Say you need to load a table from an xml document, and this table defines some hierarchy. Believe me or not, but this is not that case when its better to store xml in the table.
Let's presume the table has:
- Node - document node id;
- Parent - parent node id;
- Name - node name.
The following defines a sample xml document we shall work with: declare @content xml;
set @content = '
<document>
<header/>
<activity>
<title/>
<row/>
<row/>
<row/>
<row/>
<total/>
</activity>
<activity>
<title/>
<row/>
<total/>
</activity>
<activity>
<title/>
<row/>
<total/>
</activity>
<activity>
<title/>
<row/>
<row/>
<row/>
<total/>
</activity>
</document>';
How would you solved this task?
I've been spending a whole day building acceptable solution. This is probably because I'm not an SQL guru. I've found answers using cursors, openxml, pure xquery, and finally hybrid of xquery and sql ranking functions.
The last is fast, and has linear dependency of working time to xml size. with NodeGroup(ParentGroup, Node, Name) as
(
select
dense_rank() over(order by P.Node),
row_number() over(order by N.Node),
N.Node.value('local-name(.)', 'nvarchar(max)')
from
@content.nodes('//*') N(Node)
cross apply
Node.nodes('..') P(Node)
),
Node(Parent, Node, Name) as
(
select
min(Node) over(partition by ParentGroup) - 1, Node, Name
from
NodeGroup
)
select * from Node order by Node;
Is there a better way? Anyone?
Return a table of numbers from 0 up to a some value. I'm facing this recurring task once in several years. Such periodicity induces me to invent solution once again but using contemporary features.
November 18:
This time I have succeeded to solve the task in one select:
declare @count int;
set @count = 1000;
with numbers(value) as
(
select 0
union all
select value * 2 + 1 from numbers where value < @count / 2
union all
select value * 2 + 2 from numbers where value < (@count - 1) / 2
)
select
row_number() over(order by U.V) value
from
numbers cross apply (select 1 V) U;
Do you have a better solution?
Do you think they are different? I think not too much.
Language, for a creative programmer, is a matter to express his virtues, and a hammer that brings a good salary for a skilled labourer.
Each new generation of programmers tries to prove itself. But how?
Well, C++ programmers invent their strings and smart pointers, and Java adepts (as they cannot create strings) design their springs and rubies.
It's probably all right - there is no dominance, but when I'm reading docs of someone's last pearl, I'm experiencing deja vu. On the whole, all looks as a chaotic movement.
Other time I think - how it's interesting to build something when you should not design the brick, even if you know that bricks aren't perfect.
I've been given a task to fix several xsls (in fact many big xsls) that worked with msxml and stoped to work with .NET. At first I thought it will be easy stuff, indeed both implementations are compatible as both implement http://www.w3.org/1999/XSL/Transform.
Well, I was wrong. After a 10 minutes I've been abusing that ignorant who has written xsls. More over, I was wondering how msxml could accept that shit.
So, come to the point. I had following xsl:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:user="http://mycompany.com/mynamespace">
<xsl:template match="/">
<HTML dir="rtl">
...
<BODY dir="rtl">
...
<TD width="68" dir="ltr" align="middle">
<FONT size="1" face="David">
<xsl:variable name="DegB" select="//*[@ZihuyMuzar='27171']" />
</FONT>
</TD>
...
<TD height="19" dir="ltr" align="middle">
<FONT size="2" face="David">
<xsl:value-of select="$DegB/*/Degem[1]/@*[3]" />
%
</FONT>
</TD>
...
I don't want to talk about "virtues" of "html" that's produced by this alleged "xsl", however about xsl itself. To my amazement msxml sees $DegB, which is declared and dies in different scope. At first I thought I was wrong: "Must be scope is defined defferently then I thought?", but no. OK, I said to myself I can fix that. I've created another xsl that elevates xsl:variable declarations to a scope where they are visible to xsl:value-of.
But that wasn't my main head ache. Some genius has decided to use third, forth, and so on attribute. What does this mean in the god's sake? How one could rely on this? I'll kill him if I'll find him! There was thousands of such @*[3]. Even if I'll see the original xml how can I be sure that msxml and .NET handle attribute collections in the same order?
There was no other way, but check this assumption. I've verified that both implementations store attributes in xml source order. This easied my pains.
