Recently we've read an article
"A Proposal for XSLT 4.0", and thought it worth to suggest one more idea. We have written a message to Michael Kay, author of this proposal. Here it is:
A&V
Historically xslt, xquery and xpath were dealing with trees. Nowadays it became much common to process graphs. Many tasks can be formulated in terms of graphs, and in particular any task processing trees is also graph task.
I suggest to take a deeper look in this direction.
As an inspiration I may suggest to look at "P1709R2: Graph Library" - the C++ proposal.
Michael Kay
I have for many years found it frustrating that XML is confined to hierarchic relationships (things like IDREF and XLink are clumsy workarounds); also the fact that the arbitrary division of data into "documents" plays such a decisive role: documents should only exist in the serialized representation of the model, not in the model itself.
I started my career working with the Codasyl-defined network data model. It's a fine and very flexible data model; its downfall was the (DOM-like) procedural navigation language. So I've often wondered what one could do trying to re-invent the Codasyl model in a more modern idiom, coupling it with an XPath-like declarative access language extended to handle networks (graphs) rather than hierarchies.
I've no idea how close a reinventiion of Codasyl would be to some of the modern graph data models; it would be interesting to see. The other interesting aspect of this is whether you can make it work for schema-less data.
But I don't think that would be an incremental evolution of XSLT; I think it would be something completely new.
A&V
I was not so radical in my thoughts. 
Even C++ API is not so radical, as they do not impose hard requirements on internal graph representation but rather define template API that will work both with third party representations (they even mention Fortran) or several built-in implementations that uses standard vectors.
Their strong point is in algorithms provided as part of library and not graph internal structure (I think authors of that paper have structured it not the best way). E.g. in the second part they list graph algorithms: Depth First Search (DFS); Breadth First Search (BFS); Topological Sort (TopoSort); Shortest Paths Algorithms; Dijkstra Algorithms; and so on.
If we shall try to map it to xpath world them graph on API level might be represented as a user function or as a map of user functions.
On a storage level user may implement graph using a sequence of maps or map of maps, or even using xdm elements.
So, my approach is evolutional. In fact I suggest pure API that could even be implemented now.
Michael Kay
Yes, there's certainly scope for graph-oriented functions such as closure($origin, $function) and is-reachable($origin, $function) and find-path($origin, $destination, $function) where we use the existing data model, treating any item as a node in a graph, and
representing the arcs using functions. There are a few complications, e.g. what's the identity comparison between arbitrary items, but it can probably be done.
A&V
> There are a few complications, e.g. what's the identity comparison between arbitrary items, but it can probably be done.
One approach to address this is through definition of graph API. E.g. to define graph as a map (interface analogy) of functions, with equality functions, if required:
map
{
vertices: function(),
edges: function(),
value: function(vertex),
in-vertex: function(edge),
out-vertex: function(edge),
edges: function(vertex),
is-in-vertex: function(edge, vertex),
is-out-vertex: function(edge, vertex)
...
}
Not sure how far this will go but who knows.
It's not a secret that COVID-19 epidemic will change our world significantly.
 It impacts on economics and public services, especially on social services of our countries.
We saw this in our country and now the same happens in US.
Probably the same thing happens in all countries all over the world that suffer from COVID-19. It impacts on economics and public services, especially on social services of our countries.
We saw this in our country and now the same happens in US.
Probably the same thing happens in all countries all over the world that suffer from COVID-19.
Usually, nowadays, such services are exposed online, but nobody expected such extreme loading of these services.
And they start molder under such load. Programs start crash... and somebody has to fix them.
It's just a temporary technical inconvenience when there is staff that familiar with such programs and technologies,
but what about situation when programs and technologies are obsolete?
When staff that may support them are about to retire due to ages, when knowledge were almost lost...
It's very scary when such applications rules very important spheres of our life such social services, finances, medicine, defence etc.
Something similar happened in US, so US government asked IBM about a help with their stuff written in COBOL.
Probably, in short term, they'll close the gaps, but taking in account the fact that epidemic won't dissolve in a month,
there is a risk to still in the same hole... There are two ways to solve this issue in long term:
- to make COBOL widely used program language and to teach enough programmers that will use it. This is exactly what IBM tries to do,
see this article,
but this way to nowhere, since it is not too popular in society of software developers.
