Some time ago we were taking a part in a project where 95% of all sources are xslt
2.0. It was a great experience for us.
The interesting part is that we used xslt in areas we would never expect
it in
early 2000s. It crunched gigabytes of data in offline, while earlier we
generally sought xslt application in a browser or on a server as an engine to render the data.
Web applications (both .NET and java) are in our focus today, and it became hard
to find application for xslt or xquery.
Indeed, client side now have a very strong APIs: jquery, jqueryui, jsview,
jqgrid, kendoui, and so on. These libraries, and today's browsers cover
developer's needs in building managable applications. In contrast, a native
support of xslt (at least v2) does not exist in browsers.
Server side at present is seen as a set of web services. These services
support both xml and json formats, and implement a business logic only. It
would be a torture to try to write such a frontend in xslt/xquery. A server
logic itself is often dealing with a diversity of data sources like databases,
files (including xml files) and other.
As for a database (we primarily work with SQL Server 2008 R2), we think that all
communication should go through stored procedures, which implement all data
logic. Clearly, this place is not for xslt. However, those who know sql beyond
its basics can confirm that sql is very similar to xquery. More than that SQL
Server (and other databases) integrate xquery to work with xml data, and we do
use it extensively.
Server logic itself uses API like LINQ to manipulate with different data
sources. In fact, we think that one can build a compiler from xquery 3.0 to C#
with LINQ. Other way round compiler would be a whole different story.
The net result is that we see little place for xslt and xquery. Well, after all it's only a personal perspective on the subject.
The similar type of thing has happened to us with C++. As with xslt/xquery we
love C++ very much, and we fond of C++11, but at present we have no place in our
current projects for C++. That's pitty.
P.S. Among other things that play against xslt/xquery is that there is a shortage of people who know these languages, thus who can support such projects.
Several days ago we've arrived to the blog "Recursive
lambda expressions". There, author asks how to write a lambda expression
that calculates a factorial (only expression statements are allowed).
The problem by itself is rather artificial, but at times you feel an intellectual
pleasure solving such tasks by yourself. So, putting original blog post aside we
devised our answers. The shortest one goes like this:
- As C# lambda expression cannot refer to itself, so it have to receive itself as
a parameter, so:
factorial(factorial, n) = n <= 1 ? 1 : n * factorial(factorial, n - 1);
- To define such lambda expression we have to declare a delegate type that receives
a delegate of the same type:
delegate int Impl(Impl impl, int n);
Fortunately, C# allows this, but a workaround could be used even if it were not
possible.
- To simplify the reasoning we've defined a two-expression version:
Impl impl = (f, n) => n <= 1 ? 1 : n * f(f, n - 1);
Func<int, int> factorial = i => impl(impl, i);
- Finally, we've written out a one-expression version:
Func<int, int> factorial = i => ((Func<Impl,
int>)(f => f(f, i)))((f, n) => n <= 1 ? 1 : n * f(f, n - 1));
- The use is:
var f = factorial(10);
After that excercise we've returned back to original blog and compared
solutions.
We can see that author appeals to a set theory but for some reason his answer is
more complex than nesessary, but comments contain variants that analogous to our
answer.
Let's start from a distance.
We support a busy database for a customer. Customer's requirement (in fact,
state's requirement) is that the database should have audit logs. This
means that all important requests should be logged. These logs help both for the
offline security analysis, and for the database health monitoring.
Before the end of the last year we used SQL Server 2005, and then customer
has upgraded to SQL Server 2008 R2.
As
by design the database is accessed through Stored Procedures only, so the logging was done
using
a small SP that traced input parameters and execution time. The call to that SP
was inserted throughout the code of other SPs.
We expected SQL Server 2008 R2
to simplify the task, and to allow us to switch
the audit on and off on a fine grained level without the need to change a SP in
the production (see
Understanding
SQL Server Audit for details).
Unfortunatelly, we have almost immediately found that
the current audit implementation traces SP calls but does not store parameter values. This way, you can see that
there was a call "execute X @param1, @param2", but you
have no idea what values were passed. Internet search shows that this a known problem (see
SQL Server 2008 Database Audit on INSERT UPDATE and DELETE actual SQL and not
parameter values), which renders SQL Server Audit useless.
But nevertheless, looking at how can we simplify our hand-made audit we have found a
brilliant solution: "Light
weight SQL Server procedure auditing without using SQL Server auditing".
It's so simple, that it's a shame that we did not invent it ourselves!
The approach is to insert or remove tracing code automatically. Indeed, there is
nothing but data in the database, even the text of SP is only a data.
