Earlier, that
User Defined Type was based on smallint, and now we have to use int as the base.
The impact
here is manyfold:
- Clients of the database should be prepared to use wider types.
- All stored procedures, functions, triggers, and views should be updated
accordingly.
- Impact on the database size should be analyzed.
- Types of columns in tables should be changed.
- Performance impact should be minimal.
Now, we're trying to address (3),
(5) and to implement (4), while trying to keep interface with clients using old
types.
As for database size impact, we have found that an index fragmentation is a
primary disk space waster (see Reorganize index in SQL Server).
We have performed some partial index reorganization and can see now that we can gain
back hundreds of GB of a disk space. On the other hand we use page compression, so we expect that change of types will not increase
sizes of tables considerably. Indeed, our measurments show that tables will only be
~1-3% bigger.
The change of types of columns is untrivial task. The problem is that if you try
to change column's type (which is part of clustered index) directly then you
should temporary remove foreign keys, and to rebuild all indices. This won't
work neither due to disk space required for the operation (a huge transaction
log is required), nor due to availability of tables (we're talking about days or
even weeks to rebuild indices).
To work-around the problem we have selected another way. For each target table T
we performed the following:
- Renamed table T to T_old;
- Created a table T_new with required type changes;
- Created a view named T, which is union of T_old for the dates before a split
date and T_new for the dates after the split date;
- Created instead of insert/update/delete triggers for the view T.
- Created a procedures that move data in bulks from T_old to the T_new, update
split date in view definitions, and delete data from T_old.
Note that:
- the new view uses wider column types, so we had to change stored
procedures that clients use to cast those columns back to shorter types to
prevent side effects (fortunately all access to this database is through stored
procedures and functions);
- the procedures that transfer data between new and old tables may work online;
- the quality of execution plans did not degrade due to switch from table to a
view;
- all data related to the date after the split date are inserted into T_new
table.
After transfer will be complete we shall drop T_old tables, and T views, and
will rename T_new tables into T.
This will complete part 4 of the whole task. Our estimations are that it will
take a month or even more to complete the transfer. However solution is rather
slow, the database will stay online whole this period, which is required
condition.
The next task is to deal with type changes in parameters of stored procedures
and column types of output result sets. We're not sure yet what's the best way
to deal with it, and probably shall complain about in in next posts.
Back in 2006 and 2007 we have defined dbo.Numbers function:
Numbers table in SQL Server 2005,
Parade of numbers. Such construct is very important in a set based
programming. E.g. XPath 2 contains a range expression like this: "1 to 10" to
return a sequence of numbers.
Unfortunately neither SQL Server 2008 R2, nor SQL Server 2012 support such
construct, so dbo.Numbers function is still actual.
After all these years the function evolved a little bit to achieve a better
performance. Here is its source:
-- Returns numbers table.
-- Table has a following structure: table(value int not null);
-- value is an integer number that contains numbers from 1 to a specified value.
create function dbo.Numbers
(
-- Number of rows to return.
@count int
)
returns table
as
return
with Number8 as
(
select
*
from
(
values
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0),
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)
) N(Value)
),
Number32(Value) as
(
select
0
from
Number8 N1
left join
Number8 N2
on
@count > 0x100
left join
Number8 N3
left join
Number8 N4
on
@count > 0x1000000
on
@count > 0x10000
)
select top(@count) row_number() over(order by @count) Value from Number32;
We're working with an online database, which is ever populated with a new
data. Database activity is mostly around recent data. Activity against older
data declines with increasing the distance from today. The ratio of an amount of a
new data, say for a last month, to the whole data, at present stays at
~1%. The size of database is measured in TBs.
While we're developers and not DBA's, you will see from
a later blog
posts why we're bothered with the database size. In short we're planning to
change some UDF type from smallint to int. This will impact
on many tables, and the task now is to estimate that impact.
Our first attempts to measure the difference between table sizes before and
after type change showed that a data fragmentation often masks the difference, so
we started to look at a way to reduce fragmentation.
Internet is full with recomentations. An advice can be found in BOL at
Reorganize
and Rebuild Indexes.
So, our best help in this task is the function sys.dm_db_index_physical_stats,
which reports statistics about fragmentation.
Analysing what that function has given to us we could see that we had a highly
fragmented data. There was no reason to bear with that taking into an account that
the most of the data stored in the database is historical, which is rarely
accessed and even more rarely updated.
The next simplest instument adviced is:
alter index { index_name | ALL } on <object> reorganize [ PARTITION = partition_number ];
The less trivial but often more efficient instrument is the use of online index
rebuild and index reorganize depending on index type and a level of
fragmentation.
All in all our estimation is that rebuilding or reorganizing indices frees
~100-200GBs of disk space. While, it's only a small percent of total database
size, it gives us several monthes worth of a disk space!
Earlier we overlooked SQL Server API to monitor fragmentation, rebuild, and
reorganize indices, and now we're going to create a job that will regulary
defragment the database.
We have a large table in the form:
create table dbo.Data
(
Date date not null,
Type int not null,
Value nvarchar(50) null,
primary key clustered(Date, Type)
);
create unique nonclustered index IX_Data on dbo.Data(Type, Date);
Among other queries we often need a snapshot of data per each Type for a latest
Date available:
select
max(Date) Date,
Type
from
dbo.Data
group by
Type
We have
found that the above select does not run well on our data set. In fact dbo.Data
grows with time, while snapshot we need stays more or less of the same size. The
best solution to such query is to precalculate it. One way would be to create an
indexed view, but SQL Server does not support max() aggregate in indexed views.
So, we have decided to add additional bit field dbo.Data.Last indicating that
a row belongs to a last date snapshot, and to create filtered index to access
that snapshot:
create table dbo.Data
(
Date date not null,
Type int not null,
Value nvarchar(50) null,
Last bit not null default 0,
primary key clustered(Date, Type)
);
create unique nonclustered index IX_Data on dbo.Data(Type, Date);
create unique nonclustered index IX_Data_Last on dbo.Data(Type)
include(Date)
where Last = 1;
One way to support Last indicator is to create a trigger that will adjust Last
value:
create trigger dbo.Data_Update on dbo.Data
after insert,delete,update
as
begin
if (trigger_nestlevel(@@procid) < 2)
begin
set nocount on;
with
D as
(
select Date, Type from deleted
union
select Date, Type from inserted
),
U as
(
select
V.Date, V.Type
from
D
inner join
dbo.Data V
on
(V.Last = 1) and
(V.Type = D.Type)
union
select
max(V.Date) Date,
V.Type
from
D
inner join
dbo.Data V
on
V.Type = D.Type
group by
V.Type
),
V as
(
select
rank()
over(partition by
V.Type
order by
V.Date desc) Row,
V.*
from
dbo.Data V
inner join
U
on
(V.Date = U.Date) and
(V.Type = U.Type)
)
update V
set
Last = 1 - cast(Row - 1 as bit);
end;
end;
With Last indicator in action, our original query has been transformed to:
select Date, Type
from dbo.Data where Last = 1
Execution plan shows that a new filtered index
IX_Data_Last is used. Execution speed has increased considerably.
As our actual table contains other bit fields, so Last
indicator did not
increase the table size, as SQL Server packs each 8 bit fields in one byte.