- to migrate such application to new technologies and new platform (e.g. Java or C# on UNIX/Windows). In this case organizations obtain
scalable applications and ability to find human resources that may fix/modernize such applications step by step, in spare time,
without loosing existing functionality. This is what our company Advanced may provide.
And we are not alone. There are many such companies that may implement such migration on high level of quality.
And many professionals (even those that deal with COBOL on day by day basis) think that only 2nd way is viable. Let's see what will happen...
More about the issue, see here.
People compare these two technologies, and it seems an established fact is that Angular is evolutionally more advanced framework. We're not going to contradict, contrary, we agree with it, but it's better for an opinion to be grounded on facts that one can evaluate and verify.
Fortunately we got a chance to make such a comparison.
We support conversions of Cool:GEN (a legacy CASE tool with roots in 80th) to java or C#. In its time Cool:GEN allowed to greatly automate enterprise development using Mainframes as a server side and Mainframe terminals or Win32 GUIs as clients.
The legacy of this tool are probably hundreds of business and database models, milions of programs generated on COBOL on Mainframes and on C or Java on Windows and Linux. All this runs to this time in many econimic sectors.
Usually the client is some enterprise that invested a lot into design, development and support of their business model using Cool:GEN but now most such clients a trying not to lose this legacy but to convert it into something that goes in parallel with todays technologies.
As original technology is sound, so it is possible to map it to todays Java or C# on server, REST or SOAP as a transport, and Angular, AngularJS or some other on client. Such automatic conversion is an essense of our conversions efforts.
To understand a scope consider a typical enterprise client that has 2-3 thousand windows that are backed by 20-30 thousand programs.
Now, consider that the conversion is done. On output among other things we produce a clean java or C# web application with REST and SOAP interface, and Angular or AngularJS web client that encapsulates those 2-3 thousand windows.
Each window definition is rather small 5-10 KB in html form, but whole mass of windows takes 10-30 MB, which is not small any more.
For AngularJS we generate just those html templates, but for Angular we need to generate separate components for each window that includes typescript class, template and style.
While amout of generated resource for AngularJS stays in those 10-30 MB, generated Angular takes at least 5-10 MB more.
The next step is build.
AngularJS builds distribution that includes all used libraries and a set of templates, and it takes something like a minute from the CPU. Produced output is about 300 KB minified script and those 10-30 MB of templates (multiple files with 5-10 KB each one).
Angular (here we talk about version 9) builds distribution that includes all used libraries and a set of compiled components that are to be loaded lazily on demand. Without of the both angular builder that performs tree shaking build takes days. With tree shaking off it takes 40 minutes. This is the first notable difference. Produced output for ES2015 (latest javascript) is about 1 MB, and 15-100 KB per each compiled component. This is the second notable difference that already impacts end user rather than developer.
The third difference is in the end user experience. Though we have built equalvalent Angular and AngularJS frontend we observe load time of angular is higher. This cannot only be ascribed to bigger file sizes. It seems internal initialization also takes more time for Angular.
So, our experience in this particular test shows that Angular has more room to improve. In particular: compile time, bundle size, runtime speed and simplicity of dynamic loading (we have strong cases when template compilation is not the best approach).
Yesterday we run into another Saxon bug. See NPE in CaseVariants.
The problem happened just once and never reproduced. Inspection of Saxon sources hinted that it can be a race condition.
Michael Kay agreed with our conclusion and fixed the problem in the code along with several other similar places.
It is such rare kind of bug that it might appear once during whole product life cycle. So, we may consider the fix is personal.
We were asked to help with search service in one enterprise. We were told that their SharePoint portal does not serve their need. Main complaints were about the quality of search results.
They have decided to implement external index of SharePoint content, using Elastic, and expose custom search API within the enterprise.
We questioned their conclusions, asked why did they think Elastic will give much better results, asked did they try to figure out why SharePoint give no desired results.
Answers did not convince us though we have joined the project.
What do you think?
Elastic did not help at all though they hoped very much that its query language will help to rank results in a way that matched documents will be found.
After all they thought it was a problem of ranking of results.
Here we have started our analysis. We took a specific document that must be found but is never returned from search.