To automate it even more, we have defined a small table with names of procedures
and their log levels, and have defined a procedure "Log.SetLevel @level" to configure
all logging in one go. In addition we have simplified logging procedures and
tables, and started to store parameters in xml columns rather than in a
pipe-concatenated strings.
Now, to the negative SP execution times.
The logging code among other things measures current_timestamp at
the begin and at the end of the execution of SP. This helps us (as developers)
to monitor how database performs on a day to day basis, and to build many useful
statistics.
For example we can see that the duration of about 10% of untrivial selects is
0ms (execution time is under 1ms). This means that SQL Server is good at
data caching. But what is most interesting is that about 0.1% of requests have
negative duration!
You could speculate
on parallel or on out of order execution, but the paradox is
resolved when you look closely on a value of duration. It's always around of -7,200,000ms. No
one will assume that execution has ended two hours before it has started. So,
what does it mean -2 hours? Well, we live in (UTC+02:00) Jerusalem time zone. We think that UTC offset crawls somehow into the result. To prove our
hypothesis we would like to change time zone on sql servers, but customer won't agree on
such an experiment. 
This effect probably means that there is some hidden bug in SQL Server 2008 R2 that we cannot
reliably reproduce, but we can see that the datediff(ms,
start_timestamp, end_timestamp) may return negative value when it's known
that start_timestamp is acquired before end_timestamp.
Update: What a shame. During tunning of the original logging procedures we have changed type from datetime to datetime2, and calls from GETUTCDATE() to current_timestamp, except one place (default value in the table definition) where it remained with GETUTCDATE().
So, negative durations meant operation timeout (in our case duration is greater than 30 secs).
This time we
update csharpxom to adjust it to C# 4.5.
Additions are async modifier and
await operator.
They are used to simplify asynchronous programming.
The following example from
the msdn:
private async Task<byte[]> GetURLContentsAsync(string url)
{
var content = new MemoryStream();
var request = (HttpWebRequest)WebRequest.Create(url);
using(var response = await request.GetResponseAsync())
using(var responseStream = response.GetResponseStream())
{
await responseStream.CopyToAsync(content);
}
return content.ToArray();
}
looks like this in csharpxom:
<method name="GetURLContentsAsync" access="private" async="true">
<returns>
<type name="Task" namespace="System.Threading.Tasks">
<type-arguments>
<type name="byte" rank="1"/>
</type-arguments>
</type>
</returns>
<parameters>
<parameter name="url">
<type name="string"/>
</parameter>
</parameters>
<block>
<var name="content">
<initialize>
<new-object>
<type name="MemoryStream" namespace="System.IO"/>
</new-object>
</initialize>
</var>
<var name="request">
<initialize>
<cast>
<invoke>
<static-method-ref name="Create">
<type name="WebRequest" namespace="System.Net"/>
</static-method-ref>
<arguments>
<var-ref name="url"/>
</arguments>
</invoke>
<type name="HttpWebRequest" namespace="System.Net"/>
</cast>
</initialize>
</var>
<using>
<resource>
<var name="response">
<initialize>
<await>
<invoke>
<method-ref name="GetResponseAsync">
<var-ref name="request"/>
</method-ref>
</invoke>
</await>
</initialize>
</var>
</resource>
<using>
<resource>
<var name="responseStream">
<initialize>
<invoke>
<method-ref name="GetResponseStream">
<var-ref name="response"/>
</method-ref>
</invoke>
</initialize>
</var>
</resource>
<expression>
<await>
<invoke>
<method-ref name="CopyToAsync">
<var-ref name="responseStream"/>
</method-ref>
<arguments>
<var-ref name="content"/>
</arguments>
</invoke>
</await>
</expression>
</using>
</using>
<return>
<invoke>
<method-ref name="ToArray">
<var-ref name="content"/>
</method-ref>
</invoke>
</return>
</block>
</method>
After C++11 revision has been approved a new cycle of C++ design has begun:
N3370:
The C++ standards committee is soliciting proposals for additional library components.
Such proposals can range from small (addition of a single signature to an existing
library) to large (something bigger than any current standard library component).
At this stage it's interesting to read papers, as authors try to express ideas
rather than to formulate sentences that should go into spec as it lately was.
These are just several papers that we've found interesting:
|
N3322
|
12-0012
|
A Preliminary Proposal for a Static if
|
Walter E. Brown
|
|
N3329
|
12-0019
|
Proposal: static if declaration
|
H. Sutter, W. Bright, A. Alexandrescu
|
Those proposals argue about compile time "if statement". The feature can replace #if preprocessor
directive, a SFINAE or in some cases template specializations.