To clarify implementation details I have digged in XmlDocument/XPathDocument implementations in .NET 1.1 and 2.0. I was curious how they store a set of attributes. It's interesting to know that they has decided to keep only ordered list of attributes in either implementation. This means that ordered attribute access is fast, and named access leads to list scan. In my opinion it's dubious solution. Probably the idea behind is that there is in average a few attributes to scan when one uses named access. In my case there were up to 100 attributes per element.
Conclusion?
1. Don't allow to ignorants to come near the xsl.
2. Don't design xmls that use many attributes when you're planning to use .NET xslt.
Recently we were creating a BizTalk 2006 project. A map was used to normalize input data, where numbers were stored with group separators like "15,000,000.00" and text (Hebrew in our case) was stored visually like "ןודנול סלפ קנב סדיולל".
We do need to store the output data the xml way, this means numbers as "15000000.00" and Hebrew text in logical form "ללוידס בנק פלס לונדון". Well, it's understood that there are no standard functoids that deal with bidi, as there are no too many people that know about the problem in the first place. However we thought at least that there will not be problems with removing of "," in numbers.
BizTalk 2006 does not provide functoids to solve either of these tasks! To answer our needs we have designed two custom functoids.
"Replace string":
Returns a string with text Replaced using a regular expression or search string.
First parameter is a string where to Replace.
Second parameter is a string or regular expression pattern in the format /pattern/flags to Replace.
Third parameter is a string or regular expression pattern that Replaces all found matches.
"Logical to visual converter":
Converts an input "logical" string into a "visual" string.
First parameter is a string to convert.
Optional second parameter is a start embedding level (LTR or RTL).
Download sample code.
In our recent .NET 2.0 GUI project our client ingenuously asked us to implement undo and redo facility. Nothing unusual nowadays, however it's still not the easiest thing in the world to implement.
Naturally you want to have this feature for a free. You do not want to invest too much time to support it. We had no much time to implement this "sugar" also. I know, I know, this is important for a user, however when you're facing a big project with a lot of logic to be implemented in short time you're starting to think it would be nice to have undo and redo logic that works independently (at least almost independently) on business logic.
Thus, what's that place where we could plug this service? - Exactly! - It's data binding layer.
When you're binding your data to controls the "Type Descriptor Architecture" is used to retrieve and update the data. Fortunately this architecture is allowing us to create a data wrapper (ICustomTypeDescriptor). Such wrapper should track property modifications of the data object thus providing undo and redo service. In short that's all, other are technical details.
Let's look at how undo and redo service goes into the action. Instead of: bindingSource.DataSource = data;
you have to write: bindingSource.DataSource = Create-UndoRedo-Wrapper(data);
There should also be a class to collect and track actions. User should create an instance of this class to implement the simplest form of code with undo and redo support: // Create UndoRedoManager. undoRedoManager = new UndoRedoManager(); // Create undo and redo wrapper around the data object. // Bind controls. dataBindingSource.DataSource = new UndoRedoTypeDescriptor(data, undoRedoManager);
Now turn our attention to the implementation of the undo and redo mechanism. There are two types in the core: UndoRedoManager and IAction. The first one is to track actions, the later one is to define undo and redo actions. UndoRedoManager performs either "Do/Redo", or "Undo" operations over IAction instances. We have provided two useful implementations of the IAction interface: UndoRedoTypeDescriptor - wrapper around an object that tracks property changes, and UndoRedoList - wrapper around the IList that tracks collection modifications. Users may create their implementations of the IAction to handle other undo and redo activities.
We have created a sample application to show undo and redo in action. You can download it from here.
We're building a .NET 2.0 GUI application. A part of a project is a localization. According to advices of msdn we have created *.resx files and sent them to foreign team that performs localization using WinRes tool.
Several of our user controls contained SplitContainer control. We never thought this could present a problem. Unfortunately it is!
When you're trying to open resx for a such user control you're getting:
Eror - Failed to load the resource due to the following error:
System.MissingMethodException: Constructor on type 'System.Windows.Forms.SplitterPanel' not found.
We started digging the WinRes.exe (thanks to .NET Reflector) and found the solution: we had to define the name of split container the way that its parent name appeared before (in ascending sort order) than splitter itself.
Say if you have a form "MyForm" and split container "ASplitContainer" then you should rename split container to say "_ASplitContainer". In this case resources are stored as:
| Name |
Parent Name |
| MyForm |
|
| _ASplitContainer |
MyForm |
| _ASplitContainer.Panel1 |
_ASplitContainer |
| _ASplitContainer.Panel2 |
_ASplitContainer |
This makes WinRes happy. 