It turned to be well known problem, at least we dealt with closely related one in the past. There are two ingredients here:
- documents that have low chances to be found are PDFs;
- we live in Israel, so most texts are Hebrew, which means words are written from right to left, while some other texts from left to right. See Bi-directional text.
Traditionally PDF documents are provided in a way that only distantly resembles logical structure of original content. E.g., paragraphs of texts are often represented as unrelated runs of text lines, or as set of text runs representing single words, or independant characters. No need to say that additional complication comes from that Hebrew text are often represented visually (from left to right, as if "hello" would be stored as "olleh" and would be just printed from right to left). Another common feature of PDF are custom fonts with uncanonical mappings, or images with glyphs of letters.
You can implement these tricks in other document formats but for some reason PDF is only format we have seen that regularly and intensively uses these techniques.
At this point we have realized that it's not a fault of a search engine to find the document but the feature of the PDF to expose its text to a crawler in a form that cannot be used for search.
In fact, PDF cannot search by itself in such documents, as when you try to find some text in the document opened in a pdf viewer, that you clearly see in the document, you often find nothing.
A question. What should you do in this case when no any PDF text extractor can give you correct text but text is there when you looking at document in a pdf viewer?
We decided it's time to go in the direction of image recognition. Thankfully, nowdays it's a matter of available processing resources.
Our goal was:
- Have images of each PDF page. This task is immediately solved with Apache PDFBox (A Java PDF Library) - it's time to say this is java project.
- Run Optical Character Recognition (OCR) over images, and get extracted texts. This is perfectly done by tesseract-ocr/tesseract, and thankfully to its java wrapper bytedeco/javacpp-presets we can immediately call this C++ API from java.
The only small nuisance of tesseract is that it does not expose table recognition info, but we can easily overcome it (we solved this task in the past), as along with each text run tesseract exposes its position.
What are results of the run of such program?
- Full success! It works with high quality of recognition. Indeed, there is no any physical noise that impacts quality.
- Slow speed - up to several seconds per recognition per page.
- Scalable solution. Slow speed can be compensated by almost unlimited theoretical scalability.
So, what is the lesson we have taked from this experience?
Well, you should question yourself, test and verify ideas on the ground before building any theories that will lead you in completely wrong direction. After all people started to realize there was no need to claim on SharePoint, to throw it, and to spend great deal of time and money just to prove that the problem is in the different place.
A sample source code can be found at App.java
This story started half year ago when Michael Kay, author of Saxon XSLT processor, was dealing with performance in multithreaded environment. See Bug #3958.
The problem is like this.
Given XSLT:
<xsl:stylesheet exclude-result-prefixes="#all"
version="3.0"
xmlns:saxon="http://saxon.sf.net/"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" />
<xsl:template name="main">
<xsl:for-each saxon:threads="4" select="1 to 10">
<xsl:choose>
<xsl:when test=". eq 1">
<!-- Will take 10 seconds -->
<xsl:sequence select="
json-doc('https://httpbin.org/delay/10')?url"/>
</xsl:when>
<xsl:when test=". eq 5">
<!-- Will take 9 seconds -->
<xsl:sequence select="
json-doc('https://httpbin.org/delay/9')?url"/>
</xsl:when>
<xsl:when test=". eq 10">
<!-- Will take 8 seconds -->
<xsl:sequence select="
json-doc('https://httpbin.org/delay/8')?url"/>
</xsl:when>
</xsl:choose>
</xsl:for-each>
<xsl:text>
</xsl:text>
</xsl:template>
</xsl:stylesheet>
Implement engine to achieve best performance of parallel for-each.
Naive implementation that will distribute iterations per threads will run into unfair load on threads, so some load-balancing is required. That was the case Saxon EE.
Michael Kay has been trying to find most elegant way for the implementation and has written the comment:
I can't help feeling that the answer to this must lie in using the Streams machinery, and Spliterators in particular. I've spent another hour or so reading all about Spliterators, and I have to confess I really don't understand the paradigm. If someone can enlighten me, please go ahead...