A static if declaration can appear wherever a declaration or a statement is
legal.
Authors also propose to add static if clause to a class and a function declarations
to conditionally exclude them from the scope.
Examples:
// Compile time factorial.
template <unsigned n>
struct factorial
{
static if (n <= 1)
{
enum : unsigned { value = 1 };
}
else
{
enum : unsigned { value = factorial<n - 1>::value * n };
}
};
// Declare class provided a condition is true.
class Internals if (sizeof(void*) == sizeof(int));
Paper presents strong rationale why this addition helps to build better
programs, however the questions arise about relations between static if
and concepts, static if clause and an error diagnostics.
|
N3327 |
12-0017 |
A Standard Programmatic Interface for Asynchronous Operations |
N. Gustafsson, A. Laksberg |
|
N3328 |
12-0018 |
Resumable Functions |
Niklas Gustafsson |
That's our favorite.
Authors propose an API and a language extensions to make asynchronous programs
simpler.
In fact, asynchronous function will look very mush as a regular one but with small
additions. It's similar to yield return in C# (a
construct that has been available in C# for many years and is well vetted),
and to async expression in C# 4.5. Compiler will rewrite such a
function into a state machine, thus function can suspend its execution, wait
for the data and to resume when data is available.
Example:
// read data asynchronously from an input and
write it into an output.
int cnt = 0;
do
{
cnt = await streamR.read(512, buf);
if (cnt == 0)
{
break;
}
cnt = await streamW.write(cnt, buf);
}
while(cnt > 0);
It's iteresting to see how authors will address yield return: either with
aditional keyword, or in terms of resumable functions.
|
N3340 |
12-0030 |
Rich Pointers |
D. M. Berris, M. Austern, L. Crowl |
Here authors try to justify rich type-info but mask it under the
name "rich pointers". To make things even more obscure they argue about dynamic code
generation.
If you want a rich type-info then you should talk about it and not about thousand
of other things.
We would better appealed to create a standard API to access post-compile object
model, which could be used to produce different type-infos or other source
derivatives.
This paper is our outsider. :-)
|
N3341 |
12-0031 |
Transactional Language Constructs for C++ |
M. Wong, H. Boehm, J. Gottschlich, T. Shpeisman, et al. |
Here people try to generalize (put you away from) locking, and replace it with
other word "transaction".
Seems it's not viable proposition. It's better to teach on functional style of
programming with its immutable objects.
|
N3347 |
12-0037 |
Modules in C++ (Revision 6) |
Daveed Vandevoorde |
Author argues against C style source composition with #include
directive, and propose alternative called "modules".
We think that many C++ developers would agree that C pre-processor is a legacy that
would never have existed, but for the same reason (for the legacy, and compatibility) it
should stay.
In out opinion the current proposition is just immature, at least it's not
intuitive. Or in other words there should be something to replace the C
pre-processor (and #include as its part), but we don't like this
paper from aestetic perspective.
|
N3365 |
12-0055 |
Filesystem Library Proposal (Revision 2) |
This proposal says no a word about asynchronous nature of file access, while it
should be designed around it.
For a long time we were developing web applications with ASP.NET and JSF. At
present we prefer rich clients and a server with page templates and RESTful web
services.
This transition brings technical questions. Consider this one.
Browsers allow to store session state entirely on the client, so should we
maintain a session on the server?
Since the server is just a set of web services, so we may supply all required
arguments on each call.
At first glance we can assume that no session is required on the server.
However, looking further we see that we should deal with data validation
(security) on the server.
Think about a classic ASP.NET application, where a user can select a value from
a dropdown. Either ASP.NET itself or your program (against a list from a
session) verifies that the value received is valid for the user. That list of
values and might be other parameters constitute a user profile, which we stored
in session. The user profile played important role (often indirectly) in the
validation of input data.
When the server is just a set of web services then we have to validate all
parameters manually. There are two sources that we can rely to: (a)
a session, (b)
a user principal.
The case (a) is very similar to classic ASP.NET application except that with
EnableEventValidation="true" runtime did it for us most of the time.
The case (b) requires reconstruction of the user profile for a user principal
and then we proceed with validation of parameters.
We may cache user profile in session, in which case we reduce (b) to (a); on the
other hand we may cache user profile in
Cache, which is also similar to (a) but which might be lighter than (at least not
heavier than) the solution with the session.
What we see is that the client session does not free us from server session (or
its alternative).
We were dealing with a datasource of (int? id, string
value) pairs in LINQ. The data has originated from a database where id is unique field.