Let's start from a distance.
We support a busy database for a customer. Customer's requirement (in fact,
state's requirement) is that the database should have audit logs. This
means that all important requests should be logged. These logs help both for the
offline security analysis, and for the database health monitoring.
Before the end of the last year we used SQL Server 2005, and then customer
has upgraded to SQL Server 2008 R2.
As
by design the database is accessed through Stored Procedures only, so the logging was done
using
a small SP that traced input parameters and execution time. The call to that SP
was inserted throughout the code of other SPs.
We expected SQL Server 2008 R2
to simplify the task, and to allow us to switch
the audit on and off on a fine grained level without the need to change a SP in
the production (see
Understanding
SQL Server Audit for details).
Unfortunatelly, we have almost immediately found that
the current audit implementation traces SP calls but does not store parameter values. This way, you can see that
there was a call "execute X @param1, @param2", but you
have no idea what values were passed. Internet search shows that this a known problem (see
SQL Server 2008 Database Audit on INSERT UPDATE and DELETE actual SQL and not
parameter values), which renders SQL Server Audit useless.
But nevertheless, looking at how can we simplify our hand-made audit we have found a
brilliant solution: "Light
weight SQL Server procedure auditing without using SQL Server auditing".
It's so simple, that it's a shame that we did not invent it ourselves!
The approach is to insert or remove tracing code automatically. Indeed, there is
nothing but data in the database, even the text of SP is only a data.
To automate it even more, we have defined a small table with names of procedures
and their log levels, and have defined a procedure "Log.SetLevel @level" to configure
all logging in one go. In addition we have simplified logging procedures and
tables, and started to store parameters in xml columns rather than in a
pipe-concatenated strings.
Now, to the negative SP execution times.
The logging code among other things measures current_timestamp at
the begin and at the end of the execution of SP. This helps us (as developers)
to monitor how database performs on a day to day basis, and to build many useful
statistics.
For example we can see that the duration of about 10% of untrivial selects is
0ms (execution time is under 1ms). This means that SQL Server is good at
data caching. But what is most interesting is that about 0.1% of requests have
negative duration!
You could speculate
on parallel or on out of order execution, but the paradox is
resolved when you look closely on a value of duration. It's always around of -7,200,000ms. No
one will assume that execution has ended two hours before it has started. So,
what does it mean -2 hours? Well, we live in (UTC+02:00) Jerusalem time zone. We think that UTC offset crawls somehow into the result. To prove our
hypothesis we would like to change time zone on sql servers, but customer won't agree on
such an experiment.
This effect probably means that there is some hidden bug in SQL Server 2008 R2 that we cannot
reliably reproduce, but we can see that the datediff(ms,
start_timestamp, end_timestamp) may return negative value when it's known
that start_timestamp is acquired before end_timestamp.
Update: What a shame. During tunning of the original logging procedures we have changed type from datetime to datetime2, and calls from GETUTCDATE() to current_timestamp, except one place (default value in the table definition) where it remained with GETUTCDATE().
So, negative durations meant operation timeout (in our case duration is greater than 30 secs).
A customer have a table with data stored by dates, and asked us to present data
from this table by sequential date ranges.
This query sounded trivial but took us half a day to create such a select.
For simplicity consider a table of integer numbers, and try to build a select
that returns pairs of continuous ranges of values.
So, for an input like this:
declare @values table
(
value int not null primary key
);
insert into @values(value)
select 1
union all
select 2
union all
select 3
union all
select 5
union all
select 6
union all
select 8
union all
select 10
union all
select 12
union all
select 13
union all
select 14;
You will have a following output:
low high
---- ----
1 3
5 6
8 8
10 10
12 14
Logic of the algorithms is like this:
- get a low bound of each range (a value without value - 1 in the source);
- get a high bound of each range (a value without value + 1 in the source);
- combine low and high bounds.
Following this logic we have built at least three different queries, where the
shortest one
is:
with source as
(
select * from @values
)
select
l.value low,
min(h.value) high
from
source l
inner join
source h
on
(l.value - 1 not in (select value from source)) and
(h.value + 1 not in (select value from source)) and
(h.value >= l.value)
group by
l.value;
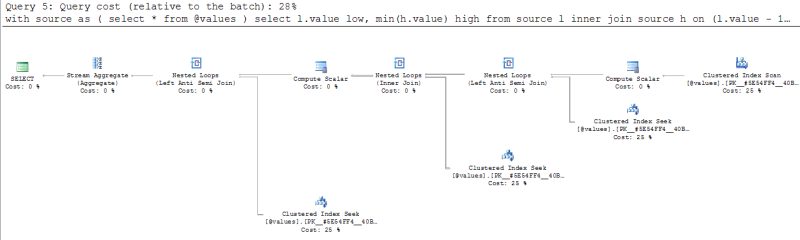
Looking at this query it's hard to understand why it took so
long to
write so simple code...
While looking at some SQL we have realized that it can be considerably optimized.
Consider a table source like this:
with Data(ID, Type, SubType)
(
select 1, 'A', 'X'
union all
select 2, 'A', 'Y'
union all
select 3, 'A', 'Y'
union all
select 4, 'B', 'Z'
union all
select 5, 'B', 'Z'
union all
select 6, 'C', 'X'
union all
select 7, 'C', 'X'
union all
select 8, 'C', 'Z'
union all
select 9, 'C', 'X'
union all
select 10, 'C', 'X'
)
Suppose you want to group data by type, to calculate number of elements in each
group and to display sub type if all rows in a group are of the same sub type.
Earlier we have written the code like this:
select
Type,
case when count(distinct SubType) = 1 then min(SubType) end SubType,
count(*) C
from
Data
group by
Type;
Namely, we select min(SybType) provided that there is a single distinct
SubType, otherwise null is shown. That works perfectly,
but algorithmically count(distinct SubType) = 1 needs to build a set
of distinct values for each group just to ask the size of this set. That is
expensive!
What we wanted can be expressed differently: if min(SybType) and
max(SybType) are the same then we want to display it, otherwise to show
null.
That's the new version:
select
Type,
case when min(SubType) = max(SubType) then min(SubType) end SubType,
count(*) C
from
Data
group by
Type;
Such a simple rewrite has cardinally simplified the execution plan:
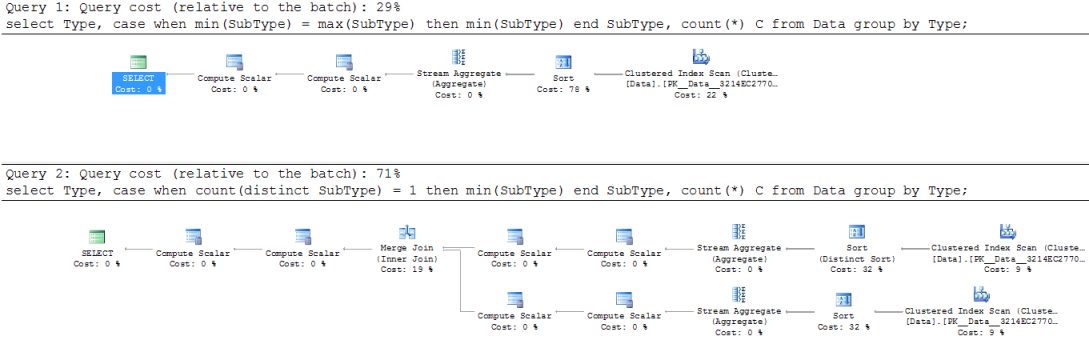
Another bizarre problem we have discovered is that SQL Server 2008 R2 just does
not support the following:
select
count(distinct SubType) over(partition by Type)
from
Data
That's really strange, but it's known bug (see
Microsoft Connect).