We have decided to take the challange and to model the expected behavior using Streams. Here is our go:
import java.util.stream.IntStream;
import java.util.stream.Stream;
import java.util.function.Consumer;
import java.util.function.Function;
public class Streams
{
public static class Item<T>
{
public Item(int index, T data)
{
this.index = index;
this.data = data;
}
int index;
T data;
}
public static void main(String[] args)
{
run(
"Sequential",
input(),
Streams::action,
Streams::output,
true);
run(
"Parallel ordered",
input().parallel(),
Streams::action,
Streams::output,
true);
run(
"Parallel unordered",
input().parallel(),
Streams::action,
Streams::output,
false);
}
private static void run(
String description,
Stream<Item<String>> input,
Function<Item<String>, String[]> action,
Consumer<String[]> output,
boolean ordered)
{
System.out.println(description);
long start = System.currentTimeMillis();
if (ordered)
{
input.map(action).forEachOrdered(output);
}
else
{
input.map(action).forEach(output);
}
long end = System.currentTimeMillis();
System.out.println("Execution time: " + (end - start) + "ms.");
System.out.println();
}
private static Stream<Item<String>> input()
{
return IntStream.range(0, 10).
mapToObj(i -> new Item<String>(i + 1, "Data " + (i + 1)));
}
private static String[] action(Item<String> item)
{
switch(item.index)
{
case 1:
{
sleep(10);
break;
}
case 5:
{
sleep(9);
break;
}
case 10:
{
sleep(8);
break;
}
default:
{
sleep(1);
break;
}
}
String[] result = { "data:", item.data, "index:", item.index + "" };
return result;
}
private synchronized static void output(String[] value)
{
boolean first = true;
for(String item: value)
{
if (first)
{
first = false;
}
else
{
System.out.print(' ');
}
System.out.print(item);
}
System.out.println();
}
private static void sleep(int seconds)
{
try
{
Thread.sleep(seconds * 1000);
}
catch(InterruptedException e)
{
throw new IllegalStateException(e);
}
}
}
We model three cases:
- "Sequential"
- slowest, single threaded execution with output:
data: Data 1 index: 1
data: Data 2 index: 2
data: Data 3 index: 3
data: Data 4 index: 4
data: Data 5 index: 5
data: Data 6 index: 6
data: Data 7 index: 7
data: Data 8 index: 8
data: Data 9 index: 9
data: Data 10 index: 10
Execution time: 34009ms.
- "Parallel ordered"
- fast, multithread execution preserving order, with output:
data: Data 1 index: 1
data: Data 2 index: 2
data: Data 3 index: 3
data: Data 4 index: 4
data: Data 5 index: 5
data: Data 6 index: 6
data: Data 7 index: 7
data: Data 8 index: 8
data: Data 9 index: 9
data: Data 10 index: 10
Execution time: 10019ms.
- "Parallel unordered"
- fastest, multithread execution not preserving order, with output:
data: Data 6 index: 6
data: Data 2 index: 2
data: Data 4 index: 4
data: Data 3 index: 3
data: Data 9 index: 9
data: Data 7 index: 7
data: Data 8 index: 8
data: Data 5 index: 5
data: Data 10 index: 10
data: Data 1 index: 1
Execution time: 10001ms.
What we can add in conclusion is that xslt engine could try automatically decide what approach to use, as many SQL engines are doing, and not to force developer to go into low level engine details.
Recently we observed how we solved the same task in different versions of XPath: 2.0, 3.0, and 3.1.
Consider, you have a sequence $items, and you want to call some function over each item of the sequence, and to return combined result.
In XPath 2.0 this was solved like this:
for $item in $items return
f:func($item)
In XPath 3.0 this was solved like this:
$items!f:func(.)
And now with XPath 3.1 that defined an arrow operator => we attempted to write something as simple as:
$items=>f:func()
That is definitely not working, as it is the same as f:func($items).
Next attempt was:
$items!=>f:func()
That even does not compile.
So, finally, working expression using => looks like this:
$items!(.=>f:func())
This looks like a step back comparing to XPath 3.0 variant.
More than that, XPath grammar of arrow operator forbids the use of predictes, axis or mapping operators, so this won't compile:
$items!(.=>f:func()[1])
$items!(.=>f:func()!something)
Our conclusion is that arrow operator is rather confusing addition to XPath.
Xslt 3.0 defines a feature called streamability: a technique to write xslt code that is able to handle arbitrary sized inputs.
This contrasts with conventional xslt code (and xslt engines) where inputs are completely loaded in memory.
To make code streamable a developer should declare her code as such, and the code should pass Streamability analysis.