Today we had spent some time looking for samples of web-services in RPC/encoded style, and we have found a great site http://www.xmethods.com/. This site contains a lot of web-services samples in Document/literal and RPC/encoded styles. We think this link will be useful for both developers and testers.
Actually this build is used WSE 2.0 SP3 and contains minor bug fixes. All the sources published on GotDotNet site (SCCBridge workspace). Pay attention that for now the sources include SCCProvider project that is MSSCCI implementation. I've decided to publish this project since Microsoft freely publish their interface and documentation for all VSIP.
As I wrote early in our blog, the latest version SCCBridge allows accessing to SCCBridge server via proxy. Here is some explanation what you should do in order to establish such connection:
1) open RepositoryExplorer;
2) click “Settings” button;
3) set “Default service URL” property to “http://proxy:1234/BridgeServer/Repository.asmx” ;
4) set “Endpoint URL” to “http://serverhost/BridgeServer/Repository.asmx”;
5) click “OK”.
Now you can do login.
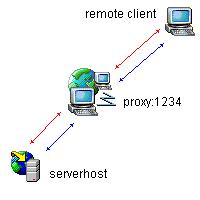
P.S. Pay attention that “serverhost” is a host name used by proxy to route requests to.
Yesterday we had ran into following problem: how to retrieve session object from within Java web-service? The crucial point of the problem was that we are generating automatically our web-service from Java bean and this web-service works under WebSphere v5.1.1.
After some time we had spent to find acceptable solution, we have found that it's possible either to implement “session substitution” using EJB SessionBean or somehow to retrieve HttpSession instance.
The first approach has a lot of advantages before the second one, but it requires to implement bunch of EJB objects (session bean itself, home object etc.). The second approach just solve our problem for web-service via HTTP, and no more, but... it requires only few lines to be changed in Java bean code. This second approach is based on implementation of javax.xml.rpc.server.ServiceLifecyle interface for our Java bean. For details take a look at the following article: “Web services programming tips and tricks: Build stateful sessions in JAX-RPC applications“.
Actually, only two additional methods init() and destroy() were implemented. The init() method retrieves (during initialization) an ServletEndpointContext instance that is stored somewhere in private filed of the bean. Further the ServletEndpointContext.getHttpSession() is called in order to get HttpSession. So easy, so quickly - we just was pleased.
Eventually the SCCBridge project became really open source project. From now its sources (version 1.1.0.0) are accessible from GotDotNet site. Releases, documentation and some interesting things about the project you still can find here. Welcome to all developers who want to participate in advancing of this project.
Today the next version of SCCBridge server and client were published. Feel free to download them from our download page.
What's new in this version:
-
The access to Source Safe database is implemented using COM+ object. This approach allows to avoid problems with access to VSS database on the LAN and simplify configuration.
-
The more intelligent List command is implemented. It can retrieve list of files/folders without checking whether files are pinned. This accelerates the list retrieving up to 2-3 times.
- The folders tree caching in Repository Explorer is implemented.
-
The caching of files/folders info in source code control provider for Visual Studio .NET 2003 IDE is improved.
-
Source code control provider for IDE now doesn't require user's credentials for each project in the solution.
-
Source code control provider can open now solutions created with Source Safe.
- Fix: checkout during file editing in Repository Explorer.
-
History dialog allows to determine either a specified or whole history period to get history data.
-
Repository Explorer and source code control provider support the same configuration file now.
- FileSystemBridge is removed from the installation.
- Some security improvement is implemented:
-
From now the SCCBridge client supports Windows Integrated and Basic authentication.
- The ability to use IE non-dynamic proxy settings is implemented.
-
The endpoint URL is now implemented. This allows to use web service behind the routers and/or firewalls.
-
The SCCBridge client encrypts VSS user name, password and database before send them to the web service.
-
The user doesn't see projects when he doesn't have any right on it. The users' rights on projects can be determined by VSS Admin utility.
P.S. Comments and suggestions are welcome.
Yesterday I've came across an interesting article that compares different version control systems like CVS, SourceSafe and several others. Some information in this article is not correct, but anyway it's close to true. So, it will be very useful to study this comparison, if you are going to select a version control system to work with it.
Also, some time ago, I've found page, which describes third party products for Visual SourceSafe. This is an interesting collection of links to third party SourceSafe managers, GUI, scripts, remote control systems, add-ins and so on. Take a look at this collection...
|