A database we support for a client contains multi-billion row tables. Many
users query the data from that database, and it's permanently populated
with a new data.
Every day we load several millions rows of a new data. Such loads can lock tables for a
considerable time, so our loading procedures collect new data into intermediate
tables and insert it into a final destination by chunks, and usually after work
hours.
SQL Server 2008 R2 introduced
READ_COMMITTED_SNAPSHOT database option. This feature trades locks for an
increased tempdb size (to store row versions) and possible performance
degradation during a transaction.
When we have switched the database to that option we did
not notice any considerable performance change. Encouraged, we've decided to
increase size of chunks of data we insert at once.
Earlier we have found that when we insert no more than 1000 rows
at once, users don't notice impact, but for a bigger chunk sizes users start to
complain on performance degradation. This has probably happened due to locks
escalations.
Now, with chunks of 10000 or even 100000 rows we have found that no queries
became slower. But load process became several times faster.
We were ready to pay for increased tempdb and transaction log size to increase
performance, but in our case we didn't approach limits assigned by the DBA.
Another gain is that we can easily load data at any time. This makes data we
store more up to date.
Recently, we have found and reported the bug in the SQL Server 2008 (see SQL Server 2008 with(recompile), and also Microsoft Connect).
Persons, who's responsible for the bug evaluation has closed it, as if "By Design". This strange resolution, in our opinion, says about those persons only.
Well, we shall try once more (see Microsoft Connect). We have posted another trivial demonstartion of the bug, where we show that option(recompile) is not used, which leads to table scan (nothing worse can happen for a huge table).
Recently we have introduced some stored procedure in the production and have
found that it performs incredibly slow.
Our reasoning and tests in the development environment did not manifest any
problem at all.
In essence that procedure executes some SELECT and returns a status as a signle
output variable. Procedure recieves several input parameters, and the SELECT
statement uses
with(recompile) execution hint to optimize the performance for a specific
parameters.
We have analyzed the execution plan of that procedure and have found that it
works as if with(recompile) hint was not specified. Without that hint SELECT
failed to use index seek but rather used index scan.
What we have lately found is that the same SELECT that produces result set
instead of reading result into a variable performs very well.
We think that this is a bug in SQL Server 2008 R2 (and in SQL Server 2008).
To demonstrate the problem you can run this test:
-- Setup
create table dbo.Items
(
Item int not null primary key
);
go
insert into dbo.Items
select 1
union all
select 2
union all
select 3
union all
select 4
union all
select 5
go
create procedure dbo.GetMaxItem
(
@odd bit = null,
@result int output
)
as
begin
set nocount on;
with Items as
(
select * from dbo.Items where @odd is null
union all
select * from dbo.Items where (@odd = 1) and ((Item & 1) = 1)
union all
select * from dbo.Items where (@odd = 0) and ((Item & 1) = 0)
)
select @result = max(Item) from Items
option(recompile);
end;
go
create procedure dbo.GetMaxItem2
(
@odd bit = null,
@result int output
)
as
begin
set nocount on;
declare @results table
(
Item int
);
with Items as
(
select * from dbo.Items where @odd is null
union all
select * from dbo.Items where (@odd = 1) and ((Item & 1) = 1)
union all
select * from dbo.Items where (@odd = 0) and ((Item & 1) = 0)
)
insert into @results
select max(Item) from Items
option(recompile);
select @result = Item from @results;
end;
go
Test with output into a variable:
declare @result1 int;
execute dbo.GetMaxItem @odd = null, @result = @result1 output
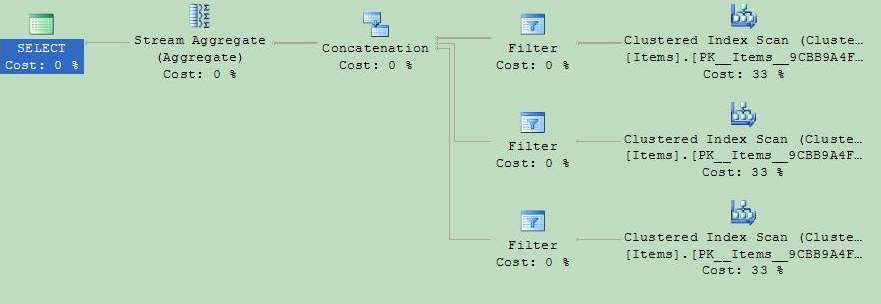
Test without output directly into a variable:
declare @result2 int;
execute dbo.GetMaxItem2 @odd = null, @result = @result2 output
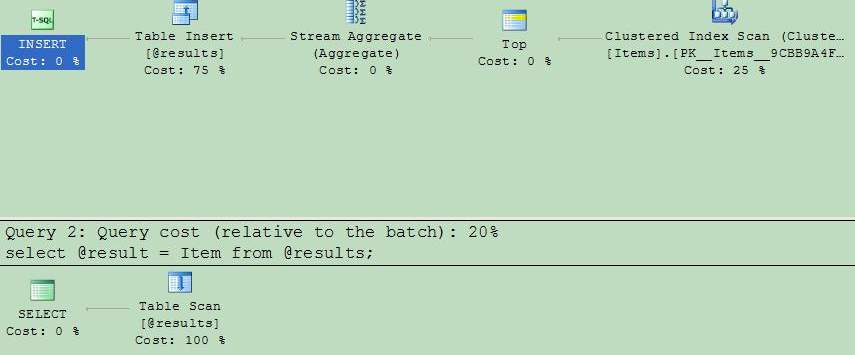
Now, you can see the difference: the first execution plan uses startup expressions, while the second optimizes execution branches, which are not really used.
In our case it was crucial, as the execition time difference was minutes (and
more in future) vs a split of second.
See also
Microsoft Connect Entry.
Earlier, we have described an approach to call Windows Search from SQL Server 2008. But it has turned out that our problem is more complicated...
All has started from the initial task:
- to allow free text search in a store of huge xml files;
- files should be compressed, so these are *.xml.gz;
- search results should be addressable to a fragment within xml.
Later we shall describe how we have solved this task, and now it's enough to say that we have implemented a Protocol Handler for Windows Search named '.xml-gz:'. This way original file stored say at 'file:///c:/store/data.xml-gz' is seen as a container by the Windows Search:
- .xml-gz:///file:c:/store/data.xml-gz/id1.xml
- .xml-gz:///file:c:/store/data.xml-gz/id2.xml
- ...
This way search xml should be like this:
select System.ItemUrl from SystemIndex where scope='.xml-gz:' and contains(...)
Everything has worked during test: we have succeeded to issue Windows Search selects from SQL Server and join results with other sql queries.