The goal is to define subset of xslt/xpath operations that allow to process input in one pass.
In simple case it's indeed a simple task to verify that code is streamable, but the more complex your code is the less trivial it's to witness it is streamable.
On the forums we have seen a lot of discussions, where experts were trying to figure out whether particular xslt is streamable. At times it's remarkably untrivial task!
This, in our opinion, clearly manifests that the feature is largerly failed attempt to inscribe some optimization technique into xslt spec.
The place of such optimization is in the implementation space, and not in spec. Engine had to attempt such optimization and fallback to the traditional implementation.
The last such example is: Getting SXST0060 "No streamable path found in expression" when trying to push a map with grounded nodes to a template of a streamable mode, where both xslt code and engine developers are not sure that the code is streamable in the first place.
By the way, besides streamability there is other optimization technique that works probably in all SQL engines. When data does not fit into memory engine may spill it on disk. Thus trading memory pressure for disk access. So, why didn't such techninque find the way into the Xslt or SQL specs?
After 17 years of experience we still run into dummy bugs in xslt (xpath in fact).
The latest one is related to order of nodes produced by ancestor-or-self axis.
Consider the code:
<xsl:stylesheet version="3.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<xsl:variable name="data" as="element()">
<a>
<b>
<c/>
</b>
</a>
</xsl:variable>
<xsl:variable name="item" as="element()" select="($data//c)[1]"/>
<xsl:message select="$item!ancestor-or-self::*!local-name()"/>
<xsl:message select="$item!local-name(), $item!..!local-name(), $item!..!..!local-name()"/>
</xsl:template>
</xsl:stylesheet>
We expected to have the following outcome
But correct one is
Here is why:
ancestor-or-self::* is an AxisStep. From XPath §3.3.2:
[Definition: An axis step returns a sequence of nodes that are reachable from the context node via a specified axis. Such a step has two parts: an axis, which defines the "direction of movement" for the step, and a node test, which selects nodes based on their kind, name, and/or type annotation.] If the context item is a node, an axis step returns a sequence of zero or more nodes; otherwise, a type error is raised [err:XPTY0020]. The resulting node sequence is returned in document order.
For some reason we were thinking that reverse axis produces result in reverse order. It turns out the reverse order is only within predicate of such axis.
See more at https://saxonica.plan.io/boards/3/topics/7312
XPath 3 has introduced a syntactic sugar for a string concatenation, so following:
concat($a, $b)
can be now written as:
$a || $b
This is nice addition, except when you run into a trouble. Being rooted in C world we unintentionally have written a following xslt code:
<xsl:if test="$a || $b">
...
</xsl:if>
Clearly, we intended to write $a or $b. In contrast $a || $b is evaluated as concat($a, $b). If both variables are false() we get 'falsefalse' outcome, which has effective boolean value true(). This means that test condition of xsl:if is always true().
What can be done to avoid such unfortunate typo, which is manifested in no way neither during compilation nor during runtime?
The answer is to issue informational message during the compilation, e.g. if result of || operator is converted to a boolean, and if its arguments are booleans also then chances are high this is typo, and not intentional expression.
We adviced to implement such message in the saxon processor (see https://saxonica.plan.io/boards/3/topics/7305).
It seems we've found discrepancy in regex implementation during the transformation in Saxon.
Consider the following xslt:
<xsl:stylesheet version="3.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<xsl:variable name="text" as="xs:string"
select="'A = "a" OR B = "b"'"/>
<xsl:analyze-string regex=""(\\"|.)*?"" select="$text">
<xsl:matching-substring>
<xsl:message>
<xsl:sequence select="regex-group(0)"/>
</xsl:message>
</xsl:matching-substring>
</xsl:analyze-string>
</xsl:template>
</xsl:stylesheet>
vs javascript
<html>
<body>
<script>
var text = 'A = "a" OR B = "b"';
var regex = /"(\\"|.)*?"/;
var match = text.match(regex);
alert(match[0]);
</script>
</body>
</html>
xslt produces: "a" OR B = "b"
while javascript: "a"
What is interesting is that we're certain this was working correctly in Saxon several years ago.
You can track progress of the bug at: https://saxonica.plan.io/boards/3/topics/7300 and at https://saxonica.plan.io/issues/3902.