In the program this datasource had to be seen as a dictionary, so we have
written a code like this:
var dictionary =
CreateIDValuePairs().ToDictionary(item => item.ID, item => item.Value);
That was too simple-minded. This code compiles but crashes at runtime when there is an id == null.
Well, help warns about this behaviour, but anyway this does not make pain easier.
In our opinion this restriction is not justified and just complicates the use
of Dictionaty.
A customer have a table with data stored by dates, and asked us to present data
from this table by sequential date ranges.
This query sounded trivial but took us half a day to create such a select.
For simplicity consider a table of integer numbers, and try to build a select
that returns pairs of continuous ranges of values.
So, for an input like this:
declare @values table
(
value int not null primary key
);
insert into @values(value)
select 1
union all
select 2
union all
select 3
union all
select 5
union all
select 6
union all
select 8
union all
select 10
union all
select 12
union all
select 13
union all
select 14;
You will have a following output:
low high
---- ----
1 3
5 6
8 8
10 10
12 14
Logic of the algorithms is like this:
- get a low bound of each range (a value without value - 1 in the source);
- get a high bound of each range (a value without value + 1 in the source);
- combine low and high bounds.
Following this logic we have built at least three different queries, where the
shortest one
is:
with source as
(
select * from @values
)
select
l.value low,
min(h.value) high
from
source l
inner join
source h
on
(l.value - 1 not in (select value from source)) and
(h.value + 1 not in (select value from source)) and
(h.value >= l.value)
group by
l.value;
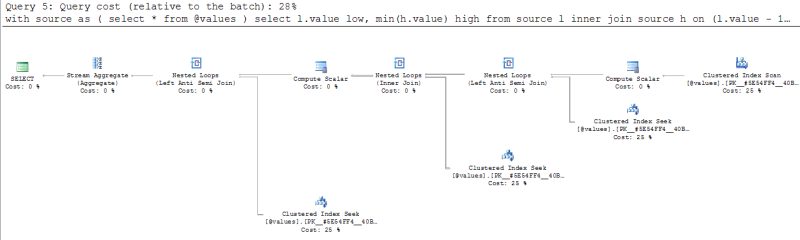
Looking at this query it's hard to understand why it took so
long to
write so simple code...
Some time ago our younger brother Aleksander had started studying of cinematography.
Few days ago he started his own "multimedia" blog (you'll better understand me when you'll see it), where you can see his portfolio. Aleksander's latest work was made with cooperation with Ilan Lahov, see "Bar mitzvah". This work demonstrates Aleksander's progress in this field.
Our congratulations to Aleksander!
If you're writing an application that deals with files in file system on Windows, be sure that sooner or later you run into problems with antivirus software.
Our latest program that handles a lot of huge files and works as a Windows service, it reports time to time about some strange errors. These errors look like the file system disappeared on the fly, or, files were stolen by somebody else (after they have been opened in exclusive mode by our application).
We spent about two weeks in order to diagnose the cause of such behaviour, and then came to conclusion that is a secret work of our antivirus. All such errors disappeared as fog when the antivirus was configurated to skip folders with our files.
Thus, keep in mind our experience and don't allow an ativirus to became an evil.
While looking at some SQL we have realized that it can be considerably optimized.
Consider a table source like this:
with Data(ID, Type, SubType)
(
select 1, 'A', 'X'
union all
select 2, 'A', 'Y'
union all
select 3, 'A', 'Y'
union all
select 4, 'B', 'Z'
union all
select 5, 'B', 'Z'
union all
select 6, 'C', 'X'
union all
select 7, 'C', 'X'
union all
select 8, 'C', 'Z'
union all
select 9, 'C', 'X'
union all
select 10, 'C', 'X'
)
Suppose you want to group data by type, to calculate number of elements in each
group and to display sub type if all rows in a group are of the same sub type.
Earlier we have written the code like this:
select
Type,
case when count(distinct SubType) = 1 then min(SubType) end SubType,
count(*) C
from
Data
group by
Type;
Namely, we select min(SybType) provided that there is a single distinct
SubType, otherwise null is shown. That works perfectly,
but algorithmically count(distinct SubType) = 1 needs to build a set
of distinct values for each group just to ask the size of this set. That is
expensive!
What we wanted can be expressed differently: if min(SybType) and
max(SybType) are the same then we want to display it, otherwise to show
null.