But later on when we considered a runtime environment we have seen that our design won't work. The reason is simple. Windows Search will work on a computer different from those where SQL Servers run. So, the search query should look like this:
select System.ItemUrl from Computer.SystemIndex where scope='.xml-gz:' and contains(...)
Here we have realized the limitation of current (Windows Search 4) implementation: remote search works for shared folders only, thus query may only look like:
select System.ItemUrl from Computer.SystemIndex where scope='file://Computer/share/' and contains(...)
Notice that search restricts the scope to a file protocol, this way remoter search will never return our results. The only way to search in our scope is to perform a local search.
We have considered following approaches to resolve the issue.
The simplest one would be to access Search protocol on remote computer using a connection string: "Provider=Search.CollatorDSO;Data Source=Computer" and use local queries. This does not work, as provider simply disregards Data Source parameter.
The other try was to use MS Remote OLEDB provider. We tried hard to configure it but it always returns obscure error, and more than that it's deprecated (Microsoft claims to remove it in future).
So, we decided to forward request manually:
- SQL Server calls a web service (through a CLR function);
- Web service queries Windows Search locally.
Here we considered WCF Data Services and a custom web service.
The advantage of WCF Data Services is that it's a technology that has ambitions of a standard but it's rather complex task to create implementation that will talk with Windows Search SQL dialect, so we have decided to build a primitive http handler to get query parameter. That's trivial and also has a virtue of simple implementation and high streamability.
So, that's our http handler (WindowsSearch.ashx):
<%@ WebHandler Language="C#" Class="WindowsSearch" %>
using System;
using System.Web;
using System.Xml;
using System.Text;
using System.Data.OleDb;
/// <summary>
/// A Windows Search request handler.
/// </summary>
public class WindowsSearch: IHttpHandler
{
/// <summary>
/// Handles the request.
/// </summary>
/// <param name="context">A request context.</param>
public void ProcessRequest(HttpContext context)
{
var request = context.Request;
var query = request.Params["query"];
var response = context.Response;
response.ContentType = "text/xml";
response.ContentEncoding = Encoding.UTF8;
var writer = XmlWriter.Create(response.Output);
writer.WriteStartDocument();
writer.WriteStartElement("resultset");
if (!string.IsNullOrEmpty(query))
{
using(var connection = new OleDbConnection(provider))
using(var command = new OleDbCommand(query, connection))
{
connection.Open();
using(var reader = command.ExecuteReader())
{
string[] names = null;
while(reader.Read())
{
if (names == null)
{
names = new string[reader.FieldCount];
for (int i = 0; i < names.Length; ++i)
{
names[i] = XmlConvert.EncodeLocalName(reader.GetName(i));
}
}
writer.WriteStartElement("row");
for(int i = 0; i < names.Length; ++i)
{
writer.WriteElementString(
names[i],
Convert.ToString(reader[i]));
}
writer.WriteEndElement();
}
}
}
}
writer.WriteEndElement();
writer.WriteEndDocument();
writer.Flush();
}
/// <summary>
/// Indicates that a handler is reusable.
/// </summary>
public bool IsReusable { get { return true; } }
/// <summary>
/// A connection string.
/// </summary>
private const string provider =
"Provider=Search.CollatorDSO;" +
"Extended Properties='Application=Windows';" +
"OLE DB Services=-4";
}
And a SQL CLR function looks like this:
using System;
using System.Collections;
using System.Collections.Generic;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Net;
using System.IO;
using System.Xml;
/// <summary>
/// A user defined function.
/// </summary>
public class UserDefinedFunctions
{
/// <summary>
/// A Windows Search returning result as xml strings.
/// </summary>
/// <param name="url">A search url.</param>
/// <param name="userName">A user name for a web request.</param>
/// <param name="password">A password for a web request.</param>
/// <param name="query">A Windows Search SQL.</param>
/// <returns>A result rows.</returns>
[SqlFunction(
IsDeterministic = false,
Name = "WindowsSearch",
FillRowMethodName = "FillWindowsSearch",
TableDefinition = "value nvarchar(max)")]
public static IEnumerable Search(
string url,
string userName,
string password,
string query)
{
return SearchEnumerator(url, userName, password, query);
}
/// <summary>
/// A filler of WindowsSearch function.
/// </summary>
/// <param name="value">A value returned from the enumerator.</param>
/// <param name="row">An output value.</param>
public static void FillWindowsSearch(object value, out string row)
{
row = (string)value;
}
/// <summary>
/// Gets a search row enumerator.
/// </summary>
/// <param name="url">A search url.</param>
/// <param name="userName">A user name for a web request.</param>
/// <param name="password">A password for a web request.</param>
/// <param name="query">A Windows Search SQL.</param>
/// <returns>A result rows.</returns>
private static IEnumerable<string> SearchEnumerator(
string url,
string userName,
string password,
string query)
{
if (string.IsNullOrEmpty(url))
{
throw new ArgumentException("url");
}
if (string.IsNullOrEmpty(query))
{
throw new ArgumentException("query");
}
var requestUrl = url + "?query=" + Uri.EscapeDataString(query);
var request = WebRequest.Create(requestUrl);
request.Credentials = string.IsNullOrEmpty(userName) ?
CredentialCache.DefaultCredentials :
new NetworkCredential(userName, password);
using(var response = request.GetResponse())
using(var stream = response.GetResponseStream())
using(var reader = XmlReader.Create(stream))
{
bool read = true;
while(!read || reader.Read())
{
if ((reader.Depth == 1) && reader.IsStartElement())
{
// Note that ReadInnerXml() advances the reader similar to Read().
yield return reader.ReadInnerXml();
read = false;
}
else
{
read = true;
}
}
}
}
}
And, finally, when you call this service from SQL Server you write query like this:
with search as
(
select
cast(value as xml) value
from
dbo.WindowsSearch
(
N'http://machine/WindowsSearchService/WindowsSearch.ashx',
null,
null,
N'
select
"System.ItemUrl"
from
SystemIndex
where
scope=''.xml-gz:'' and contains(''...'')'
)
)
select
value.value('/System.ItemUrl[1]', 'nvarchar(max)')
from
search
Design is not trivial but it works somehow.
After dealing with all these problems some questions remain unanswered:
- Why SQL Server does not allow to query Windows Search directly?
- Why Windows Search OLEDB provider does not support "Data Source" parameter?
- Why Windows Search does not support custom protocols during remote search?
- Why SQL Server does not support web request/web services natively?
Let's assume you're loading data into a table using BULK INSERT from tab
separated file. Among others you have some varchar field, which may contain any
character. Content of such field is escaped with usual scheme:
'\' as '\\';char(13) as '\n';char(10) as '\r';char(9) as '\t';
But now, after loading, you want to unescape content back. How would you do it?
Notice that:
'\t' should be converted to a char(9);'\\t' should be converted to a '\t';'\\\t' should be converted to a '\' + char(9);
It might be that you're smart and you will immediately think of correct
algorithm, but for us it took a while to come up with a neat solution:
declare @value varchar(max);
set @value = ...
-- This unescapes the value
set @value =
replace
(
replace
(
replace
(
replace
(
replace(@value, '\\', '\ '),
'\n',
char(10)
),
'\r',
char(13)
),
'\t',
char(9)
),
'\ ',
'\'
);
Do you know a better way?