For more than 25 years continues a discussion in C++ community about exceptions.
In our opinion this can only be compared with math community and their open problems like Hilbert's 23 problems dated by 1900.
In essence C++ exception discussion is about efficiency of exceptions vs status codes. This problem is not so acute in other languages (like java or C#) because those languages postulate different goals.
C++ designers have introduced a zero-overhead principle for any language feature, which is:
- If you don’t use some feature you don’t pay for it.
- If you do use it you cannot (reasonably) write it more efficiently by hand.
Exceptions comparing to status codes do not withstand this demand. This led to the fragmentation of C++ comunity where many big projects and code styles ban exceptions partially or completely.
Make no doubt that all this time people were trying to make exceptions better, and have found techniques to make them space and run time efficient to some extent, but still, old plain status codes outperform both in speed (especially in predictability of time of exception handling logic) and in code size.
We guess the solution is finally found after the quarter the century of discussion!
WG paper: Zero-overhead deterministic exceptions: Throwing values by Herb Sutter. This "paper aims to extend C++’s exception model to let functions declare that they throw a statically specified type by value. This lets the exception handling implementation be exactly as efficient and deterministic as a local return by value, with zero dynamic or non-local overheads."
In other words author suggests to:
- extend
exception model (in fact implement additional one);
- make exceptions as fast and as predicable as status codes (which virtually means designate a status code as a new exception);
Here are author's arguments:
- Status code is usually just a number, and handling an error is like to perform some
if or switch statements.
- Handling errors with status codes is predicable in time and visible in the code though it burdens the logic very much.
- Exceptions give clear separation between a control flow and error handling.
- Exceptions are mostly invisible in the code, so it's not always clear how much they add to code size and how they impact performance.
- Statistics show that exceptions add 15 to 30% to size of code, even if no exceptions are used (violation of zero-overhead principle);
- Exceptions require Run Time Type Information about types, and have no predictable memory (stack or heap) footprint (violation of zero-overhead principle).
What aurhor suggests might seem too radical but at present it's only viable solution to reestablish zero-verhead principle and to reunite two C++ camps.
Here is the approach.
- Clarify what should be considered as an exception.
- Contract violation.
Are contract violation like invalid values of arguments or invalid post conditions (unhold invariants) are exceptions or programmer's bugs?
If later then it's best to terminate, as you cannot correctly recover from bug.
-
Virtual Machine fault.
What user program can do with stack overflow?
The best according to the author it to terminate.
-
OOM - Out Of Memory error.
What is the best way to deal with OOM dyring dynamic allocation.
At present there are two operators:
new - to allocate memory dynamically and throw bad_alloc on failure.new(nothrow) - to allocate memory dynamically and return nullptr on failure.
Herb Sutter suggests to change new behavior to terminate on failure (it is very hard to properly handle bad_alloc anyway), while new(nothrow) will still allow to build code that can deal with OOM.
- Partial success
This should never be reported as an error, and status codes should be used to report the state.
- Error condition distinct from any type of success.
This is where exceptions should be used.
Statistics shows that
with such separation more than 90% of what curently is an exception will not be exception any more, so no any hidden exception logic is required: program either works or terminates.
- Refactor exception
Redefine what exception object is and how it is propagated.
It should be thin value type. At minimum it needs to contain an error code. Suggested size is up to a couple of pointers.
Compiler should be able to cheaply allocate and copy it on the stack or even in the processor's registers.
Such simple exception type resolves problems with lifetime of exception object, and makes exception handling as light as checking status codes.
Exception should be propagated through return chanel, so it's like a new calling convention that defines either function result or error outcome.
It's not our intention to quote whole the paper here. If you're interested then please read it. Here we want to outline our concerns.
- Exception payload.
This paper emphasizes that exception type should be small.
So, what to do with exception payload, if any (at least error message if it's not a static text)?
If this won't be resolved then developers will start to invent custom mechanisms like GetLastErrorMessage().
And what to do with aggregate exceptions?
We think this must be clearly addressed.
- Implemntation shift.
We can accept that most of the current exceptions will terminate.
But consider now some container that serves requests, like web container or database.
It may be built from multiple components and serve multiple requests concurently. If one request will terminate we don't want for container to terminate.