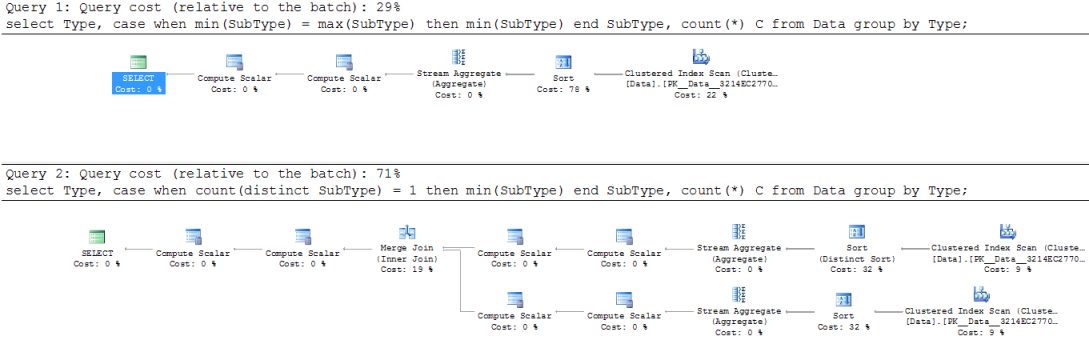
That's the new version:
select
Type,
case when min(SubType) = max(SubType) then min(SubType) end SubType,
count(*) C
from
Data
group by
Type;
Such a simple rewrite has cardinally simplified the execution plan:
Another bizarre problem we have discovered is that SQL Server 2008 R2 just does
not support the following:
select
count(distinct SubType) over(partition by Type)
from
Data
That's really strange, but it's known bug (see
Microsoft Connect).
A database we support for a client contains multi-billion row tables. Many
users query the data from that database, and it's permanently populated
with a new data.
Every day we load several millions rows of a new data. Such loads can lock tables for a
considerable time, so our loading procedures collect new data into intermediate
tables and insert it into a final destination by chunks, and usually after work
hours.
SQL Server 2008 R2 introduced
READ_COMMITTED_SNAPSHOT database option. This feature trades locks for an
increased tempdb size (to store row versions) and possible performance
degradation during a transaction.
When we have switched the database to that option we did
not notice any considerable performance change. Encouraged, we've decided to
increase size of chunks of data we insert at once.
Earlier we have found that when we insert no more than 1000 rows
at once, users don't notice impact, but for a bigger chunk sizes users start to
complain on performance degradation. This has probably happened due to locks
escalations.
Now, with chunks of 10000 or even 100000 rows we have found that no queries
became slower. But load process became several times faster.
We were ready to pay for increased tempdb and transaction log size to increase
performance, but in our case we didn't approach limits assigned by the DBA.
Another gain is that we can easily load data at any time. This makes data we
store more up to date.
Yesterday, by accident, we've seen an article about some design principles
of V8 JavaScript Engine.
It made clearer what techniques are used in today's script implementations.
In particular V8 engine optimizes property access using "dynamically
created
hidden classes". These are structures to store object's layout, they
are derived when ש new property is created (deleted) on the object. When code
accesses a property, and if a cached object's dynamic hidden class is available
at the code point then access time is comparable to one of native fields.
In our opinion this tactics might lead to a proliferation of such dynamic hidden
classes, which requires a considerable housekeeping, which also slows property
write access, especially when it's written for the first time.
We would like to suggest a slightly different strategy, which exploits the
cache matches, and does not require a dynamic hidden classes.
Consider an implementation data type with following characteristics:
- object is implemented as a hash map of property id to property value: Map<ID, Value>;
- it stores data as an array of pairs and can be accessed directly: Pair<ID,
Value> values[];
- property index can be acquired with a method: int index(ID);
A pseudo code for the property access looks like this:
pair = object.values[cachedIndex];
if (pair.ID == propertyID)
{
value = pair.Value;
}
else
{
// Cache miss.
cachedIndex = object.index(propertyID);
value = objec.values[cachedIndex].Value;
}
This approach brings us back to dictionary like implementation but with
important optimization of array speed access when property index is cached, and
with no dynamic hidden classes.
@michaelhkay Saxon 9.4 is out.
But why author does not state that HE version is still xslt/xpath 2.0, as neither xslt maps, nor function items are supported.
Recently, we have found and reported the bug in the SQL Server 2008 (see SQL Server 2008 with(recompile), and also Microsoft Connect).
Persons, who's responsible for the bug evaluation has closed it, as if "By Design". This strange resolution, in our opinion, says about those persons only.
Well, we shall try once more (see Microsoft Connect). We have posted another trivial demonstartion of the bug, where we show that option(recompile) is not used, which leads to table scan (nothing worse can happen for a huge table).
|