We were trying to query Windows Search from an SQL Server 2008.
Documentation states that Windows Search is exposed as OLE DB datasource. This meant that we could just query result like this:
SELECT
*
FROM
OPENROWSET(
'Search.CollatorDSO.1',
'Application=Windows',
'SELECT "System.ItemName", "System.FileName" FROM SystemIndex');
But no, such select never works. Instead it returns obscure error messages:
OLE DB provider "Search.CollatorDSO.1" for linked server "(null)" returned message "Command was not prepared.".
Msg 7399, Level 16, State 1, Line 1
The OLE DB provider "Search.CollatorDSO.1" for linked server "(null)" reported an error. Command was not prepared.
Msg 7350, Level 16, State 2, Line 1
Cannot get the column information from OLE DB provider "Search.CollatorDSO.1" for linked server "(null)".
Microsoft is silent about reasons of such behaviour. People came to a conclusion that the problem is in the SQL Server, as one can query search results through OleDbConnection without problems.
This is very unfortunate, as it bans many use cases.
As a workaround we have defined a CLR function wrapping Windows Search call and returning rows as xml fragments. So now the query looks like this:
select
value.value('System.ItemName[1]', 'nvarchar(max)') ItemName,
value.value('System.FileName[1]', 'nvarchar(max)') FileName
from
dbo.WindowsSearch('SELECT "System.ItemName", "System.FileName" FROM SystemIndex')
Notice how we decompose xml fragment back to fields with the value() function.
The C# function looks like this:
using System;
using System.Collections;
using System.IO;
using System.Xml;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Data.OleDb;
using Microsoft.SqlServer.Server;
public class UserDefinedFunctions
{
[SqlFunction(
FillRowMethodName = "FillSearch",
TableDefinition="value xml")]
public static IEnumerator WindowsSearch(SqlString query)
{
const string provider =
"Provider=Search.CollatorDSO;" +
"Extended Properties='Application=Windows';" +
"OLE DB Services=-4";
var settings = new XmlWriterSettings
{
Indent = false,
CloseOutput = false,
ConformanceLevel = ConformanceLevel.Fragment,
OmitXmlDeclaration = true
};
string[] names = null;
using(var connection = new OleDbConnection(provider))
using(var command = new OleDbCommand(query.Value, connection))
{
connection.Open();
using(var reader = command.ExecuteReader())
{
while(reader.Read())
{
if (names == null)
{
names = new string[reader.FieldCount];
for (int i = 0; i < names.Length; ++i)
{
names[i] = XmlConvert.EncodeLocalName(reader.GetName(i));
}
}
var stream = new MemoryStream();
var writer = XmlWriter.Create(stream, settings);
for(int i = 0; i < names.Length; ++i)
{
writer.WriteElementString(names[i], Convert.ToString(reader[i]));
}
writer.Close();
yield return new SqlXml(stream);
}
}
}
}
public static void FillSearch(object value, out SqlXml row)
{
row = (SqlXml)value;
}
}
Notes:
- Notice the use of "
OLE DB Services=-4" in provider string to avoid transaction enlistment (required in SQL Server 2008).
- Permission level of the project that defines this extension function should be set to unsafe (see Project Properties/Database in Visual Studio) otherwise it does not allow the use OLE DB.
- SQL Server should be configured to allow CLR functions, see Server/Facets/Surface Area Configuration/ClrIntegrationEnabled in Microsoft SQL Server Management Studio
- Assembly should either be signed or a database should be marked as trustworthy, see Database/Facets/Trustworthy in Microsoft SQL Server Management Studio.
It's now the time to explore CLR implementation of the Numbers and Split functions in the SQL Server.
I've created a simple C# assembly that defines two table valued functions Numbers_CLR and Split_CLR. Note that I had to fix autogenerated sql function declaration in order to replace nvarchar(4000) with nvarchar(max):
using System;
using System.Collections;
using System.Collections.Generic;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Diagnostics;
public class UserDefinedFunctions
{
[SqlFunction]
public static long GetTimestamp()
{
return Stopwatch.GetTimestamp();
}
[SqlFunction]
public static long GetFrequency()
{
return Stopwatch.Frequency;
}
[SqlFunction(
Name="Numbers_CLR",
FillRowMethodName = "NumbersFillRow",
IsPrecise = true,
IsDeterministic = true,
DataAccess = DataAccessKind.None,
TableDefinition = "value int")]
public static IEnumerator NumbersInit(int count)
{
for (int i = 0; i < count; i++)
{
yield return i;
}
}
public static void NumbersFillRow(Object obj, out int value)
{
value = (int)obj;
}
[SqlFunction(
Name = "Split_CLR",
FillRowMethodName = "SplitFillRow",
IsPrecise = true,
IsDeterministic = true,
DataAccess = DataAccessKind.None,
TableDefinition = "value nvarchar(max)")]
public static IEnumerator SplitInit(string value, string splitter)
{
if (string.IsNullOrEmpty(value))
yield break;
if (string.IsNullOrEmpty(splitter))
splitter = ",";
for(int i = 0; i < value.Length; )
{
int next = value.IndexOf(splitter, i);
if (next == -1)
{
yield return value.Substring(i);
break;
}
else
{
yield return value.Substring(i, next - i);
i = next + splitter.Length;
}
}
}
public static void SplitFillRow(Object obj, out string value)
{
value = (string)obj;
}
};
These are results of the test of differents variants of the numbers function for different numbers of lines to return (length): i description length duration msPerNumber
---- -------------- -------- ---------- -----------
0 Numbers 1 0.0964 0.0964
0 Numbers_CTE 1 0.2319 0.2319
0 Numbers_Table 1 0.1710 0.1710