If terminate handler is called then we cannot rely on state of the application. At least we can expect heap leaks and un-released resources.
So, we either want to be able release heap and other resources per request, or we want to go down with whole process and let OS deal with it.
In the later case we need to design such containers differently: as a set of cooperative processes; OS should allow to spin processes more easily.
- VM with exceptions
There are Virtual Machines that allow exception to be thrown on each instruction (like JVM, or CLI).
You cannot tell in this case that code would never throw exception, as it can out of the blue!
Event in x86 you can have PAGE FAULT on memory access, which can be translated into an exception.
So, it's still a question whether the terminate() solution is sound in every case, and whether compiler can optimize out exception handling if it proves staticlly that no exception should be thrown.
In some code we needed to perform a circular shift of a part of array, like on the following picture:

It's clear what to do, especially in case of one element shift but think about "optimal" algorithm that does minimal number of data movemenents.
Here is what we have came up with in C#: algorithm doing single pass over data.
/// <summary>
/// <para>
/// Moves content of list within open range <code>[start, end)</code>.
/// <code>to</code> should belong to that range.
/// </para>
/// <para>
/// <code>list[start + (to - start + i) mod (end - start)] =
/// list[start + i]</code>,
/// where i in range<code>[0, end - start)</ code >.
/// </para>
/// </summary>
/// <typeparam name="T">An element type.</typeparam>
/// <param name="list">A list to move data withing.</param>
/// <param name="start">Start position, including.</param>
/// <param name="end">End position, not incuding.</param>
/// <param name="to">Target position.</param>
public static void CircularMove<T>(IList<T> list, int start, int end, int to)
{
var size = end - start;
var step = to - start;
var anchor = start;
var pos = start;
var item = list[pos];
for(int i = 0; i < size; ++i)
{
pos += step;
if (pos >= end)
{
pos -= size;
}
var next = list[pos];
list[pos] = item;
item = next;
if (pos == anchor)
{
pos = ++anchor;
if (pos >= end)
{
break;
}
item = list[pos];
}
}
}
We often deal with different SQL DBs, and in particular DB2, Oracle, and SQL Server, and this is what we have found lately.
Our client has reported a problem with SQL insert into the DB2:
- subject table has a small number of columns, but large number of rows;
- insert should attempt to insert a row but tolerate the duplicate.
The prototype table is like this:
create table Link(FromID int, ToID int, primary key(FromID, ToID));
DB2 SQL insert is like this:
insert into Link(FromID, ToID)
values(1, 2)
except
select FromID, ToID from Link;
The idea is to have empty row set to insert if there is a duplicate.
SQL Server variant looks like this:
insert into Link(FromID, ToID)
select 1, 2
except
select FromID, ToID from Link;
Client reported ridiculously slow performance of this SQL, due to table scan to calculate results of except operator.
Out of interest we performed the same experiment with SQL Server, and found the execution plan is optimal, and index seek is used to check duplicates. See:
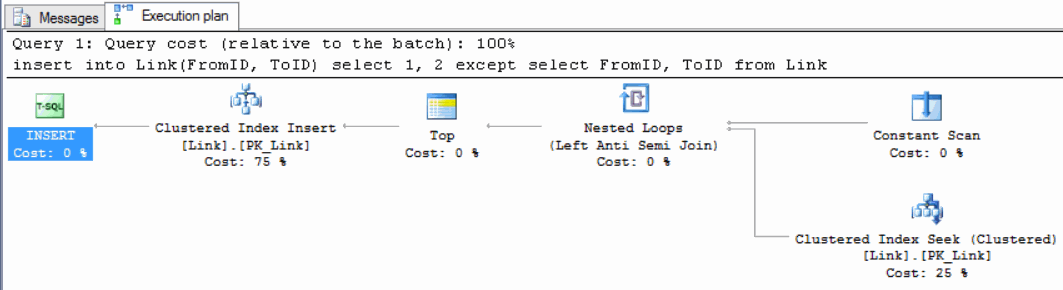
The only reasonable way of dealing with such DB2's peculiarity, except trying to insert and handle duplicate exception, was to qualify select with where clause:
insert into Link(FromID, ToID)
values(1, 2)
except
select FromID, ToID from Link where FromID = 1 and ToID = 2;
We think DB2 could do better.
|