0 Numbers_CLR 1 0.1729 0.1729
1 Numbers 2 0.0615 0.0307
1 Numbers_CTE 2 0.1327 0.0663
1 Numbers_Table 2 0.0816 0.0408
1 Numbers_CLR 2 0.1078 0.0539
2 Numbers 4 0.0598 0.0149
2 Numbers_CTE 4 0.1609 0.0402
2 Numbers_Table 4 0.0810 0.0203
2 Numbers_CLR 4 0.1092 0.0273
3 Numbers 8 0.0598 0.0075
3 Numbers_CTE 8 0.2308 0.0288
3 Numbers_Table 8 0.0813 0.0102
3 Numbers_CLR 8 0.1129 0.0141
4 Numbers 16 0.0598 0.0037
4 Numbers_CTE 16 0.3724 0.0233
4 Numbers_Table 16 0.0827 0.0052
4 Numbers_CLR 16 0.1198 0.0075
5 Numbers 32 0.0606 0.0019
5 Numbers_CTE 32 0.6473 0.0202
5 Numbers_Table 32 0.0852 0.0027
5 Numbers_CLR 32 0.1347 0.0042
6 Numbers 64 0.0615 0.0010
6 Numbers_CTE 64 1.1926 0.0186
6 Numbers_Table 64 0.0886 0.0014
6 Numbers_CLR 64 0.1648 0.0026
7 Numbers 128 0.0637 0.0005
7 Numbers_CTE 128 2.2886 0.0179
7 Numbers_Table 128 0.0978 0.0008
7 Numbers_CLR 128 0.2204 0.0017
8 Numbers 256 0.0679 0.0003
8 Numbers_CTE 256 4.9774 0.0194
8 Numbers_Table 256 0.1243 0.0005
8 Numbers_CLR 256 0.3486 0.0014
9 Numbers 512 0.0785 0.0002
9 Numbers_CTE 512 8.8983 0.0174
9 Numbers_Table 512 0.1523 0.0003
9 Numbers_CLR 512 0.5635 0.0011
10 Numbers 1024 0.0958 0.0001
10 Numbers_CTE 1024 17.8679 0.0174
10 Numbers_Table 1024 0.2453 0.0002
10 Numbers_CLR 1024 1.0504 0.0010
11 Numbers 2048 0.1324 0.0001
11 Numbers_CTE 2048 35.8185 0.0175
11 Numbers_Table 2048 0.3811 0.0002
11 Numbers_CLR 2048 1.9206 0.0009
12 Numbers 4096 0.1992 0.0000
12 Numbers_CTE 4096 70.9478 0.0173
12 Numbers_Table 4096 0.6772 0.0002
12 Numbers_CLR 4096 3.6921 0.0009
13 Numbers 8192 0.3361 0.0000
13 Numbers_CTE 8192 143.3364 0.0175
13 Numbers_Table 8192 1.2809 0.0002
13 Numbers_CLR 8192 7.3931 0.0009
14 Numbers 16384 0.6099 0.0000
14 Numbers_CTE 16384 286.7471 0.0175
14 Numbers_Table 16384 2.4579 0.0002
14 Numbers_CLR 16384 14.4731 0.0009
15 Numbers 32768 1.1546 0.0000
15 Numbers_CTE 32768 573.6626 0.0175
15 Numbers_Table 32768 4.7919 0.0001
15 Numbers_CLR 32768 29.0313 0.0009
16 Numbers 65536 2.3103 0.0000
16 Numbers_CTE 65536 1144.4052 0.0175
16 Numbers_Table 65536 9.5132 0.0001
16 Numbers_CLR 65536 57.7154 0.0009
17 Numbers 131072 4.4265 0.0000
17 Numbers_CTE 131072 2314.5917 0.0177
17 Numbers_Table 131072 18.9130 0.0001
17 Numbers_CLR 131072 116.4268 0.0009
18 Numbers 262144 8.7860 0.0000
18 Numbers_CTE 262144 4662.7233 0.0178
18 Numbers_Table 262144 38.3024 0.0001
18 Numbers_CLR 262144 230.1522 0.0009
19 Numbers 524288 18.4638 0.0000
19 Numbers_CTE 524288 9182.8146 0.0175
19 Numbers_Table 524288 83.4575 0.0002
19 Numbers_CLR 524288 468.0195 0.0009
These are results of the test of differents variants of the split function for different length of the string (length): i description strLength duration msPerChar
---- -------------- --------- ---------- ----------
0 Split 1 0.1442 0.1442
0 Split_CTE 1 0.2665 0.2665
0 Split_Table 1 0.2090 0.2090
0 Split_CLR 1 0.1964 0.1964
1 Split 2 0.0902 0.0451
1 Split_CTE 2 0.1788 0.0894
1 Split_Table 2 0.1087 0.0543
1 Split_CLR 2 0.1056 0.0528
2 Split 4 0.0933 0.0233
2 Split_CTE 4 0.2618 0.0654
2 Split_Table 4 0.1162 0.0291
2 Split_CLR 4 0.1143 0.0286
3 Split 8 0.1092 0.0137
3 Split_CTE 8 0.4408 0.0551
3 Split_Table 8 0.1344 0.0168
3 Split_CLR 8 0.1324 0.0166
4 Split 16 0.1422 0.0089
4 Split_CTE 16 0.7990 0.0499
4 Split_Table 16 0.1715 0.0107
4 Split_CLR 16 0.1687 0.0105
5 Split 32 0.2090 0.0065
5 Split_CTE 32 1.4924 0.0466
5 Split_Table 32 0.2458 0.0077
5 Split_CLR 32 0.4582 0.0143
6 Split 64 0.3464 0.0054
6 Split_CTE 64 2.9129 0.0455
6 Split_Table 64 0.3947 0.0062
6 Split_CLR 64 0.3880 0.0061
7 Split 128 0.6101 0.0048
7 Split_CTE 128 5.7348 0.0448
7 Split_Table 128 0.6898 0.0054
7 Split_CLR 128 0.6825 0.0053
8 Split 256 1.1504 0.0045
8 Split_CTE 256 11.5610 0.0452
8 Split_Table 256 1.3044 0.0051
8 Split_CLR 256 1.2901 0.0050
9 Split 512 2.2430 0.0044
9 Split_CTE 512 23.3854 0.0457
9 Split_Table 512 2.4992 0.0049
9 Split_CLR 512 2.4838 0.0049
10 Split 1024 4.5048 0.0044
10 Split_CTE 1024 45.7030 0.0446
10 Split_Table 1024 4.8886 0.0048
10 Split_CLR 1024 4.8601 0.0047
11 Split 2048 8.8229 0.0043
11 Split_CTE 2048 92.6160 0.0452
11 Split_Table 2048 9.7381 0.0048
11 Split_CLR 2048 9.8848 0.0048
12 Split 4096 17.6285 0.0043
12 Split_CTE 4096 184.3265 0.0450
12 Split_Table 4096 19.4092 0.0047
12 Split_CLR 4096 19.3849 0.0047
13 Split 8192 36.5924 0.0045
13 Split_CTE 8192 393.8663 0.0481
13 Split_Table 8192 39.3296 0.0048
13 Split_CLR 8192 38.9569 0.0048
14 Split 16384 70.7693 0.0043
14 Split_CTE 16384 740.2636 0.0452
14 Split_Table 16384 77.6300 0.0047
14 Split_CLR 16384 77.6878 0.0047
15 Split 32768 141.4202 0.0043
15 Split_CTE 32768 1481.5788 0.0452
15 Split_Table 32768 155.0163 0.0047
15 Split_CLR 32768 155.5904 0.0047
16 Split 65536 282.8597 0.0043
16 Split_CTE 65536 3098.3636 0.0473
16 Split_Table 65536 315.7588 0.0048
16 Split_CLR 65536 316.1782 0.0048
17 Split 131072 574.3652 0.0044
17 Split_CTE 131072 6021.9827 0.0459
17 Split_Table 131072 630.6880 0.0048
17 Split_CLR 131072 650.8676 0.0050
18 Split 262144 5526.9491 0.0211
18 Split_CTE 262144 17645.2219 0.0673
18 Split_Table 262144 5807.3244 0.0222
18 Split_CLR 262144 5759.6946 0.0220
19 Split 524288 11006.3019 0.0210
19 Split_CTE 524288 35093.2482 0.0669
19 Split_Table 524288 11585.3233 0.0221
19 Split_CLR 524288 11550.8323 0.0220
The results are:
- Recursive common table expression shows the worst timing.
- Split_CLR is on the pair with Split_Table, however Numbers_Table is better than Numbers_CLR.
- Split and Numbers based on unrolled recursion show the best timing (most of the time).
The End.
Well, several days have passed but for a some reason I've started to feel uncomfortable about Numbers function. It's all because of poor recursive CTE implementation. I have decided to unroll the cycle. The new version hovewer isn't a beautiful but is providing much more superior performance comparing with previous implementation:
/*
Returns numbers table.
Table has a following structure: table(value int not null);
value is an integer number that contains numbers from 1 to a specified value.
*/
create function dbo.Numbers
(
/* Number of rows to return. */
@count int
)
returns table
as
return
with Number4(Value) as
(
select 0 union all select 0 union all
select 0 union all select 0 union all
select 0 union all select 0 union all
select 0 union all select 0 union all
select 0 union all select 0 union all
select 0 union all select 0 union all
select 0 union all select 0 union all
select 0 union all select 0
),
Number8(Value) as
(
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4 union all
select 0 from Number4 union all select 0 from Number4
),
Number32(Value) as
(
select 0 from Number8 N1, Number8 N2, Number8 N3, Number8 N4
)
select top(@count) row_number() over(order by Value) Value from Number32;
The performance achieved is on pair with numbers table. Estimated number of rows is precise whenever we pass constant as parameter.
What is the moral? - There is a space for the enhancements in the recursive CTE.
Next day
Guess what? - Yes! there is also the CLR, which allows to create one more implementation of the numbers and split functions. In the next entry I'll show it, and performance comparison of different approaches.
This task is already discussed many times. SQL Server 2005 allows to create an inline function that splits such a string. The logic of such a function is self explanatory, which also hints that SQL syntax became better:
/*
Returns numbers table.
Table has a following structure: table(value int not null);
value is an integer number that contains numbers from 0 to a specified value.
*/
create function dbo.Numbers
(
/* Number of rows to return. */
@count int
)
returns table
as
return
with numbers(value) as
(
select 0
union all
select value * 2 + 1 from numbers where value < @count / 2
union all
select value * 2 + 2 from numbers where value < (@count - 1) / 2
)
select
row_number() over(order by U.v) value
from
numbers cross apply (select 0 v) U;
/*
Splits string using split character.
Returns a table that contains split positions and split values:
table(Pos, Value)
*/
create function dbo.Split
(
/* A string to split. */
@value nvarchar(max),
/* An optional split character.*/
@splitChar nvarchar(max) = N','
)
returns table
as
return
with Bound(Pos) as
(
select
Value
from
dbo.Numbers(len(@value))
where
(Value = 1) or
(substring(@value, Value - 1, len(@splitChar)) = @splitChar)
),
Word(Pos, Value) as
(
select
Bound.Pos,
substring
(
@value,
Bound.Pos,
case when Splitter.Pos > 0
then Splitter.Pos
else len(@value) + 1
end - Bound.Pos
)
from
Bound
cross apply
(select charindex(@splitChar, @value, Pos) Pos) Splitter
)
select Pos, Value from Word;
Test:
declare @s nvarchar(max);
set @s = N'ALFKI,BONAP,CACTU,FRANK';
select Value from System.Split(@s, default) order by Pos;
See also: Arrays and Lists in SQL Server, Numbers table in SQL Server 2005, Parade of numbers
SQL Server 2005 has got built-in partitions. As result, I have been given a task to port a database from SQL Server 2000 to 2005, and replace old style partitions with new one. It seems reasonable, but before modifying a production database, which is about 5TB in size, I've tested a small one.
Switch the data - it's an easy part. I need also to test all related stored procedures. At this point I've found shortcomings, which tightly related to a nature of the partitions.
In select statement SQL Server 2005 iterates over partitions, in contrast SQL Server 2000 rolls out partition view and embeds partition tables into an execution plan. The performance difference can be dramatic (the case I'm dealing with).
Suppose you are to get 'top N' rows of ordered set of data from several partitions. SQL Server 2000 can perform operations on partitions (to get ordered result per partition), and then merge them, and return 'top N' rows. However, if execution plan just iterates partitions and applies the same operations to each partition in sequential manner the result will be semiordered. To get 'top N' rows the sort operator is required. This is the case of SQL Server 2005.
The problem is that the SQL Server 2005 never uses merge operator to combine results!
To illustrate the problem let's define two partitioned tables:
create partition function [test](smalldatetime) as range left for values (N'2007-01-01', N'2007-02-01')
go
create partition scheme [testScheme] as partition [test] to [primary], [primary], [primary])
go
CREATE TABLE [dbo].[Test2000_12](
[A] [smalldatetime] NOT NULL,
[B] [int] NOT NULL,
[C] [nvarchar](50) NULL,
CONSTRAINT [PK_Test2000_12] PRIMARY KEY CLUSTERED
(
[A] ASC,
[B] ASC
)
)
GO
CREATE NONCLUSTERED INDEX [IX_Test2000_12] ON [dbo].[Test2000_12]
(
[B] ASC,
[A] ASC
)
GO
CREATE TABLE [dbo].[Test2000_01](
[A] [smalldatetime] NOT NULL,
[B] [int] NOT NULL,
[C] [nvarchar](50) NULL,
CONSTRAINT [PK_Test2000_01] PRIMARY KEY CLUSTERED
(
[A] ASC,
[B] ASC
)
)
GO
CREATE NONCLUSTERED INDEX [IX_Test2000_01] ON [dbo].[Test2000_01]
(
[B] ASC,
[A] ASC
)
GO
CREATE TABLE [dbo].[Test2000_02](
[A] [smalldatetime] NOT NULL,
[B] [int] NOT NULL,
[C] [nvarchar](50) NULL,
CONSTRAINT [PK_Test2000_02] PRIMARY KEY CLUSTERED
(
[A] ASC,
[B] ASC
)
)
GO
CREATE NONCLUSTERED INDEX [IX_Test2000_02] ON [dbo].[Test2000_02]
(
[B] ASC,
[A] ASC
)
GO
CREATE TABLE [dbo].[Test2005](
[A] [smalldatetime] NOT NULL,
[B] [int] NOT NULL,
[C] [nvarchar](50) NULL,
CONSTRAINT [PK_Test2005] PRIMARY KEY CLUSTERED
(
[A] ASC,
[B] ASC
)
) ON [testScheme]([A])
GO
CREATE NONCLUSTERED INDEX [IX_Test2005] ON [dbo].[Test2005]
(
[B] ASC,
[A] ASC
) ON [testScheme]([A])
GO
ALTER TABLE [dbo].[Test2000_01] WITH CHECK ADD CONSTRAINT [CK_Test2000_01] CHECK (([A]>='2007-01-01' AND [A]<'2007-02-01'))
GO
ALTER TABLE [dbo].[Test2000_01] CHECK CONSTRAINT [CK_Test2000_01]
GO
ALTER TABLE [dbo].[Test2000_02] WITH CHECK ADD CONSTRAINT [CK_Test2000_02] CHECK (([A]>='2007-02-01'))
GO
ALTER TABLE [dbo].[Test2000_02] CHECK CONSTRAINT [CK_Test2000_02]
GO
ALTER TABLE [dbo].[Test2000_12] WITH CHECK ADD CONSTRAINT [CK_Test2000_12] CHECK (([A]<'2007-01-01'))
GO
ALTER TABLE [dbo].[Test2000_12] CHECK CONSTRAINT [CK_Test2000_12]
GO
create view [dbo].[test2000] as
select * from dbo.test2000_12
union all
select * from dbo.test2000_01
union all
select * from dbo.test2000_02
go
/*
Returns numbers table.
Table has a following structure: table(value int not null);
value is an integer number that contains numbers from 0 to a specified value.
*/
create FUNCTION dbo.[Numbers]
(
/* Number of rows to return. */
@count int
)
RETURNS TABLE
AS
RETURN
with numbers(value) as
(
select 0
union all
select value * 2 + 1 from numbers where value < @count / 2
union all
select value * 2 + 2 from numbers where value < (@count - 1) / 2
)
select
row_number() over(order by U.v) value
from
numbers cross apply (select 0 v) U
Pupulate tables:
insert into dbo.Test2005
select
cast(N'2006-01-01' as smalldatetime) + 0.001 * N.Value,
N.Value,
N'Value' + cast(N.Value as nvarchar(16))
from
dbo.Numbers(500000) N
go
insert into dbo.Test2000
select
cast(N'2006-01-01' as smalldatetime) + 0.001 * N.Value,
N.Value,
N'Value' + cast(N.Value as nvarchar(16))
from
dbo.Numbers(500000) N
go
Perform a test:
select top 20
A, B
from
dbo.Test2005
--where
--(A between '2006-01-10' and '2007-01-10')
order by
B
select top 20
A, B
from
dbo.Test2000
--where
--(A between '2006-01-10' and '2007-01-10')
order by
B
--option(merge union)
The difference is obvious if you will open execution plan. In the first case estimated subtree cost is: 17.4099; in the second: 0.0455385.
SQL server cannot efficiently use index on columns (B, A). The problem presented here can appear in any select that occasionally accesses two partitions, but regulary uses only one, provided it uses a secondary index. In fact this covers about 30% of all selects in my database.
Next day
I've meditated a little bit more and devised a centaur: I can define a partition view over partition table. Thus I can use either this view or table depending on what I'm trying to achieve either iterate partitions or roll them out.
create view [dbo].[Test2005_View] as
select * from dbo.Test2005 where $partition.test(A) = 1
union all
select * from dbo.Test2005 where $partition.test(A) = 2
union all
select * from dbo.Test2005 where $partition.test(A) = 3
The following select is running the same way as SQL Server 2000 partitions:
select top 20
A, B
from
dbo.Test2005_View
-- dbo.Test2005
order by
B
I need to log actions into log table in my stored procedure, which is called in context of some transaction. The records in the log table I need no matter what happens (no, it's even more important to get them there if operation fails).
begin transaction
...
execute some_proc
...
if (...)
commit transaction
else
rollback transaction
some_proc:
...
insert into log...
insert ...
update ...
insert into log...
...
How to do this?
November 25
I've found two approaches:
- table variables, which do not participate into transactions;
- remote queries, which do not participate into local transactions;
The second way is more reliable, however not the fastest one. The idea is to execute query on the same sever as if it's a linked server.
Suppose you have a log table:
create table System.Log
(
ID int identity(1,1) not null,
Date datetime not null default getdate(),
Type int null,
Value nvarchar(max) null
);
To add log record you shall define a stored procedure:
create procedure System.WriteLog
(
@type int,
@message nvarchar(max)
)
as
begin
set nocount on;
execute(
'insert into dbname.System.Log(Type, Value) values(?, ?)',
@type,
@message)
as user = 'user_name'
at same_server_name;
end
Whenever you're calling System.WriteLog in context of local transaction the records are inserted into the System.Log table in a separate transaction.
My next SQL puzzle (thanks to fabulous XQuery support in SQL Server 2005) is how to reconstruct xml from the hierarchy table. This is reverse to the "Load xml into the table".
Suppose you have: select Parent, Node, Name from Data
where
(Parent, Node) - defines xml hierarchy, and
Name - xml element name.
How would you restore original xml?
November 8, 2006 To my anonymous reader:
declare @content nvarchar(max);
set @content = '';
with Tree(Node, Parent, Name) as
(
/* Source tree */
select Node, Parent, Name from Data
),
Leaf(Node) as
(
select Node from Tree
except
select Parent from Tree
),
NodeHeir(Node, Ancestor) as
(
select Node, Parent from Tree
union all
select
H.Node, T.Parent
from
Tree T inner join NodeHeir H on H.Ancestor = T.Node
),
ParentDescendants(Node, Descendats) as
(
select
Ancestor, count(Ancestor)
from
NodeHeir
where
Ancestor > 0
group by
Ancestor
),
Line(Row, Node, Text) as
(
select
O.Row, T.Node, O.Text
from
ParentDescendants D
inner join
Tree T
on D.Node = T.Node
cross apply
(
select D.Node * 2 - 1 Row, '<' + T.Name + '>' Text
union all
select (D.Node + D.Descendats) * 2, '</' + T.Name + '>'
) O
union all
select
D.Node * 2 - 1, T.Node, '<' + T.Name + '/>'
from
Leaf D inner join Tree T on D.Node = T.Node
)
select top(cast(0x7fffffff as int))
@content = @content + Text
from
Line
order by
Row asc, Node desc
option(maxrecursion 128);
select cast(@content as xml);
Say you need to load a table from an xml document, and this table defines some hierarchy. Believe me or not, but this is not that case when its better to store xml in the table.
Let's presume the table has:
- Node - document node id;
- Parent - parent node id;
- Name - node name.
The following defines a sample xml document we shall work with: declare @content xml;
set @content = '
<document>
<header/>
<activity>
<title/>
<row/>
<row/>
<row/>
<row/>
<total/>
</activity>
<activity>
<title/>
<row/>
<total/>
</activity>
<activity>
<title/>
<row/>
<total/>
</activity>
<activity>
<title/>
<row/>
<row/>
<row/>
<total/>
</activity>
</document>';
How would you solved this task?
I've been spending a whole day building acceptable solution. This is probably because I'm not an SQL guru. I've found answers using cursors, openxml, pure xquery, and finally hybrid of xquery and sql ranking functions.
The last is fast, and has linear dependency of working time to xml size. with NodeGroup(ParentGroup, Node, Name) as
(
select
dense_rank() over(order by P.Node),
row_number() over(order by N.Node),
N.Node.value('local-name(.)', 'nvarchar(max)')
from
@content.nodes('//*') N(Node)
cross apply
Node.nodes('..') P(Node)
),
Node(Parent, Node, Name) as
(
select
min(Node) over(partition by ParentGroup) - 1, Node, Name
from
NodeGroup
)
select * from Node order by Node;
Is there a better way? Anyone?
Return a table of numbers from 0 up to a some value. I'm facing this recurring task once in several years. Such periodicity induces me to invent solution once again but using contemporary features.
November 18:
This time I have succeeded to solve the task in one select:
declare @count int;
set @count = 1000;
with numbers(value) as
(
select 0
union all
select value * 2 + 1 from numbers where value < @count / 2
union all
select value * 2 + 2 from numbers where value < (@count - 1) / 2
)
select
row_number() over(order by U.V) value
from
numbers cross apply (select 1 V) U;
Do you have a better solution?
|